 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Symmetric Losses for Learning from Corrupted Labels
Jan 27, 2019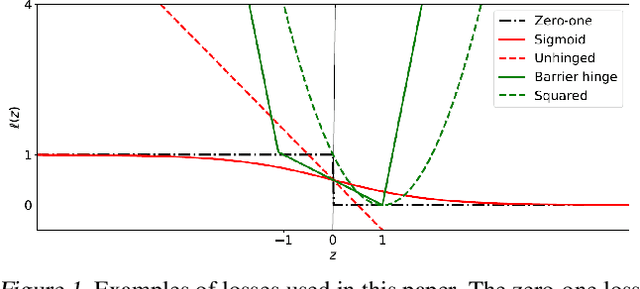
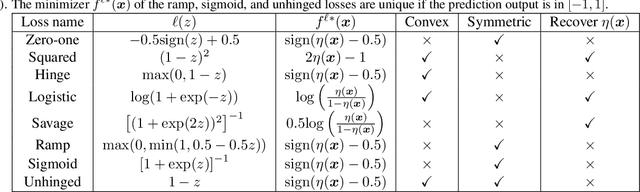
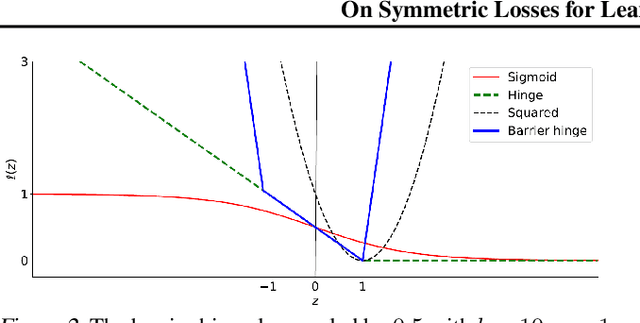
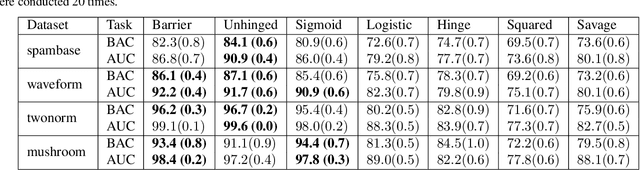
This paper aims to provide a better understanding of a symmetric loss. First, we show that using a symmetric loss is advantageous in the balanced error rate (BER) minimization and area under the receiver operating characteristic curve (AUC) maximization from corrupted labels. Second, we prove general theoretical properties of symmetric losses, including a classification-calibration condition, excess risk bound, conditional risk minimizer, and AUC-consistency condition. Third, since all nonnegative symmetric losses are non-convex, we propose a convex barrier hinge loss that benefits significantly from the symmetric condition, although it is not symmetric everywhere. Finally, we conduct experiments on BER and AUC optimization from corrupted labels to validate the relevance of the symmetric condition.
How does Disagreement Help Generalization against Label Corruption?
Jan 26, 2019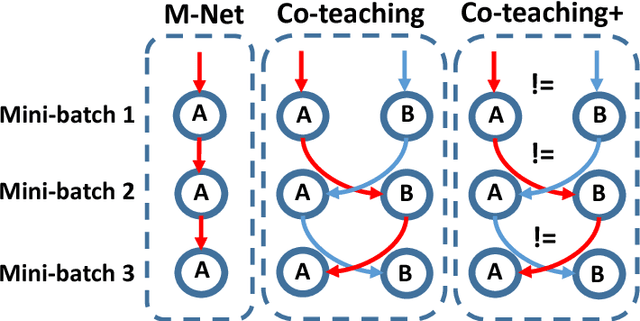
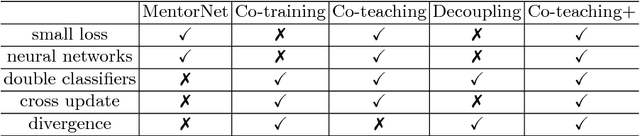
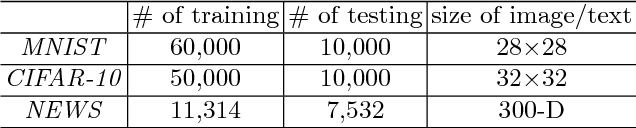
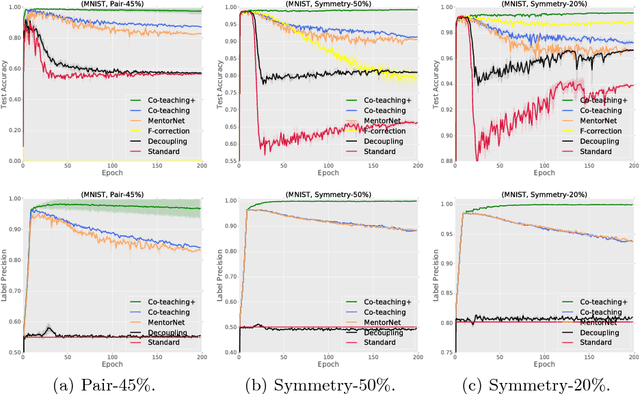
Learning with noisy labels is one of the hottest problems in weakly-supervised learning. Based on memorization effects of deep neural networks, training on small-loss instances becomes very promising for handling noisy labels. This fosters the state-of-the-art approach "Co-teaching" that cross-trains two deep neural networks using the small-loss trick. However, with the increase of epochs, two networks converge to a consensus and Co-teaching reduces to the self-training MentorNet. To tackle this issue, we propose a robust learning paradigm called