 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSymbolic Autoencoding for Self-Supervised Sequence Learning
Feb 16, 2024Traditional language models, adept at next-token prediction in text sequences, often struggle with transduction tasks between distinct symbolic systems, particularly when parallel data is scarce. Addressing this issue, we introduce \textit{symbolic autoencoding} ($\Sigma$AE), a self-supervised framework that harnesses the power of abundant unparallel data alongside limited parallel data. $\Sigma$AE connects two generative models via a discrete bottleneck layer and is optimized end-to-end by minimizing reconstruction loss (simultaneously with supervised loss for the parallel data), such that the sequence generated by the discrete bottleneck can be read out as the transduced input sequence. We also develop gradient-based methods allowing for efficient self-supervised sequence learning despite the discreteness of the bottleneck. Our results demonstrate that $\Sigma$AE significantly enhances performance on transduction tasks, even with minimal parallel data, offering a promising solution for weakly supervised learning scenarios.
Evaluating Language Model Agency through Negotiations
Jan 09, 2024



Companies, organizations, and governments increasingly exploit Language Models' (LM) remarkable capability to display agent-like behavior. As LMs are adopted to perform tasks with growing autonomy, there exists an urgent need for reliable and scalable evaluation benchmarks. Current, predominantly static LM benchmarks are ill-suited to evaluate such dynamic applications. Thus, we propose jointly evaluating LM performance and alignment through the lenses of negotiation games. We argue that this common task better reflects real-world deployment conditions while offering insights into LMs' decision-making processes. Crucially, negotiation games allow us to study multi-turn, and cross-model interactions, modulate complexity, and side-step accidental data leakage in evaluation. We report results for six publicly accessible LMs from several major providers on a variety of negotiation games, evaluating both self-play and cross-play performance. Noteworthy findings include: (i) open-source models are currently unable to complete these tasks; (ii) cooperative bargaining games prove challenging; and (iii) the most powerful models do not always "win".
A Glitch in the Matrix? Locating and Detecting Language Model Grounding with Fakepedia
Dec 04, 2023



Large language models (LLMs) have demonstrated impressive capabilities in storing and recalling factual knowledge, but also in adapting to novel in-context information. Yet, the mechanisms underlying their in-context grounding remain unknown, especially in situations where in-context information contradicts factual knowledge embedded in the parameters. This is critical for retrieval-augmented generation methods, which enrich the context with up-to-date information, hoping that grounding can rectify the outdated parametric knowledge. In this study, we introduce Fakepedia, a counterfactual dataset designed to evaluate grounding abilities when the parametric knowledge clashes with the in-context information. We benchmark various LLMs with Fakepedia and discover that GPT-4-turbo has a strong preference for its parametric knowledge. Mistral-7B, on the contrary, is the model that most robustly chooses the grounded answer. Then, we conduct causal mediation analysis on LLM components when answering Fakepedia queries. We demonstrate that inspection of the computational graph alone can predict LLM grounding with 92.8% accuracy, especially because few MLPs in the Transformer can predict non-grounded behavior. Our results, together with existing findings about factual recall mechanisms, provide a coherent narrative of how grounding and factual recall mechanisms interact within LLMs.
Fly-Swat or Cannon? Cost-Effective Language Model Choice via Meta-Modeling
Aug 11, 2023



Generative language models (LMs) have become omnipresent across data science. For a wide variety of tasks, inputs can be phrased as natural language prompts for an LM, from whose output the solution can then be extracted. LM performance has consistently been increasing with model size - but so has the monetary cost of querying the ever larger models. Importantly, however, not all inputs are equally hard: some require larger LMs for obtaining a satisfactory solution, whereas for others smaller LMs suffice. Based on this fact, we design a framework for Cost-Effective Language Model Choice (CELMOC). Given a set of inputs and a set of candidate LMs, CELMOC judiciously assigns each input to an LM predicted to do well on the input according to a so-called meta-model, aiming to achieve high overall performance at low cost. The cost-performance trade-off can be flexibly tuned by the user. Options include, among others, maximizing total expected performance (or the number of processed inputs) while staying within a given cost budget, or minimizing total cost while processing all inputs. We evaluate CELMOC on 14 datasets covering five natural language tasks, using four candidate LMs of vastly different size and cost. With CELMOC, we match the performance of the largest available LM while achieving a cost reduction of 63%. Via our publicly available library, researchers as well as practitioners can thus save large amounts of money without sacrificing performance.
Flows: Building Blocks of Reasoning and Collaborating AI
Aug 02, 2023



