 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProdCodeBench: A Production-Derived Benchmark for Evaluating AI Coding Agents
Apr 02, 2026Benchmarks that reflect production workloads are better for evaluating AI coding agents in industrial settings, yet existing benchmarks differ from real usage in programming language distribution, prompt style and codebase structure. This paper presents a methodology for curating production-derived benchmarks, illustrated through ProdCodeBench - a benchmark built from real sessions with a production AI coding assistant. We detail our data collection and curation practices including LLM-based task classification, test relevance validation, and multi-run stability checks which address challenges in constructing reliable evaluation signals from monorepo environments. Each curated sample consists of a verbatim prompt, a committed code change and fail-to-pass tests spanning seven programming languages. Our systematic analysis of four foundation models yields solve rates from 53.2% to 72.2% revealing that models making greater use of work validation tools, such as executing tests and invoking static analysis, achieve higher solve rates. This suggests that iterative verification helps achieve effective agent behavior and that exposing codebase-specific verification mechanisms may significantly improve the performance of externally trained agents operating in unfamiliar environments. We share our methodology and lessons learned to enable other organizations to construct similar production-derived benchmarks.
Agentic Code Reasoning
Mar 04, 2026Can LLM agents explore codebases and reason about code semantics without executing the code? We study this capability, which we call agentic code reasoning, and introduce semi-formal reasoning: a structured prompting methodology that requires agents to construct explicit premises, trace execution paths, and derive formal conclusions. Unlike unstructured chain-of-thought, semi-formal reasoning acts as a certificate: the agent cannot skip cases or make unsupported claims. We evaluate across three tasks (patch equivalence verification, fault localization, and code question answering) and show that semi-formal reasoning consistently improves accuracy on all of them. For patch equivalence, accuracy improves from 78% to 88% on curated examples and reaches 93% on real-world agent-generated patches, approaching the reliability needed for execution-free RL reward signals. For code question answering on RubberDuckBench Mohammad et al. (2026), semi-formal reasoning achieves 87% accuracy. For fault localization on Defects4J Just et al. (2014), semi-formal reasoning improves Top-5 accuracy by 5 percentage points over standard reasoning. These results demonstrate that structured agentic reasoning enables meaningful semantic code analysis without execution, opening practical applications in RL training pipelines, code review, and static program analysis.
Wink: Recovering from Misbehaviors in Coding Agents
Feb 19, 2026Autonomous coding agents, powered by large language models (LLMs), are increasingly being adopted in the software industry to automate complex engineering tasks. However, these agents are prone to a wide range of misbehaviors, such as deviating from the user's instructions, getting stuck in repetitive loops, or failing to use tools correctly. These failures disrupt the development workflow and often require resource-intensive manual intervention. In this paper, we present a system for automatically recovering from agentic misbehaviors at scale. We first introduce a taxonomy of misbehaviors grounded in an analysis of production traffic, identifying three primary categories: Specification Drift, Reasoning Problems, and Tool Call Failures, which we find occur in about 30% of all agent trajectories. To address these issues, we developed a lightweight, asynchronous self-intervention system named Wink. Wink observes agent trajectories and provides targeted course-correction guidance to nudge the agent back to a productive path. We evaluated our system on over 10,000 real world agent trajectories and found that it successfully resolves 90% of the misbehaviors that require a single intervention. Furthermore, a live A/B test in our production environment demonstrated that our system leads to a statistically significant reduction in Tool Call Failures, Tokens per Session and Engineer Interventions per Session. We present our experience designing and deploying this system, offering insights into the challenges of building resilient agentic systems at scale.
Towards Verified Code Reasoning by LLMs
Sep 30, 2025



While LLM-based agents are able to tackle a wide variety of code reasoning questions, the answers are not always correct. This prevents the agent from being useful in situations where high precision is desired: (1) helping a software engineer understand a new code base, (2) helping a software engineer during code review sessions, and (3) ensuring that the code generated by an automated code generation system meets certain requirements (e.g. fixes a bug, improves readability, implements a feature). As a result of this lack of trustworthiness, the agent's answers need to be manually verified before they can be trusted. Manually confirming responses from a code reasoning agent requires human effort and can result in slower developer productivity, which weakens the assistance benefits of the agent. In this paper, we describe a method to automatically validate the answers provided by a code reasoning agent by verifying its reasoning steps. At a very high level, the method consists of extracting a formal representation of the agent's response and, subsequently, using formal verification and program analysis tools to verify the agent's reasoning steps. We applied this approach to a benchmark set of 20 uninitialized variable errors detected by sanitizers and 20 program equivalence queries. For the uninitialized variable errors, the formal verification step was able to validate the agent's reasoning on 13/20 examples, and for the program equivalence queries, the formal verification step successfully caught 6/8 incorrect judgments made by the agent.
Prompting LLMs for Code Editing: Struggles and Remedies
Apr 28, 2025