Co-teaching+, which bridges the "Update by Disagreement" strategy with the original Co-teaching. First, two networks feed forward and predict all data, but keep prediction disagreement data only. Then, among such disagreement data, each network selects its small-loss data, but back propagates the small-loss data from its peer network and updates its own parameters. Empirical results on benchmark datasets demonstrate that Co-teaching+ is much superior to many state-of-the-art methods in the robustness of trained models.
Hierarchical Reinforcement Learning via Advantage-Weighted Information Maximization
Jan 05, 2019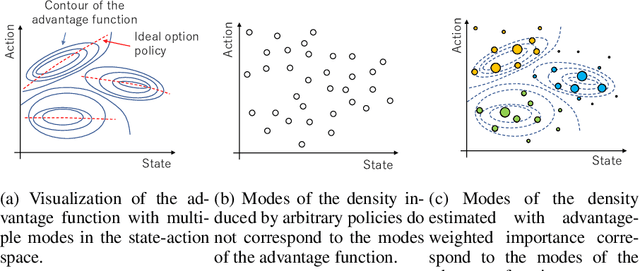


Real-world tasks are often highly structured. Hierarchical reinforcement learning (HRL) has attracted research interest as an approach for leveraging the hierarchical structure of a given task in reinforcement learning (RL). However, identifying the hierarchical policy structure that enhances the performance of RL is not a trivial task. In this paper, we propose an HRL method that learns a latent variable of a hierarchical policy using mutual information maximization. Our approach can be interpreted as a way to learn a discrete and latent representation of the state-action space. To learn option policies that correspond to modes of the advantage function, we introduce advantage-weighted importance sampling. In our HRL method, the gating policy learns to select option policies based on an option-value function, and these option policies are optimized based on the deterministic policy gradient method. This framework is derived by leveraging the analogy between a monolithic policy in standard RL and a hierarchical policy in HRL by using a deterministic option policy. Experimental results indicate that our HRL approach can learn a diversity of options and that it can enhance the performance of RL in continuous control tasks.
