 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the generalization capacity of neural networks during generic multimodal reasoning
Jan 26, 2024The advent of the Transformer has led to the development of large language models (LLM), which appear to demonstrate human-like capabilities. To assess the generality of this class of models and a variety of other base neural network architectures to multimodal domains, we evaluated and compared their capacity for multimodal generalization. We introduce a multimodal question-answer benchmark to evaluate three specific types of out-of-distribution (OOD) generalization performance: distractor generalization (generalization in the presence of distractors), systematic compositional generalization (generalization to new task permutations), and productive compositional generalization (generalization to more complex tasks structures). We found that across model architectures (e.g., RNNs, Transformers, Perceivers, etc.), models with multiple attention layers, or models that leveraged cross-attention mechanisms between input domains, fared better. Our positive results demonstrate that for multimodal distractor and systematic generalization, either cross-modal attention or models with deeper attention layers are key architectural features required to integrate multimodal inputs. On the other hand, neither of these architectural features led to productive generalization, suggesting fundamental limitations of existing architectures for specific types of multimodal generalization. These results demonstrate the strengths and limitations of specific architectural components underlying modern neural models for multimodal reasoning. Finally, we provide Generic COG (gCOG), a configurable benchmark with several multimodal generalization splits, for future studies to explore.
Unraveling the Key Components of OOD Generalization via Diversification
Dec 26, 2023Real-world datasets may contain multiple features that explain the training data equally well, i.e., learning any of them would lead to correct predictions on the training data. However, many of them can be spurious, i.e., lose their predictive power under a distribution shift and fail to generalize to out-of-distribution (OOD) data. Recently developed ``diversification'' methods approach this problem by finding multiple diverse hypotheses that rely on different features. This paper aims to study this class of methods and identify the key components contributing to their OOD generalization abilities. We show that (1) diversification methods are highly sensitive to the distribution of the unlabeled data used for diversification and can underperform significantly when away from a method-specific sweet spot. (2) Diversification alone is insufficient for OOD generalization. The choice of the used learning algorithm, e.g., the model's architecture and pretraining, is crucial, and using the second-best choice leads to an up to 20% absolute drop in accuracy.(3) The optimal choice of learning algorithm depends on the unlabeled data, and vice versa.Finally, we show that the above pitfalls cannot be alleviated by increasing the number of diverse hypotheses, allegedly the major feature of diversification methods. These findings provide a clearer understanding of the critical design factors influencing the OOD generalization of diversification methods. They can guide practitioners in how to use the existing methods best and guide researchers in developing new, better ones.
Risk Assessment and Statistical Significance in the Age of Foundation Models
Oct 11, 2023



We propose a distributional framework for assessing socio-technical risks of foundation models with quantified statistical significance. Our approach hinges on a new statistical relative testing based on first and second order stochastic dominance of real random variables. We show that the second order statistics in this test are linked to mean-risk models commonly used in econometrics and mathematical finance to balance risk and utility when choosing between alternatives. Using this framework, we formally develop a risk-aware approach for foundation model selection given guardrails quantified by specified metrics. Inspired by portfolio optimization and selection theory in mathematical finance, we define a \emph{metrics portfolio} for each model as a means to aggregate a collection of metrics, and perform model selection based on the stochastic dominance of these portfolios. The statistical significance of our tests is backed theoretically by an asymptotic analysis via central limit theorems instantiated in practice via a bootstrap variance estimate. We use our framework to compare various large language models regarding risks related to drifting from instructions and outputting toxic content.
DARE: Towards Robust Text Explanations in Biomedical and Healthcare Applications
Jul 05, 2023



Along with the successful deployment of deep neural networks in several application domains, the need to unravel the black-box nature of these networks has seen a significant increase recently. Several methods have been introduced to provide insight into the inference process of deep neural networks. However, most of these explainability methods have been shown to be brittle in the face of adversarial perturbations of their inputs in the image and generic textual domain. In this work we show that this phenomenon extends to specific and important high stakes domains like biomedical datasets. In particular, we observe that the robustness of explanations should be characterized in terms of the accuracy of the explanation in linking a model's inputs and its decisions - faithfulness - and its relevance from the perspective of domain experts - plausibility. This is crucial to prevent explanations that are inaccurate but still look convincing in the context of the domain at hand. To this end, we show how to adapt current attribution robustness estimation methods to a given domain, so as to take into account domain-specific plausibility. This results in our DomainAdaptiveAREstimator (DARE) attribution robustness estimator, allowing us to properly characterize the domain-specific robustness of faithful explanations. Next, we provide two methods, adversarial training and FAR training, to mitigate the brittleness characterized by DARE, allowing us to train networks that display robust attributions. Finally, we empirically validate our methods with extensive experiments on three established biomedical benchmarks.
Adaptive Conformal Regression with Jackknife+ Rescaled Scores
May 31, 2023