Recent advances in artificial intelligence (AI) have produced highly capable and controllable systems. This creates unprecedented opportunities for structured reasoning as well as collaboration among multiple AI systems and humans. To fully realize this potential, it is essential to develop a principled way of designing and studying such structured interactions. For this purpose, we introduce the conceptual framework of Flows: a systematic approach to modeling complex interactions. Flows are self-contained building blocks of computation, with an isolated state, communicating through a standardized message-based interface. This modular design allows Flows to be recursively composed into arbitrarily nested interactions, with a substantial reduction of complexity. Crucially, any interaction can be implemented using this framework, including prior work on AI--AI and human--AI interactions, prompt engineering schemes, and tool augmentation. We demonstrate the potential of Flows on the task of competitive coding, a challenging task on which even GPT-4 struggles. Our results suggest that structured reasoning and collaboration substantially improve generalization, with AI-only Flows adding +$21$ and human--AI Flows adding +$54$ absolute points in terms of solve rate. To support rapid and rigorous research, we introduce the aiFlows library. The library comes with a repository of Flows that can be easily used, extended, and composed into novel, more complex Flows. The aiFlows library is available at https://github.com/epfl-dlab/aiflows. Data and Flows for reproducing our experiments are available at https://github.com/epfl-dlab/cc_flows.
Flexible Grammar-Based Constrained Decoding for Language Models
May 24, 2023



LLMs have shown impressive few-shot performance across many tasks. However, they still struggle when it comes to reliably generating complex output structures, such as those required for information extraction. This limitation stems from the fact that LLMs, without fine-tuning, tend to generate free text rather than structures precisely following a specific grammar. In this work, we propose to enrich the decoding with formal grammar constraints. More concretely, given Context-Free Grammar(CFG), our framework ensures that the token generated in each decoding step would lead to a valid continuation compliant with the grammar production rules. This process guarantees the generation of valid sequences. Importantly, our framework can be readily combined with any CFG or decoding algorithm. We demonstrate that the outputs of many NLP tasks can be represented as formal languages, making them suitable for direct use in our framework. We conducted experiments with two challenging tasks involving large alphabets in their grammar (Wikidata entities and relations): information extraction and entity disambiguation. Our results with LLaMA models indicate that grammar-constrained decoding substantially outperforms unconstrained decoding and even competes with task-specific fine-tuned models. These findings suggest that integrating grammar-based constraints during decoding holds great promise in making LLMs reliably produce structured outputs, especially in setting where training data is scarce and fine-tuning is expensive.
REFINER: Reasoning Feedback on Intermediate Representations
Apr 04, 2023Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT3.5 as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
Exploiting Asymmetry for Synthetic Training Data Generation: SynthIE and the Case of Information Extraction
Mar 07, 2023



Large language models (LLMs) show great potential for synthetic data generation. This work shows that useful data can be synthetically generated even for tasks that cannot be solved directly by the LLM: we show that, for problems with structured outputs, it is possible to prompt an LLM to perform the task in the opposite direction, to generate plausible text for the target structure. Leveraging the asymmetry in task difficulty makes it possible to produce large-scale, high-quality data for complex tasks. We demonstrate the effectiveness of this approach on closed information extraction, where collecting ground-truth data is challenging, and no satisfactory dataset exists to date. We synthetically generate a dataset of 1.8M data points, demonstrate its superior quality compared to existing datasets in a human evaluation and use it to finetune small models (220M and 770M parameters). The models we introduce, SynthIE, outperform existing baselines of comparable size with a substantial gap of 57 and 79 absolute points in micro and macro F1, respectively. Code, data, and models are available at https://github.com/epfl-dlab/SynthIE.
Language Model Decoding as Likelihood-Utility Alignment
Oct 13, 2022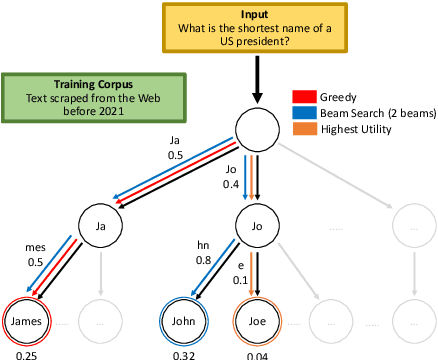