Active Deep Q-learning with Demonstration
Dec 06, 2018
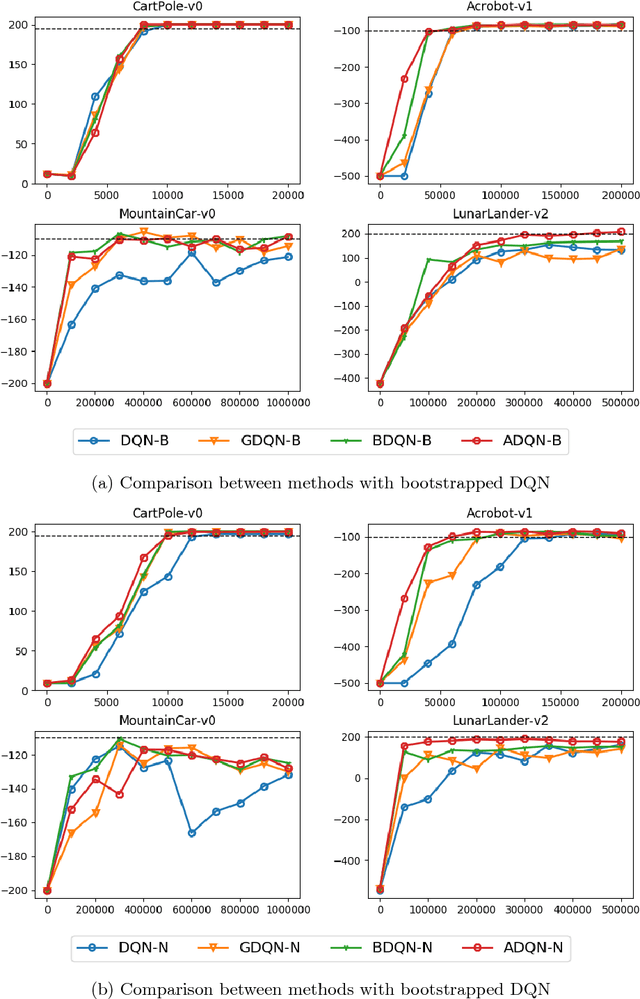
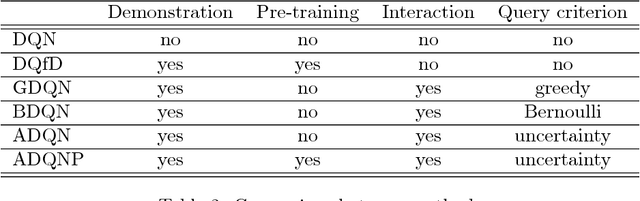
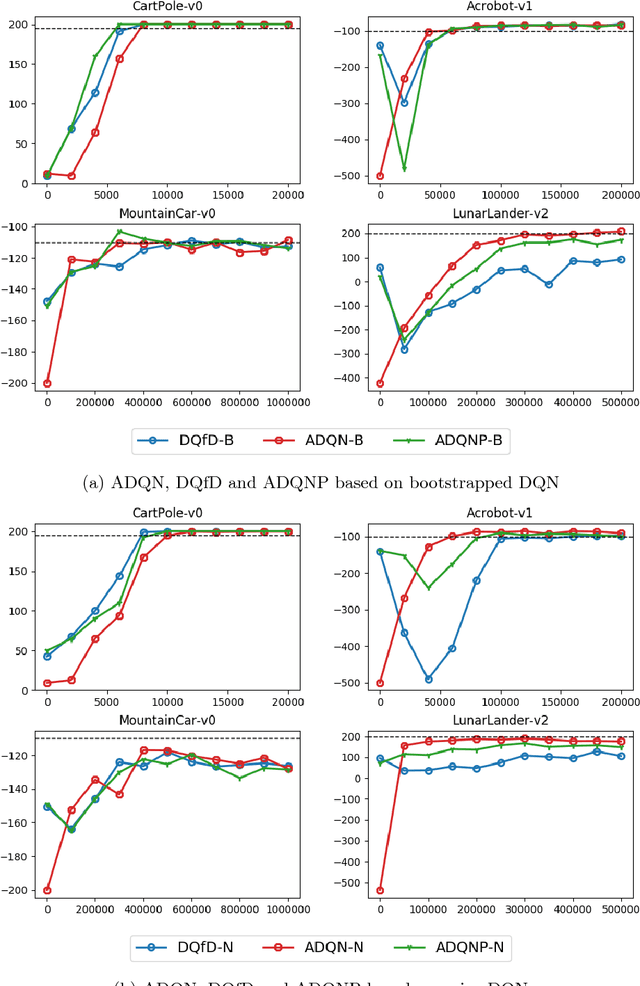
Recent research has shown that although Reinforcement Learning (RL) can benefit from expert demonstration, it usually takes considerable efforts to obtain enough demonstration. The efforts prevent training decent RL agents with expert demonstration in practice. In this work, we propose Active Reinforcement Learning with Demonstration (ARLD), a new framework to streamline RL in terms of demonstration efforts by allowing the RL agent to query for demonstration actively during training. Under the framework, we propose Active Deep Q-Network, a novel query strategy which adapts to the dynamically-changing distributions during the RL training process by estimating the uncertainty of recent states. The expert demonstration data within Active DQN are then utilized by optimizing supervised max-margin loss in addition to temporal difference loss within usual DQN training. We propose two methods of estimating the uncertainty based on two state-of-the-art DQN models, namely the divergence of bootstrapped DQN and the variance of noisy DQN. The empirical results validate that both methods not only learn faster than other passive expert demonstration methods with the same amount of demonstration and but also reach super-expert level of performance across four different tasks.