Conformal regression provides prediction intervals with global coverage guarantees, but often fails to capture local error distributions, leading to non-homogeneous coverage. We address this with a new adaptive method based on rescaling conformal scores with an estimate of local score distribution, inspired by the Jackknife+ method, which enables the use of calibration data in conformal scores without breaking calibration-test exchangeability. Our approach ensures formal global coverage guarantees and is supported by new theoretical results on local coverage, including an a posteriori bound on any calibration score. The strength of our approach lies in achieving local coverage without sacrificing calibration set size, improving the applicability of conformal prediction intervals in various settings. As a result, our method provides prediction intervals that outperform previous methods, particularly in the low-data regime, making it especially relevant for real-world applications such as healthcare and biomedical domains where uncertainty needs to be quantified accurately despite low sample data.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Estimating the Adversarial Robustness of Attributions in Text with Transformers
Dec 18, 2022



Explanations are crucial parts of deep neural network (DNN) classifiers. In high stakes applications, faithful and robust explanations are important to understand and gain trust in DNN classifiers. However, recent work has shown that state-of-the-art attribution methods in text classifiers are susceptible to imperceptible adversarial perturbations that alter explanations significantly while maintaining the correct prediction outcome. If undetected, this can critically mislead the users of DNNs. Thus, it is crucial to understand the influence of such adversarial perturbations on the networks' explanations and their perceptibility. In this work, we establish a novel definition of attribution robustness (AR) in text classification, based on Lipschitz continuity. Crucially, it reflects both attribution change induced by adversarial input alterations and perceptibility of such alterations. Moreover, we introduce a wide set of text similarity measures to effectively capture locality between two text samples and imperceptibility of adversarial perturbations in text. We then propose our novel TransformerExplanationAttack (TEA), a strong adversary that provides a tight estimation for attribution robustness in text classification. TEA uses state-of-the-art language models to extract word substitutions that result in fluent, contextual adversarial samples. Finally, with experiments on several text classification architectures, we show that TEA consistently outperforms current state-of-the-art AR estimators, yielding perturbations that alter explanations to a greater extent while being more fluent and less perceptible.
Active Learning for Imbalanced Civil Infrastructure Data
Oct 19, 2022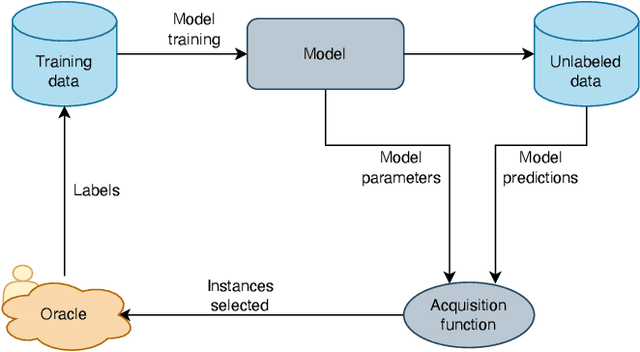