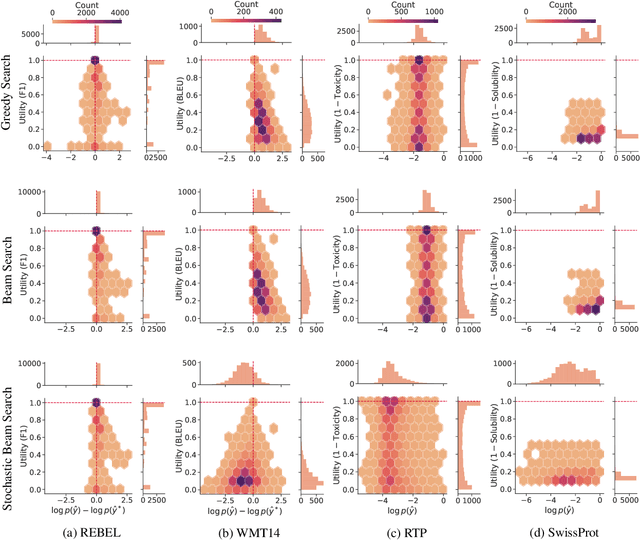
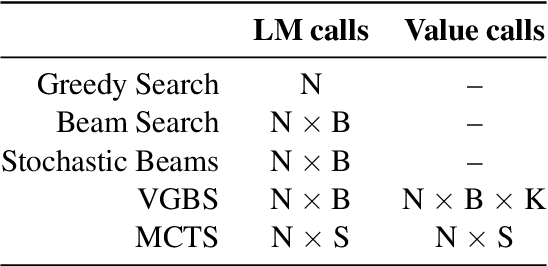
A critical component of a successful language generation pipeline is the decoding algorithm. However, the general principles that should guide the choice of decoding algorithm remain unclear. Previous works only compare decoding algorithms in narrow scenarios and their findings do not generalize across tasks. To better structure the discussion, we introduce a taxonomy that groups decoding strategies based on their implicit assumptions about how well the model's likelihood is aligned with the task-specific notion of utility. We argue that this taxonomy allows a broader view of the decoding problem and can lead to generalizable statements because it is grounded on the interplay between the decoding algorithms and the likelihood-utility misalignment. Specifically, by analyzing the correlation between the likelihood and the utility of predictions across a diverse set of tasks, we provide the first empirical evidence supporting the proposed taxonomy, and a set of principles to structure reasoning when choosing a decoding algorithm. Crucially, our analysis is the first one to relate likelihood-based decoding strategies with strategies that rely on external information such as value-guided methods and prompting, and covers the most diverse set of tasks up-to-date.
Distribution inference risks: Identifying and mitigating sources of leakage
Sep 18, 2022

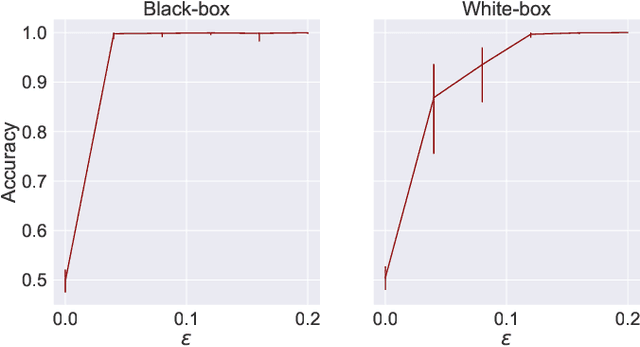
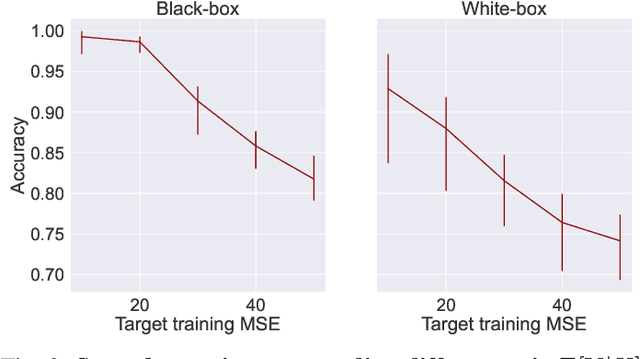
A large body of work shows that machine learning (ML) models can leak sensitive or confidential information about their training data. Recently, leakage due to distribution inference (or property inference) attacks is gaining attention. In this attack, the goal of an adversary is to infer distributional information about the training data. So far, research on distribution inference has focused on demonstrating successful attacks, with little attention given to identifying the potential causes of the leakage and to proposing mitigations. To bridge this gap, as our main contribution, we theoretically and empirically analyze the sources of information leakage that allows an adversary to perpetrate distribution inference attacks. We identify three sources of leakage: (1) memorizing specific information about the $\mathbb{E}[Y|X]$ (expected label given the feature values) of interest to the adversary, (2) wrong inductive bias of the model, and (3) finiteness of the training data. Next, based on our analysis, we propose principled mitigation techniques against distribution inference attacks. Specifically, we demonstrate that causal learning techniques are more resilient to a particular type of distribution inference risk termed distributional membership inference than associative learning methods. And lastly, we present a formalization of distribution inference that allows for reasoning about more general adversaries than was previously possible.