Lipschitz-Margin Training: Scalable Certification of Perturbation Invariance for Deep Neural Networks
Oct 31, 2018
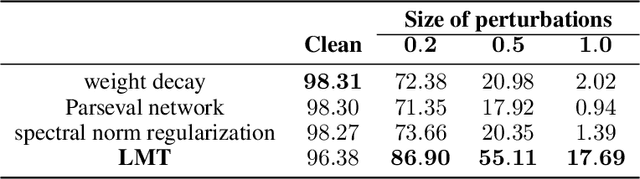

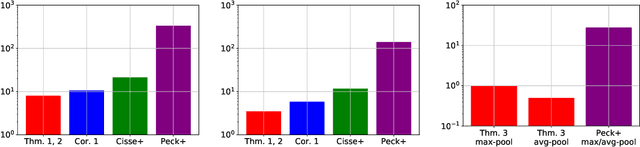
High sensitivity of neural networks against malicious perturbations on inputs causes security concerns. To take a steady step towards robust classifiers, we aim to create neural network models provably defended from perturbations. Prior certification work requires strong assumptions on network structures and massive computational costs, and thus the range of their applications was limited. From the relationship between the Lipschitz constants and prediction margins, we present a computationally efficient calculation technique to lower-bound the size of adversarial perturbations that can deceive networks, and that is widely applicable to various complicated networks. Moreover, we propose an efficient training procedure that robustifies networks and significantly improves the provably guarded areas around data points. In experimental evaluations, our method showed its ability to provide a non-trivial guarantee and enhance robustness for even large networks.
Masking: A New Perspective of Noisy Supervision
Oct 31, 2018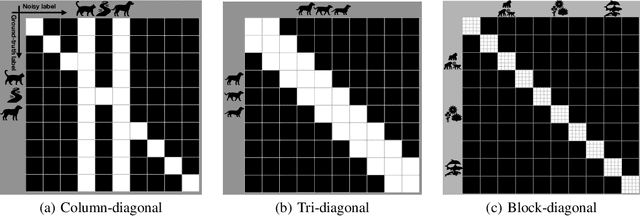
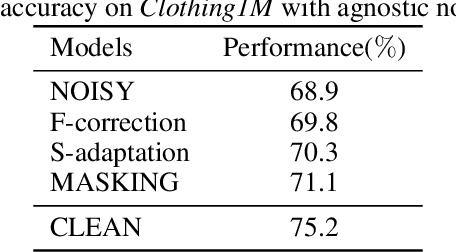
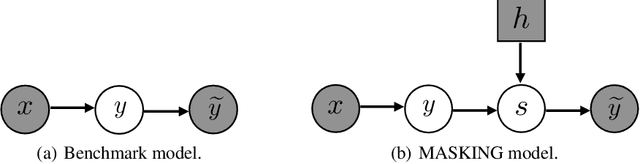
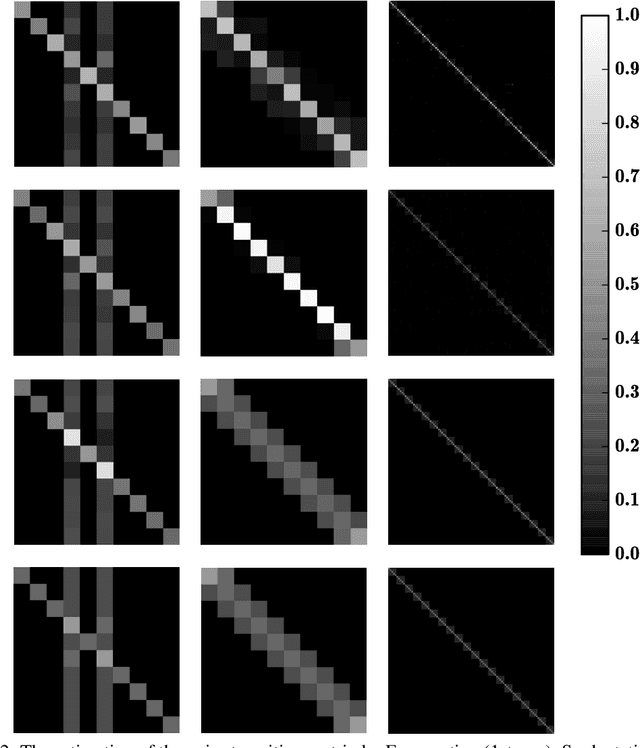
It is important to learn various types of classifiers given training data with noisy labels. Noisy labels, in the most popular noise model hitherto, are corrupted from ground-truth labels by an unknown noise transition matrix. Thus, by estimating this matrix, classifiers can escape from overfitting those noisy labels. However, such estimation is practically difficult, due to either the indirect nature of two-step approaches, or not big enough data to afford end-to-end approaches. In this paper, we propose a human-assisted approach called Masking that conveys human cognition of invalid class transitions and naturally speculates the structure of the noise transition matrix. To this end, we derive a structure-aware probabilistic model incorporating a structure prior, and solve the challenges from structure extraction and structure alignment. Thanks to Masking, we only estimate unmasked noise transition probabilities and the burden of estimation is tremendously reduced. We conduct extensive experiments on CIFAR-10 and CIFAR-100 with three noise structures as well as the industrial-level Clothing1M with agnostic noise structure, and the results show that Masking can improve the robustness of classifiers significantly.
