 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Binary Neural Networks
Sep 10, 2018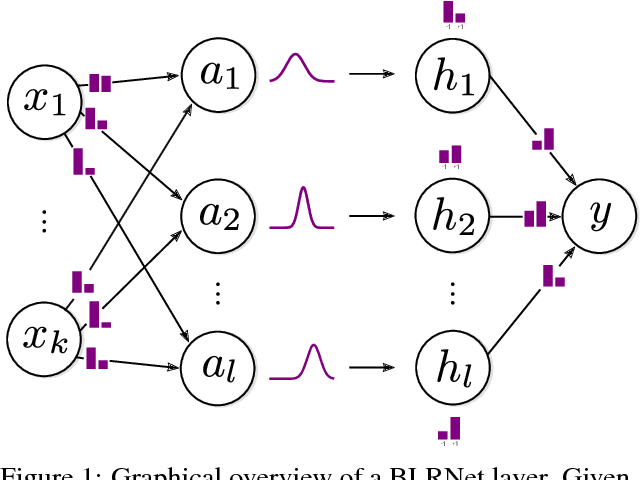
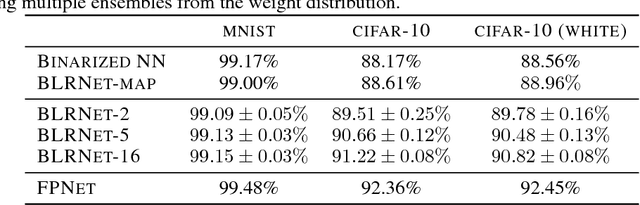
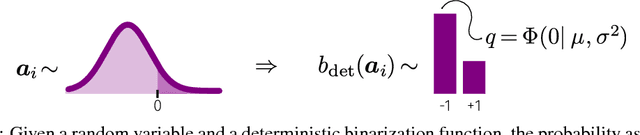
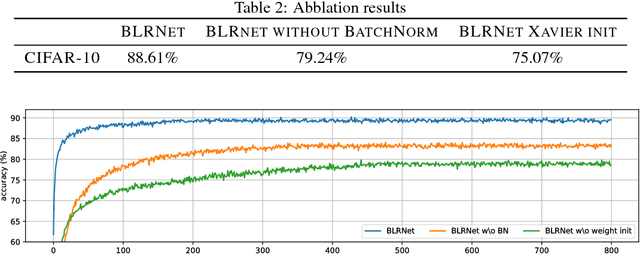
Low bit-width weights and activations are an effective way of combating the increasing need for both memory and compute power of Deep Neural Networks. In this work, we present a probabilistic training method for Neural Network with both binary weights and activations, called BLRNet. By embracing stochasticity during training, we circumvent the need to approximate the gradient of non-differentiable functions such as sign(), while still obtaining a fully Binary Neural Network at test time. Moreover, it allows for anytime ensemble predictions for improved performance and uncertainty estimates by sampling from the weight distribution. Since all operations in a layer of the BLRNet operate on random variables, we introduce stochastic versions of Batch Normalization and max pooling, which transfer well to a deterministic network at test time. We evaluate the BLRNet on multiple standardized benchmarks.
Sample Efficient Semantic Segmentation using Rotation Equivariant Convolutional Networks
Jul 02, 2018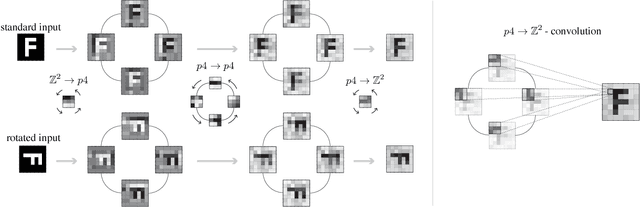
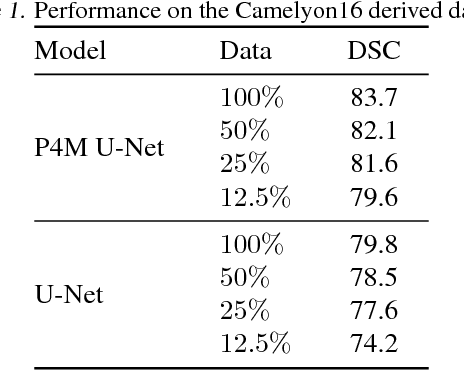
We propose a semantic segmentation model that exploits rotation and reflection symmetries. We demonstrate significant gains in sample efficiency due to increased weight sharing, as well as improvements in robustness to symmetry transformations. The group equivariant CNN framework is extended for segmentation by introducing a new equivariant (G->Z2)-convolution that transforms feature maps on a group to planar feature maps. Also, equivariant transposed convolution is formulated for up-sampling in an encoder-decoder network. To demonstrate improvements in sample efficiency we evaluate on multiple data regimes of a rotation-equivariant segmentation task: cancer metastases detection in histopathology images. We further show the effectiveness of exploiting more symmetries by varying the size of the group.