Large Language Models (LLMs) are rapidly transforming software engineering, with coding assistants embedded in an IDE becoming increasingly prevalent. While research has focused on improving the tools and understanding developer perceptions, a critical gap exists in understanding how developers actually use these tools in their daily workflows, and, crucially, where they struggle. This paper addresses part of this gap through a multi-phased investigation of developer interactions with an LLM-powered code editing and transformation feature, Transform Code, in an IDE widely used at Google. First, we analyze telemetry logs of the feature usage, revealing that frequent re-prompting can be an indicator of developer struggles with using Transform Code. Second, we conduct a qualitative analysis of unsatisfactory requests, identifying five key categories of information often missing from developer prompts. Finally, based on these findings, we propose and evaluate a tool, AutoPrompter, for automatically improving prompts by inferring missing information from the surrounding code context, leading to a 27% improvement in edit correctness on our test set.
Agentic Bug Reproduction for Effective Automated Program Repair at Google
Feb 03, 2025



Bug reports often lack sufficient detail for developers to reproduce and fix the underlying defects. Bug Reproduction Tests (BRTs), tests that fail when the bug is present and pass when it has been resolved, are crucial for debugging, but they are rarely included in bug reports, both in open-source and in industrial settings. Thus, automatically generating BRTs from bug reports has the potential to accelerate the debugging process and lower time to repair. This paper investigates automated BRT generation within an industry setting, specifically at Google, focusing on the challenges of a large-scale, proprietary codebase and considering real-world industry bugs extracted from Google's internal issue tracker. We adapt and evaluate a state-of-the-art BRT generation technique, LIBRO, and present our agent-based approach, BRT Agent, which makes use of a fine-tuned Large Language Model (LLM) for code editing. Our BRT Agent significantly outperforms LIBRO, achieving a 28% plausible BRT generation rate, compared to 10% by LIBRO, on 80 human-reported bugs from Google's internal issue tracker. We further investigate the practical value of generated BRTs by integrating them with an Automated Program Repair (APR) system at Google. Our results show that providing BRTs to the APR system results in 30% more bugs with plausible fixes. Additionally, we introduce Ensemble Pass Rate (EPR), a metric which leverages the generated BRTs to select the most promising fixes from all fixes generated by APR system. Our evaluation on EPR for Top-K and threshold-based fix selections demonstrates promising results and trade-offs. For example, EPR correctly selects a plausible fix from a pool of 20 candidates in 70% of cases, based on its top-1 ranking.
Evaluating Agent-based Program Repair at Google
Jan 13, 2025



Agent-based program repair offers to automatically resolve complex bugs end-to-end by combining the planning, tool use, and code generation abilities of modern LLMs. Recent work has explored the use of agent-based repair approaches on the popular open-source SWE-Bench, a collection of bugs from highly-rated GitHub Python projects. In addition, various agentic approaches such as SWE-Agent have been proposed to solve bugs in this benchmark. This paper explores the viability of using an agentic approach to address bugs in an enterprise context. To investigate this, we curate an evaluation set of 178 bugs drawn from Google's issue tracking system. This dataset spans both human-reported (78) and machine-reported bugs (100). To establish a repair performance baseline on this benchmark, we implement Passerine, an agent similar in spirit to SWE-Agent that can work within Google's development environment. We show that with 20 trajectory samples and Gemini 1.5 Pro, Passerine can produce a patch that passes bug tests (i.e., plausible) for 73% of machine-reported and 25.6% of human-reported bugs in our evaluation set. After manual examination, we found that 43% of machine-reported bugs and 17.9% of human-reported bugs have at least one patch that is semantically equivalent to the ground-truth patch. These results establish a baseline on an industrially relevant benchmark, which as we show, contains bugs drawn from a different distribution -- in terms of language diversity, size, and spread of changes, etc. -- compared to those in the popular SWE-Bench dataset.
Natural Language Outlines for Code: Literate Programming in the LLM Era
Aug 09, 2024



We propose using natural language outlines as a novel modality and interaction surface for providing AI assistance to developers throughout the software development process. An NL outline for a code function comprises multiple statements written in concise prose, which partition the code and summarize its main ideas in the style of literate programming. Crucially, we find that modern LLMs can generate accurate and high-quality NL outlines in practice. Moreover, NL outlines enable a bidirectional sync between code and NL, allowing changes in one to be automatically reflected in the other. We discuss many use cases for NL outlines: they can accelerate understanding and navigation of code and diffs, simplify code maintenance, augment code search, steer code generation, and more. We then propose and compare multiple LLM prompting techniques for generating outlines and ask professional developers to judge outline quality. Finally, we present two case studies applying NL outlines toward code review and the difficult task of malware detection.
Counterfactual Explanations for Models of Code
Nov 10, 2021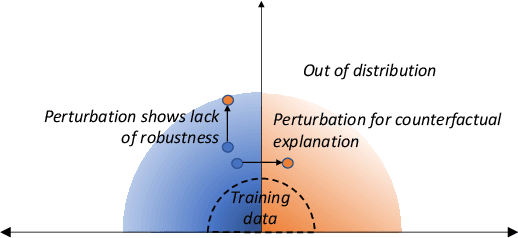

