 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTarget Speaker ASR with Whisper
Sep 14, 2024We propose a novel approach to enable the use of large, single speaker ASR models, such as Whisper, for target speaker ASR. The key insight of this method is that it is much easier to model relative differences among speakers by learning to condition on frame-level diarization outputs, than to learn the space of all speaker embeddings. We find that adding even a single bias term per diarization output type before the first transformer block can transform single speaker ASR models, into target speaker ASR models. Our target-speaker ASR model can be used for speaker attributed ASR by producing, in sequence, a transcript for each hypothesized speaker in a diarization output. This simplified model for speaker attributed ASR using only a single microphone outperforms cascades of speech separation and diarization by 11% absolute ORC-WER on the NOTSOFAR-1 dataset.
Privacy versus Emotion Preservation Trade-offs in Emotion-Preserving Speaker Anonymization
Sep 05, 2024Advances in speech technology now allow unprecedented access to personally identifiable information through speech. To protect such information, the differential privacy field has explored ways to anonymize speech while preserving its utility, including linguistic and paralinguistic aspects. However, anonymizing speech while maintaining emotional state remains challenging. We explore this problem in the context of the VoicePrivacy 2024 challenge. Specifically, we developed various speaker anonymization pipelines and find that approaches either excel at anonymization or preserving emotion state, but not both simultaneously. Achieving both would require an in-domain emotion recognizer. Additionally, we found that it is feasible to train a semi-effective speaker verification system using only emotion representations, demonstrating the challenge of separating these two modalities.
The CHiME-8 DASR Challenge for Generalizable and Array Agnostic Distant Automatic Speech Recognition and Diarization
Jul 23, 2024



This paper presents the CHiME-8 DASR challenge which carries on from the previous edition CHiME-7 DASR (C7DASR) and the past CHiME-6 challenge. It focuses on joint multi-channel distant speech recognition (DASR) and diarization with one or more, possibly heterogeneous, devices. The main goal is to spur research towards meeting transcription approaches that can generalize across arbitrary number of speakers, diverse settings (formal vs. informal conversations), meeting duration, wide-variety of acoustic scenarios and different recording configurations. Novelties with respect to C7DASR include: i) the addition of NOTSOFAR-1, an additional office/corporate meeting scenario, ii) a manually corrected Mixer 6 development set, iii) a new track in which we allow the use of large-language models (LLM) iv) a jury award mechanism to encourage participants to explore also more practical and innovative solutions. To lower the entry barrier for participants, we provide a standalone toolkit for downloading and preparing such datasets as well as performing text normalization and scoring their submissions. Furthermore, this year we also provide two baseline systems, one directly inherited from C7DASR and based on ESPnet and another one developed on NeMo and based on NeMo team submission in last year C7DASR. Baseline system results suggest that the addition of the NOTSOFAR-1 scenario significantly increases the task's difficulty due to its high number of speakers and very short duration.
On Speaker Attribution with SURT
Jan 28, 2024



The Streaming Unmixing and Recognition Transducer (SURT) has recently become a popular framework for continuous, streaming, multi-talker speech recognition (ASR). With advances in architecture, objectives, and mixture simulation methods, it was demonstrated that SURT can be an efficient streaming method for speaker-agnostic transcription of real meetings. In this work, we push this framework further by proposing methods to perform speaker-attributed transcription with SURT, for both short mixtures and long recordings. We achieve this by adding an auxiliary speaker branch to SURT, and synchronizing its label prediction with ASR token prediction through HAT-style blank factorization. In order to ensure consistency in relative speaker labels across different utterance groups in a recording, we propose "speaker prefixing" -- appending each chunk with high-confidence frames of speakers identified in previous chunks, to establish the relative order. We perform extensive ablation experiments on synthetic LibriSpeech mixtures to validate our design choices, and demonstrate the efficacy of our final model on the AMI corpus.
Speech collage: code-switched audio generation by collaging monolingual corpora
Sep 27, 2023



Designing effective automatic speech recognition (ASR) systems for Code-Switching (CS) often depends on the availability of the transcribed CS resources. To address data scarcity, this paper introduces Speech Collage, a method that synthesizes CS data from monolingual corpora by splicing audio segments. We further improve the smoothness quality of audio generation using an overlap-add approach. We investigate the impact of generated data on speech recognition in two scenarios: using in-domain CS text and a zero-shot approach with synthesized CS text. Empirical results highlight up to 34.4% and 16.2% relative reductions in Mixed-Error Rate and Word-Error Rate for in-domain and zero-shot scenarios, respectively. Lastly, we demonstrate that CS augmentation bolsters the model's code-switching inclination and reduces its monolingual bias.
The CHiME-7 DASR Challenge: Distant Meeting Transcription with Multiple Devices in Diverse Scenarios
Jul 14, 2023