Co-teaching: Robust Training of Deep Neural Networks with Extremely Noisy Labels
Oct 30, 2018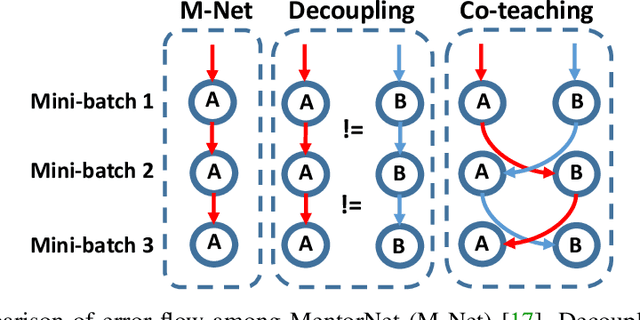
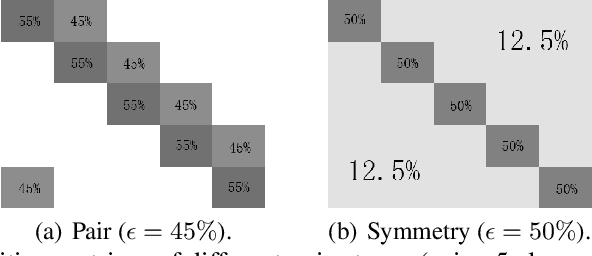

Deep learning with noisy labels is practically challenging, as the capacity of deep models is so high that they can totally memorize these noisy labels sooner or later during training. Nonetheless, recent studies on the memorization effects of deep neural networks show that they would first memorize training data of clean labels and then those of noisy labels. Therefore in this paper, we propose a new deep learning paradigm called Co-teaching for combating with noisy labels. Namely, we train two deep neural networks simultaneously, and let them teach each other given every mini-batch: firstly, each network feeds forward all data and selects some data of possibly clean labels; secondly, two networks communicate with each other what data in this mini-batch should be used for training; finally, each network back propagates the data selected by its peer network and updates itself. Empirical results on noisy versions of MNIST, CIFAR-10 and CIFAR-100 demonstrate that Co-teaching is much superior to the state-of-the-art methods in the robustness of trained deep models.
Continuous-time Value Function Approximation in Reproducing Kernel Hilbert Spaces
Oct 26, 2018
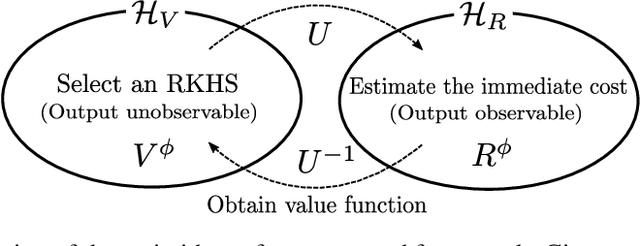
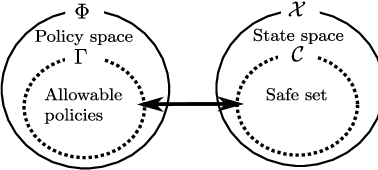

Motivated by the success of reinforcement learning (RL) for discrete-time tasks such as AlphaGo and Atari games, there has been a recent surge of interest in using RL for continuous-time control of physical systems (cf. many challenging tasks in OpenAI Gym and DeepMind Control Suite). Since discretization of time is susceptible to error, it is methodologically more desirable to handle the system dynamics directly in continuous time. However, very few techniques exist for continuous-time RL and they lack flexibility in value function approximation. In this paper, we propose a novel framework for model-based continuous-time value function approximation in reproducing kernel Hilbert spaces. The resulting framework is so flexible that it can accommodate any kind of kernel-based approach, such as Gaussian processes and kernel adaptive filters, and it allows us to handle uncertainties and nonstationarity without prior knowledge about the environment or what basis functions to employ. We demonstrate the validity of the presented framework through experiments.