Attention-based Deep Multiple Instance Learning
Jun 28, 2018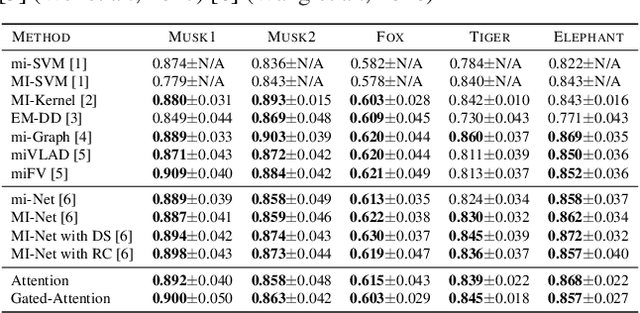
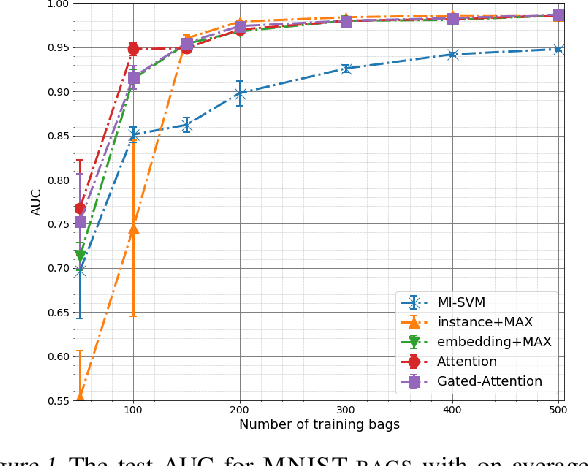
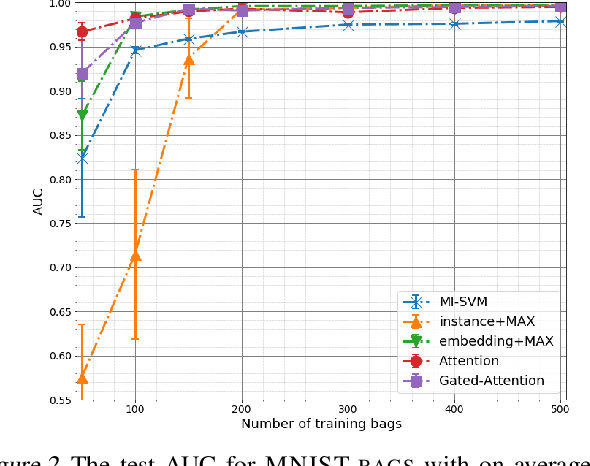

Multiple instance learning (MIL) is a variation of supervised learning where a single class label is assigned to a bag of instances. In this paper, we state the MIL problem as learning the Bernoulli distribution of the bag label where the bag label probability is fully parameterized by neural networks. Furthermore, we propose a neural network-based permutation-invariant aggregation operator that corresponds to the attention mechanism. Notably, an application of the proposed attention-based operator provides insight into the contribution of each instance to the bag label. We show empirically that our approach achieves comparable performance to the best MIL methods on benchmark MIL datasets and it outperforms other methods on a MNIST-based MIL dataset and two real-life histopathology datasets without sacrificing interpretability.
