 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModular Prompt Optimization: Optimizing Structured Prompts with Section-Local Textual Gradients
Jan 07, 2026Prompt quality plays a central role in controlling the behavior, reliability, and reasoning performance of large language models (LLMs), particularly for smaller open-source instruction-tuned models that depend heavily on explicit structure. While recent work has explored automatic prompt optimization using textual gradients and self-refinement, most existing methods treat prompts as monolithic blocks of text, making it difficult to localize errors, preserve critical instructions, or prevent uncontrolled prompt growth. We introduce Modular Prompt Optimization (MPO), a schema-based prompt optimization framework that treats prompts as structured objects composed of fixed semantic sections, including system role, context, task description, constraints, and output format. MPO applies section-local textual gradients, generated by a critic language model, to refine each section independently while keeping the overall prompt schema fixed. Section updates are consolidated through de-duplication to reduce redundancy and interference between components, yielding an interpretable and robust optimization process. We evaluate MPO on two reasoning benchmarks, ARC-Challenge and MMLU, using LLaMA-3 8B-Instruct and Mistral-7B-Instruct as solver models. Across both benchmarks and models, MPO consistently outperforms an untuned structured prompt and the TextGrad baseline, achieving substantial accuracy gains without modifying model parameters or altering prompt structure. These results demonstrate that maintaining a fixed prompt schema while applying localized, section-wise optimization is an effective and practical approach for improving reasoning performance in small open-source LMs.
Exploring the Design Space of Cognitive Engagement Techniques with AI-Generated Code for Enhanced Learning
Oct 11, 2024



Novice programmers are increasingly relying on Large Language Models (LLMs) to generate code for learning programming concepts. However, this interaction can lead to superficial engagement, giving learners an illusion of learning and hindering skill development. To address this issue, we conducted a systematic design exploration to develop seven cognitive engagement techniques aimed at promoting deeper engagement with AI-generated code. In this paper, we describe our design process, the initial seven techniques and results from a between-subjects study (N=82). We then iteratively refined the top techniques and further evaluated them through a within-subjects study (N=42). We evaluate the friction each technique introduces, their effectiveness in helping learners apply concepts to isomorphic tasks without AI assistance, and their success in aligning learners' perceived and actual coding abilities. Ultimately, our results highlight the most effective technique: guiding learners through the step-by-step problem-solving process, where they engage in an interactive dialog with the AI, prompting what needs to be done at each stage before the corresponding code is revealed.
CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs
Jan 20, 2024



Timely, personalized feedback is essential for students learning programming, especially as class sizes expand. LLM-based tools like ChatGPT offer instant support, but reveal direct answers with code, which may hinder deep conceptual engagement. We developed CodeAid, an LLM-based programming assistant delivering helpful, technically correct responses, without revealing code solutions. For example, CodeAid can answer conceptual questions, generate pseudo-code with line-by-line explanations, and annotate student's incorrect code with fix suggestions. We deployed CodeAid in a programming class of 700 students for a 12-week semester. A thematic analysis of 8,000 usages of CodeAid was performed, further enriched by weekly surveys, and 22 student interviews. We then interviewed eight programming educators to gain further insights on CodeAid. Findings revealed students primarily used CodeAid for conceptual understanding and debugging, although a minority tried to obtain direct code. Educators appreciated CodeAid's educational approach, and expressed concerns about occasional incorrect feedback and students defaulting to ChatGPT.
Extracting Meaningful Attention on Source Code: An Empirical Study of Developer and Neural Model Code Exploration
Oct 11, 2022
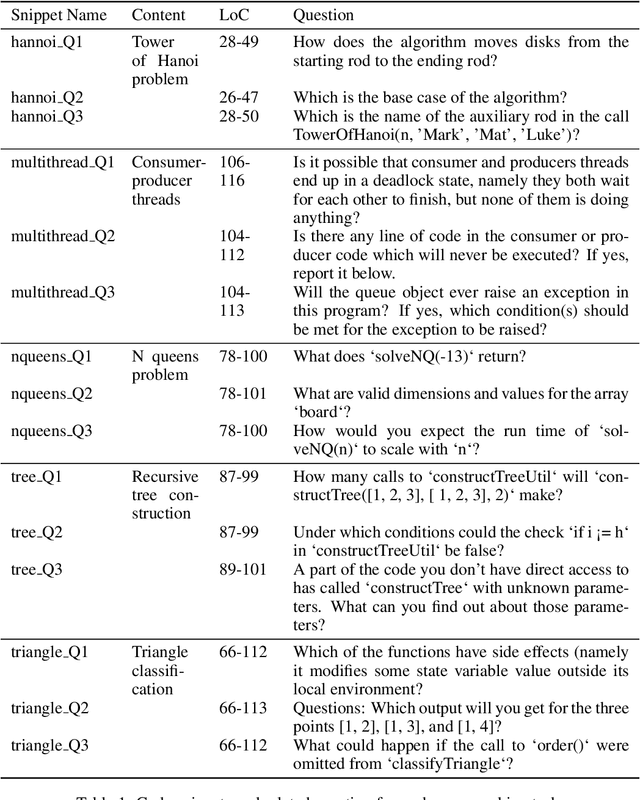
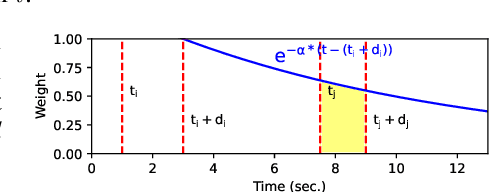
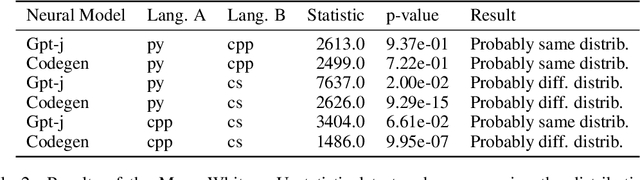
The high effectiveness of neural models of code, such as OpenAI Codex and AlphaCode, suggests coding capabilities of models that are at least comparable to those of humans. However, previous work has only used these models for their raw completion, ignoring how the model reasoning, in the form of attention weights, can be used for other downstream tasks. Disregarding the attention weights means discarding a considerable portion of what those models compute when queried. To profit more from the knowledge embedded in these large pre-trained models, this work compares multiple approaches to post-process these valuable attention weights for supporting code exploration. Specifically, we compare to which extent the transformed attention signal of CodeGen, a large and publicly available pretrained neural model, agrees with how developers look at and explore code when each answering the same sense-making questions about code. At the core of our experimental evaluation, we collect, manually annotate, and open-source a novel eye-tracking dataset comprising 25 developers answering sense-making questions on code over 92 sessions. We empirically evaluate five attention-agnostic heuristics and ten attention-based post processing approaches of the attention signal against our ground truth of developers exploring code, including the novel concept of follow-up attention which exhibits the highest agreement. Beyond the dataset contribution and the empirical study, we also introduce a novel practical application of the attention signal of pre-trained models with completely analytical solutions, going beyond how neural models' attention mechanisms have traditionally been used.