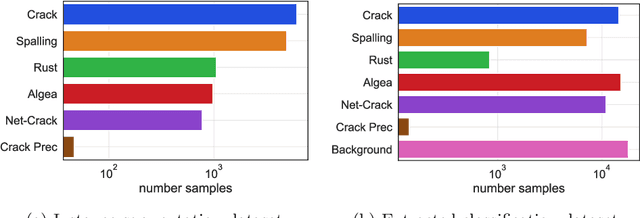
Aging civil infrastructures are closely monitored by engineers for damage and critical defects. As the manual inspection of such large structures is costly and time-consuming, we are working towards fully automating the visual inspections to support the prioritization of maintenance activities. To that end we combine recent advances in drone technology and deep learning. Unfortunately, annotation costs are incredibly high as our proprietary civil engineering dataset must be annotated by highly trained engineers. Active learning is, therefore, a valuable tool to optimize the trade-off between model performance and annotation costs. Our use-case differs from the classical active learning setting as our dataset suffers from heavy class imbalance and consists of a much larger already labeled data pool than other active learning research. We present a novel method capable of operating in this challenging setting by replacing the traditional active learning acquisition function with an auxiliary binary discriminator. We experimentally show that our novel method outperforms the best-performing traditional active learning method (BALD) by 5% and 38% accuracy on CIFAR-10 and our proprietary dataset respectively.
Model-Assisted Labeling via Explainability for Visual Inspection of Civil Infrastructures
Sep 22, 2022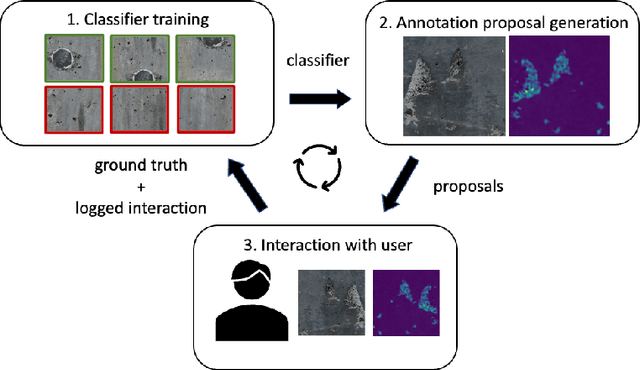
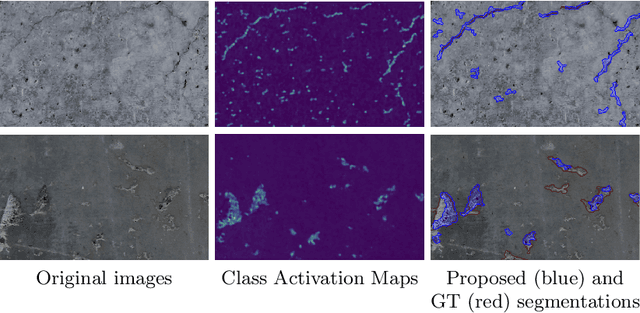
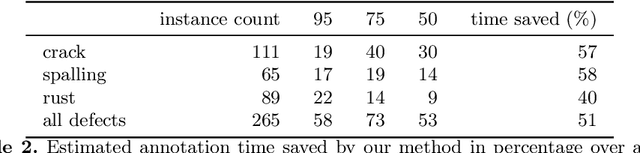
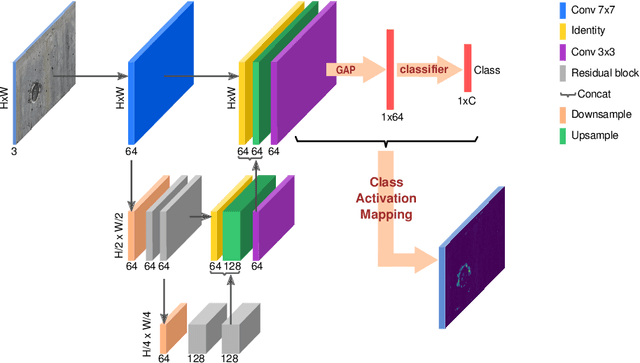
Labeling images for visual segmentation is a time-consuming task which can be costly, particularly in application domains where labels have to be provided by specialized expert annotators, such as civil engineering. In this paper, we propose to use attribution methods to harness the valuable interactions between expert annotators and the data to be annotated in the case of defect segmentation for visual inspection of civil infrastructures. Concretely, a classifier is trained to detect defects and coupled with an attribution-based method and adversarial climbing to generate and refine segmentation masks corresponding to the classification outputs. These are used within an assisted labeling framework where the annotators can interact with them as proposal segmentation masks by deciding to accept, reject or modify them, and interactions are logged as weak labels to further refine the classifier. Applied on a real-world dataset resulting from the automated visual inspection of bridges, our proposed method is able to save more than 50\% of annotators' time when compared to manual annotation of defects.
Cloud-Based Real-Time Molecular Screening Platform with MolFormer
Aug 13, 2022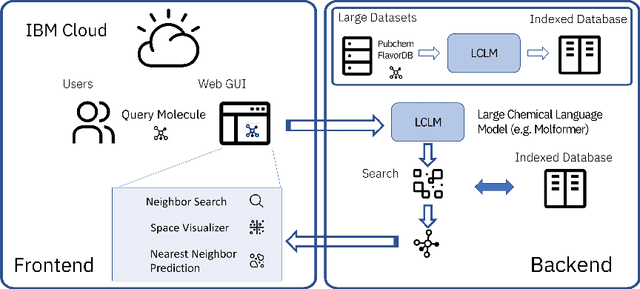
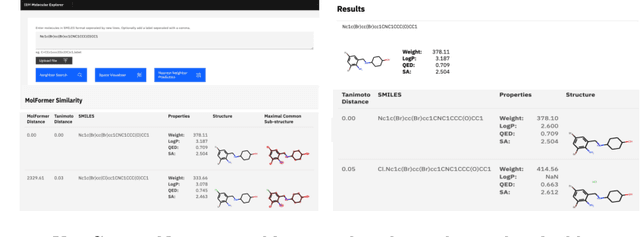
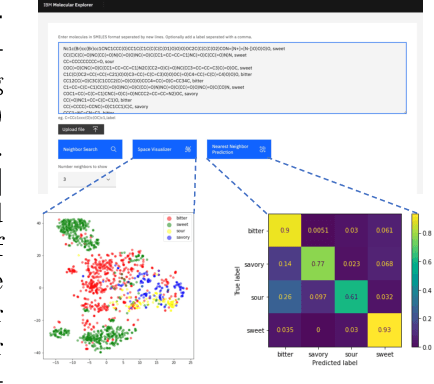
With the prospect of automating a number of chemical tasks with high fidelity, chemical language processing models are emerging at a rapid speed. Here, we present a cloud-based real-time platform that allows users to virtually screen molecules of interest. For this purpose, molecular embeddings inferred from a recently proposed large chemical language model, named MolFormer, are leveraged. The platform currently supports three tasks: nearest neighbor retrieval, chemical space visualization, and property prediction. Based on the functionalities of this platform and results obtained, we believe that such a platform can play a pivotal role in automating chemistry and chemical engineering research, as well as assist in drug discovery and material design tasks. A demo of our platform is provided at \url{www.ibm.biz/molecular_demo}.