Learning Sparse Neural Networks through $L_0$ Regularization
Jun 22, 2018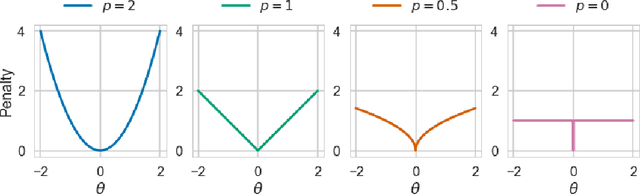
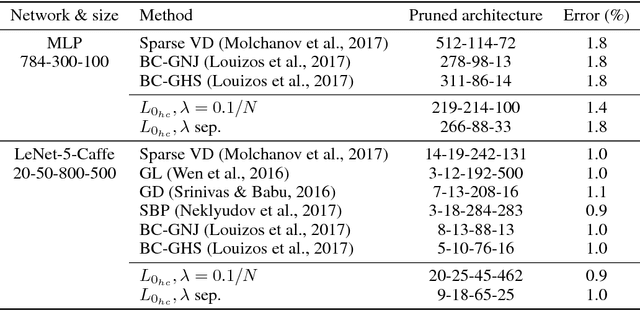
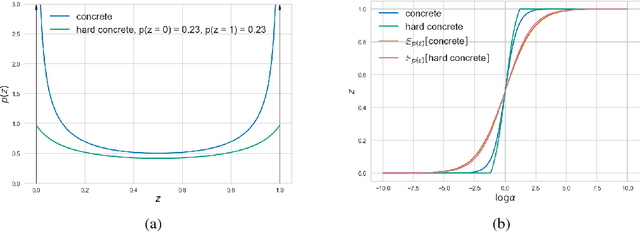
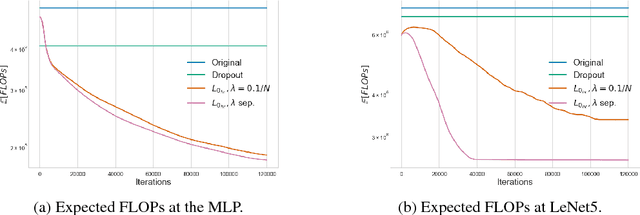
We propose a practical method for $L_0$ norm regularization for neural networks: pruning the network during training by encouraging weights to become exactly zero. Such regularization is interesting since (1) it can greatly speed up training and inference, and (2) it can improve generalization. AIC and BIC, well-known model selection criteria, are special cases of $L_0$ regularization. However, since the $L_0$ norm of weights is non-differentiable, we cannot incorporate it directly as a regularization term in the objective function. We propose a solution through the inclusion of a collection of non-negative stochastic gates, which collectively determine which weights to set to zero. We show that, somewhat surprisingly, for certain distributions over the gates, the expected $L_0$ norm of the resulting gated weights is differentiable with respect to the distribution parameters. We further propose the \emph{hard concrete} distribution for the gates, which is obtained by "stretching" a binary concrete distribution and then transforming its samples with a hard-sigmoid. The parameters of the distribution over the gates can then be jointly optimized with the original network parameters. As a result our method allows for straightforward and efficient