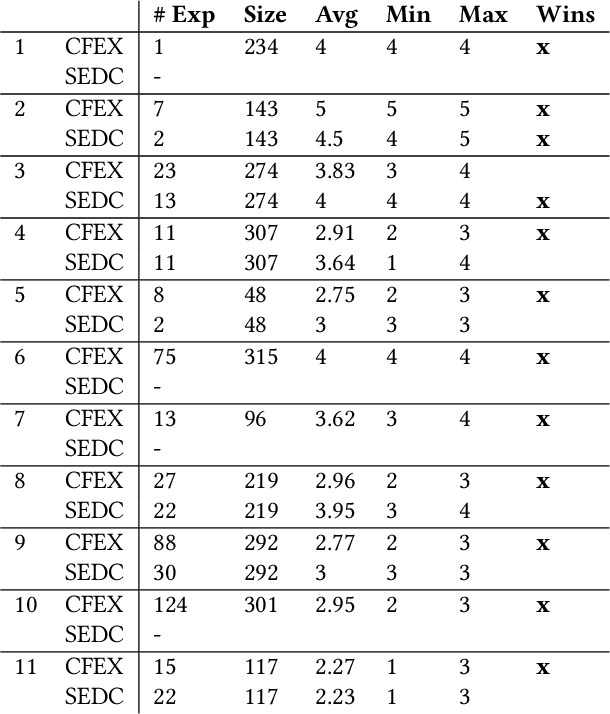
Machine learning (ML) models play an increasingly prevalent role in many software engineering tasks. However, because most models are now powered by opaque deep neural networks, it can be difficult for developers to understand why the model came to a certain conclusion and how to act upon the model's prediction. Motivated by this problem, this paper explores counterfactual explanations for models of source code. Such counterfactual explanations constitute minimal changes to the source code under which the model "changes its mind". We integrate counterfactual explanation generation to models of source code in a real-world setting. We describe considerations that impact both the ability to find realistic and plausible counterfactual explanations, as well as the usefulness of such explanation to the user of the model. In a series of experiments we investigate the efficacy of our approach on three different models, each based on a BERT-like architecture operating over source code.
Neural Software Analysis
Nov 16, 2020
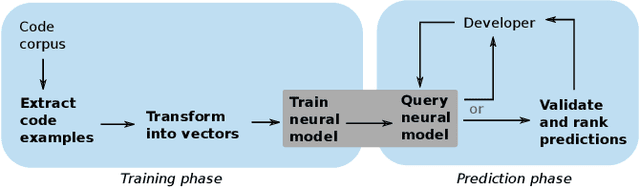
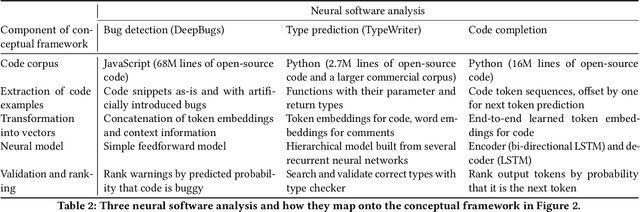
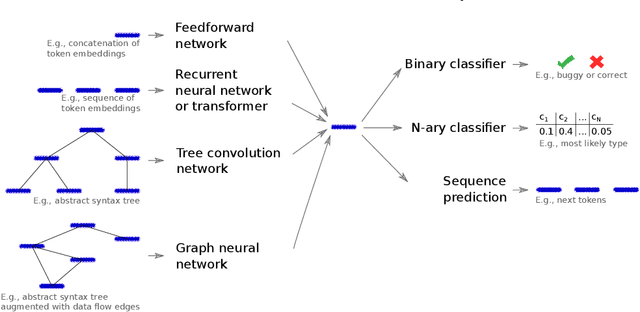
Many software development problems can be addressed by program analysis tools, which traditionally are based on precise, logical reasoning and heuristics to ensure that the tools are practical. Recent work has shown tremendous success through an alternative way of creating developer tools, which we call neural software analysis. The key idea is to train a neural machine learning model on numerous code examples, which, once trained, makes predictions about previously unseen code. In contrast to traditional program analysis, neural software analysis naturally handles fuzzy information, such as coding conventions and natural language embedded in code, without relying on manually encoded heuristics. This article gives an overview of neural software analysis, discusses when to (not) use it, and presents three example analyses. The analyses address challenging software development problems: bug detection, type prediction, and code completion. The resulting tools complement and outperform traditional program analyses, and are used in industrial practice.