The CHiME challenges have played a significant role in the development and evaluation of robust automatic speech recognition (ASR) systems. We introduce the CHiME-7 distant ASR (DASR) task, within the 7th CHiME challenge. This task comprises joint ASR and diarization in far-field settings with multiple, and possibly heterogeneous, recording devices. Different from previous challenges, we evaluate systems on 3 diverse scenarios: CHiME-6, DiPCo, and Mixer 6. The goal is for participants to devise a single system that can generalize across different array geometries and use cases with no a-priori information. Another departure from earlier CHiME iterations is that participants are allowed to use open-source pre-trained models and datasets. In this paper, we describe the challenge design, motivation, and fundamental research questions in detail. We also present the baseline system, which is fully array-topology agnostic and features multi-channel diarization, channel selection, guided source separation and a robust ASR model that leverages self-supervised speech representations (SSLR).
HK-LegiCoST: Leveraging Non-Verbatim Transcripts for Speech Translation
Jun 20, 2023We introduce HK-LegiCoST, a new three-way parallel corpus of Cantonese-English translations, containing 600+ hours of Cantonese audio, its standard traditional Chinese transcript, and English translation, segmented and aligned at the sentence level. We describe the notable challenges in corpus preparation: segmentation, alignment of long audio recordings, and sentence-level alignment with non-verbatim transcripts. Such transcripts make the corpus suitable for speech translation research when there are significant differences between the spoken and written forms of the source language. Due to its large size, we are able to demonstrate competitive speech translation baselines on HK-LegiCoST and extend them to promising cross-corpus results on the FLEURS Cantonese subset. These results deliver insights into speech recognition and translation research in languages for which non-verbatim or ``noisy'' transcription is common due to various factors, including vernacular and dialectal speech.
Bypass Temporal Classification: Weakly Supervised Automatic Speech Recognition with Imperfect Transcripts
Jun 01, 2023



This paper presents a novel algorithm for building an automatic speech recognition (ASR) model with imperfect training data. Imperfectly transcribed speech is a prevalent issue in human-annotated speech corpora, which degrades the performance of ASR models. To address this problem, we propose Bypass Temporal Classification (BTC) as an expansion of the Connectionist Temporal Classification (CTC) criterion. BTC explicitly encodes the uncertainties associated with transcripts during training. This is accomplished by enhancing the flexibility of the training graph, which is implemented as a weighted finite-state transducer (WFST) composition. The proposed algorithm improves the robustness and accuracy of ASR systems, particularly when working with imprecisely transcribed speech corpora. Our implementation will be open-sourced.
Towards Zero-Shot Code-Switched Speech Recognition
Nov 09, 2022



In this work, we seek to build effective code-switched (CS) automatic speech recognition systems (ASR) under the zero-shot setting where no transcribed CS speech data is available for training. Previously proposed frameworks which conditionally factorize the bilingual task into its constituent monolingual parts are a promising starting point for leveraging monolingual data efficiently. However, these methods require the monolingual modules to perform language segmentation. That is, each monolingual module has to simultaneously detect CS points and transcribe speech segments of one language while ignoring those of other languages -- not a trivial task. We propose to simplify each monolingual module by allowing them to transcribe all speech segments indiscriminately with a monolingual script (i.e. transliteration). This simple modification passes the responsibility of CS point detection to subsequent bilingual modules which determine the final output by considering multiple monolingual transliterations along with external language model information. We apply this transliteration-based approach in an end-to-end differentiable neural network and demonstrate its efficacy for zero-shot CS ASR on Mandarin-English SEAME test sets.
Injecting Text and Cross-lingual Supervision in Few-shot Learning from Self-Supervised Models
Oct 10, 2021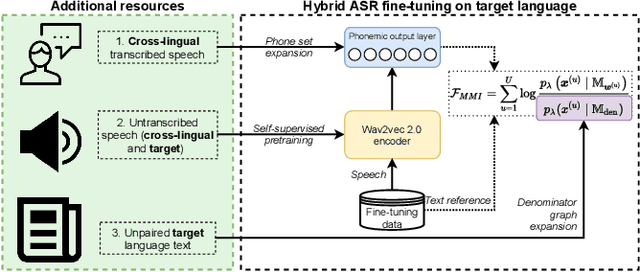

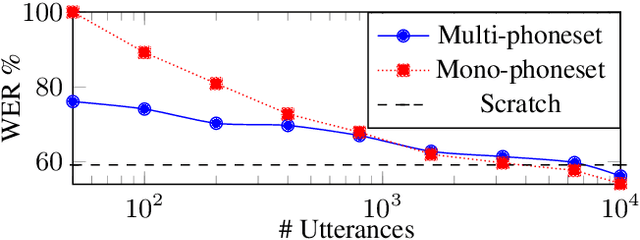
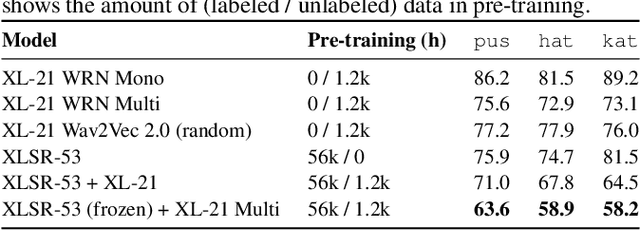
Self-supervised model pre-training has recently garnered significant interest, but relatively few efforts have explored using additional resources in fine-tuning these models. We demonstrate how universal phoneset acoustic models can leverage cross-lingual supervision to improve transfer of pretrained self-supervised representations to new languages. We also show how target-language text can be used to enable and improve fine-tuning with the lattice-free maximum mutual information (LF-MMI) objective. In three low-resource languages these techniques greatly improved few-shot learning performance.