learning of model structures with stochastic gradient descent and allows for conditional computation in a principled way. We perform various experiments to demonstrate the effectiveness of the resulting approach and regularizer.
Attention Solves Your TSP, Approximately
Jun 22, 2018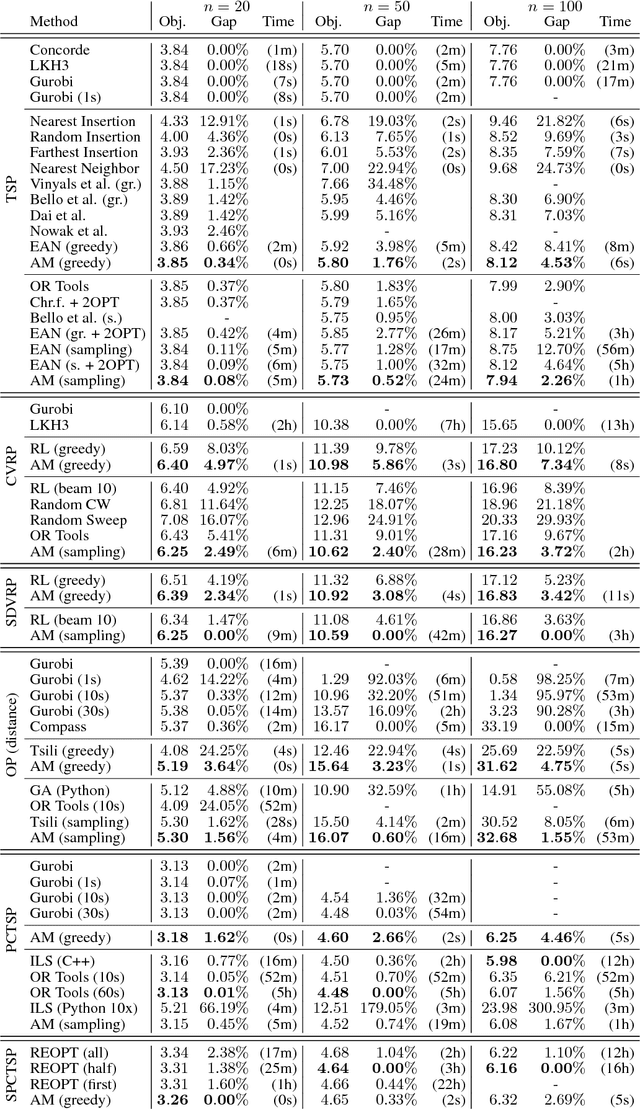
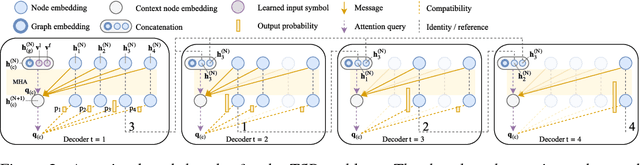
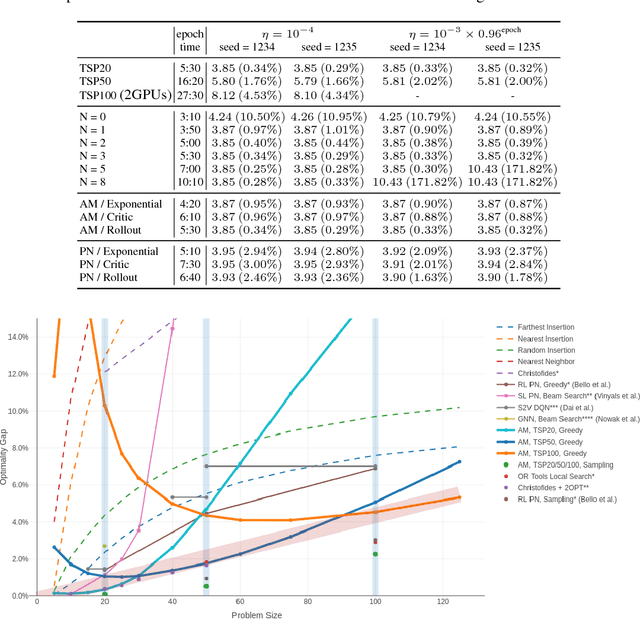
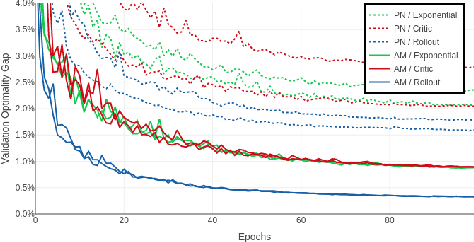
The development of efficient (heuristic) algorithms for practical combinatorial optimization problems is costly, so we want to automatically learn them instead. We show the feasibility of this approach on the important Travelling Salesman Problem (TSP). We learn a heuristic algorithm that uses a Neural Network policy to construct a tour. As an alternative to the Pointer Network, our model is based entirely on (graph) attention layers and is invariant to the input order of the nodes. We train the model efficiently using REINFORCE with a simple and robust baseline based on a deterministic (greedy) rollout of the best policy so far. We significantly improve over results from previous works that consider learned heuristics for the TSP, reducing the optimality gap for a single tour construction from 1.51% to 0.32% for instances with 20 nodes, from 4.59% to 1.71% for 50 nodes and from 6.89% to 4.43% for 100 nodes. Additionally, we improve over a recent Reinforcement Learning framework for two variants of the Vehicle Routing Problem (VRP).
Rotation Equivariant CNNs for Digital Pathology
Jun 08, 2018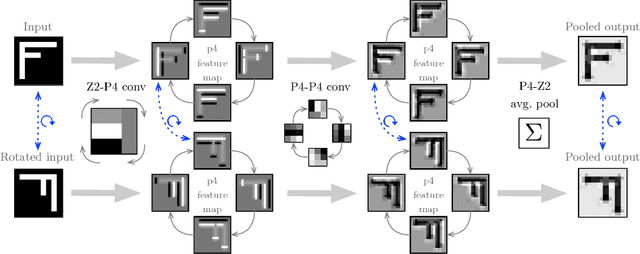
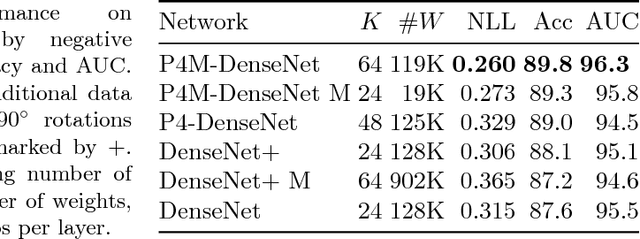
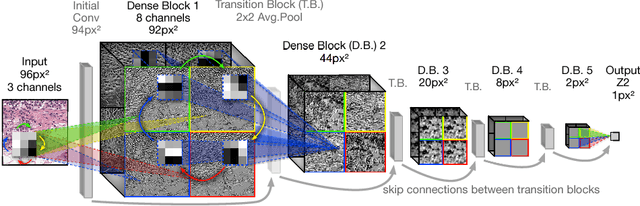
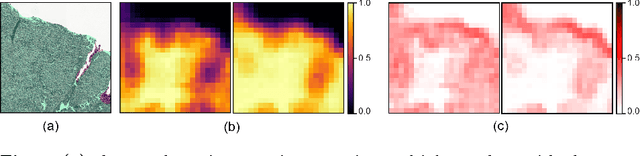
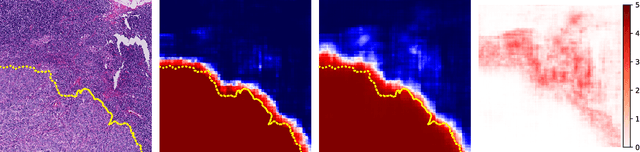
We propose a new model for digital pathology segmentation, based on the observation that histopathology images are inherently symmetric under rotation and reflection. Utilizing recent findings on rotation equivariant CNNs, the proposed model leverages these symmetries in a principled manner. We present a visual analysis showing improved stability on predictions, and demonstrate that exploiting rotation equivariance significantly improves tumor detection performance on a challenging lymph node metastases dataset. We further present a novel derived dataset to enable principled comparison of machine learning models, in combination with an initial benchmark. Through this dataset, the task of histopathology diagnosis becomes accessible as a challenging benchmark for fundamental machine learning research.
Neural Relational Inference for Interacting Systems
Jun 06, 2018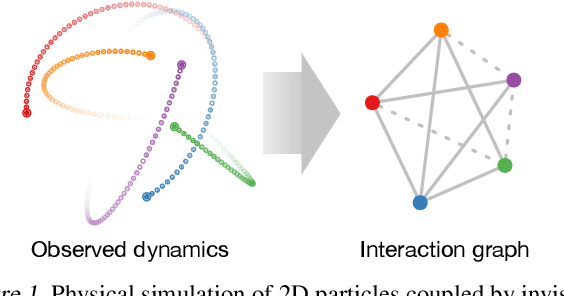
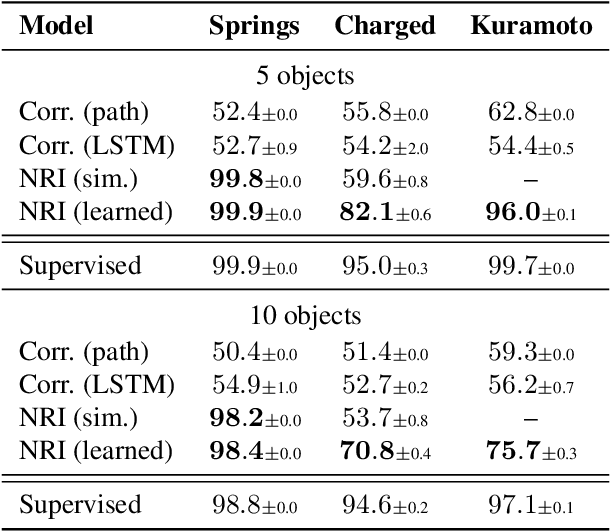
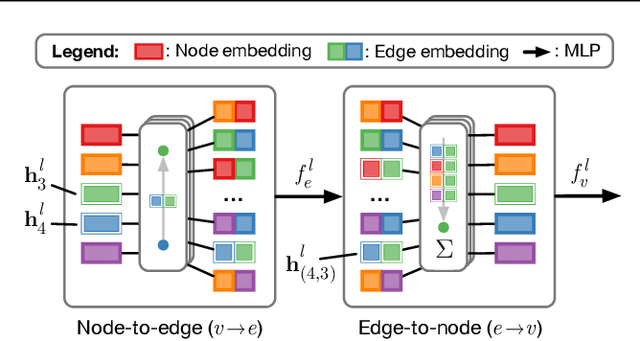
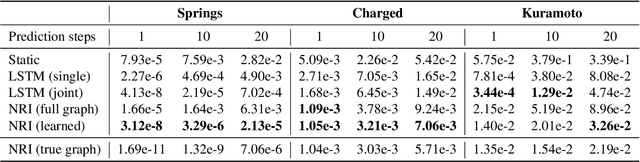
Interacting systems are prevalent in nature, from dynamical systems in physics to complex societal dynamics. The interplay of components can give rise to complex behavior, which can often be explained using a simple model of the system's constituent parts. In this work, we introduce the neural relational inference (NRI) model: an unsupervised model that learns to infer interactions while simultaneously learning the dynamics purely from observational data. Our model takes the form of a variational auto-encoder, in which the latent code represents the underlying interaction graph and the reconstruction is based on graph neural networks. In experiments on simulated physical systems, we show that our NRI model can accurately recover ground-truth interactions in an unsupervised manner. We further demonstrate that we can find an interpretable structure and predict complex dynamics in real motion capture and sports tracking data.
BOCK : Bayesian Optimization with Cylindrical Kernels
Jun 05, 2018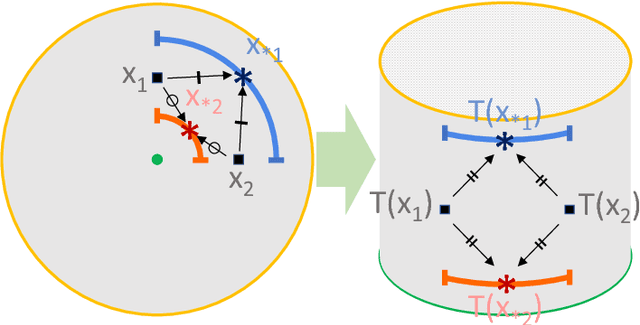
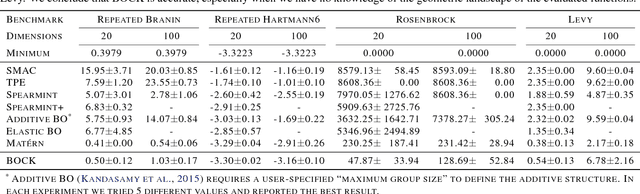
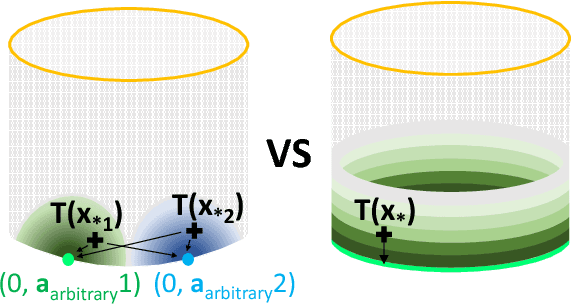
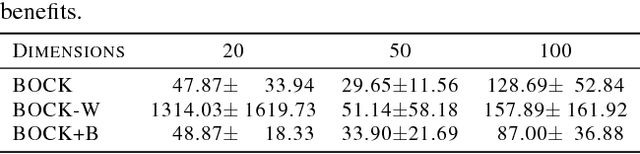
A major challenge in Bayesian Optimization is the boundary issue (Swersky, 2017) where an algorithm spends too many evaluations near the boundary of its search space. In this paper, we propose BOCK, Bayesian Optimization with Cylindrical Kernels, whose basic idea is to transform the ball geometry of the search space using a cylindrical transformation. Because of the transformed geometry, the Gaussian Process-based surrogate model spends less budget searching near the boundary, while concentrating its efforts relatively more near the center of the search region, where we expect the solution to be located. We evaluate BOCK extensively, showing that it is not only more accurate and efficient, but it also scales successfully to problems with a dimensionality as high as 500. We show that the better accuracy and scalability of BOCK even allows optimizing modestly sized neural network layers, as well as neural network hyperparameters.
Primal-Dual Wasserstein GAN
May 24, 2018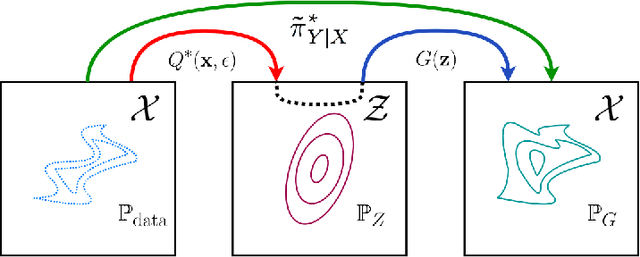
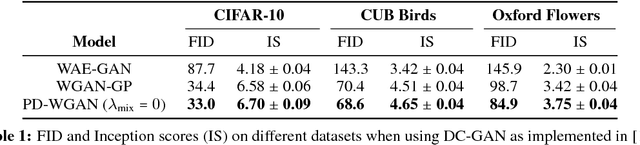
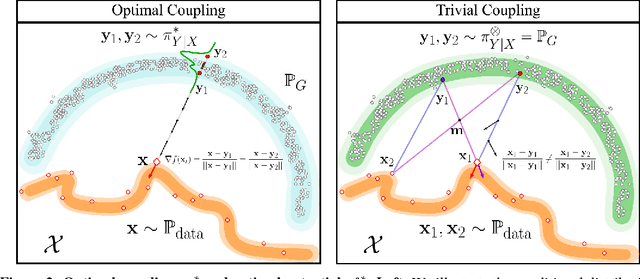
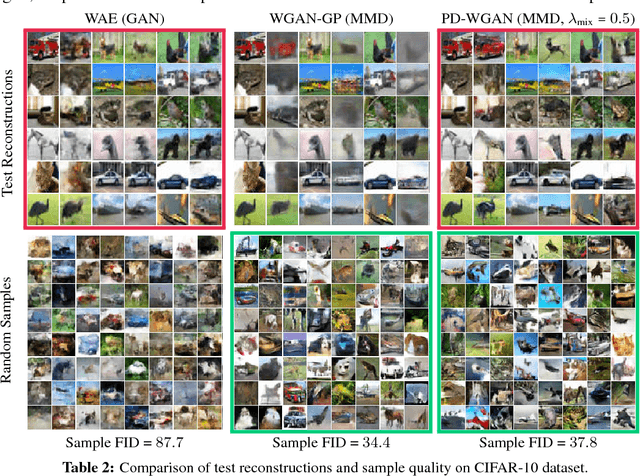
We introduce Primal-Dual Wasserstein GAN, a new learning algorithm for building latent variable models of the data distribution based on the primal and the dual formulations of the optimal transport (OT) problem. We utilize the primal formulation to learn a flexible inference mechanism and to create an optimal approximate coupling between the data distribution and the generative model. In order to learn the generative model, we use the dual formulation and train the decoder adversarially through a critic network that is regularized by the approximate coupling obtained from the primal. Unlike previous methods that violate various properties of the optimal critic, we regularize the norm and the direction of the gradients of the critic function. Our model shares many of the desirable properties of auto-encoding models in terms of mode coverage and latent structure, while avoiding their undesirable averaging properties, e.g. their inability to capture sharp visual features when modeling real images. We compare our algorithm with several other generative modeling techniques that utilize Wasserstein distances on Frechet Inception Distance (FID) and Inception Scores (IS).
Extraction of Airways using Graph Neural Networks
Apr 12, 2018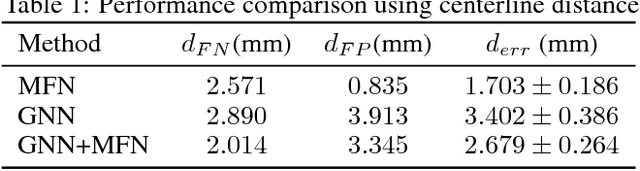
We present extraction of tree structures, such as airways, from image data as a graph refinement task. To this end, we propose a graph auto-encoder model that uses an encoder based on graph neural networks (GNNs) to learn embeddings from input node features and a decoder to predict connections between nodes. Performance of the GNN model is compared with mean-field networks in their ability to extract airways from 3D chest CT scans.