Positive-Unlabeled Classification under Class Prior Shift and Asymmetric Error
Oct 17, 2018
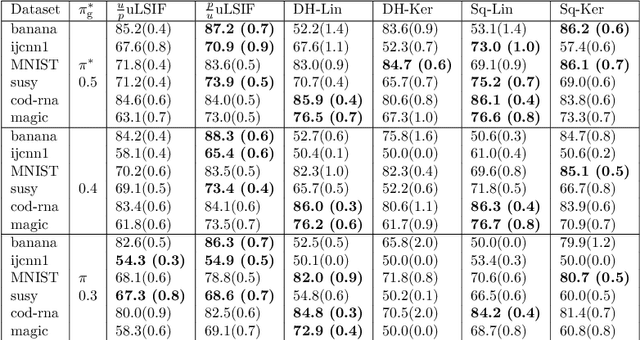
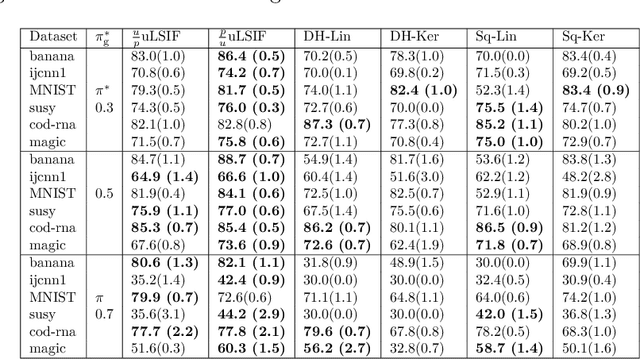
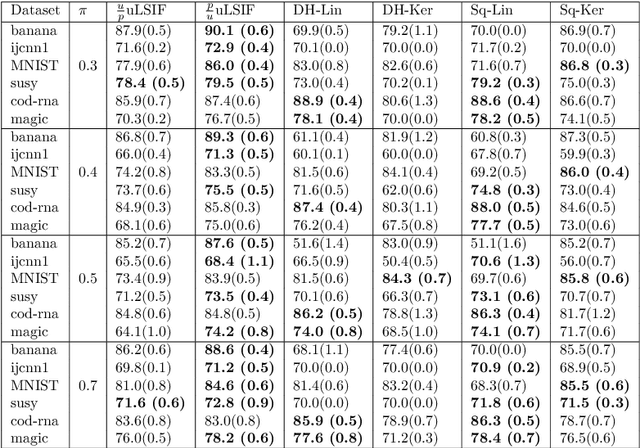
Bottlenecks of binary classification from positive and unlabeled data (PU classification) are the requirements that given unlabeled patterns are drawn from the test marginal distribution, and the penalty of the false positive error is identical to the false negative error. However, such requirements are often not fulfilled in practice. In this paper, we generalize PU classification to the class prior shift and asymmetric error scenarios. Based on the analysis of the Bayes optimal classifier, we show that given a test class prior, PU classification under class prior shift is equivalent to PU classification with asymmetric error. Then, we propose two different frameworks to handle these problems, namely, a risk minimization framework and density ratio estimation framework. Finally, we demonstrate the effectiveness of the proposed frameworks and compare both frameworks through experiments using benchmark datasets.
Complementary-Label Learning for Arbitrary Losses and Models
Oct 10, 2018
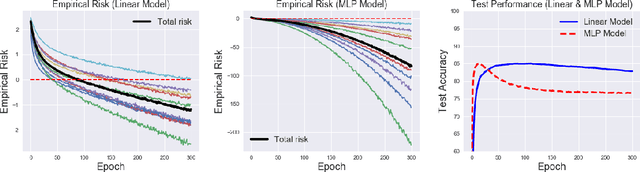
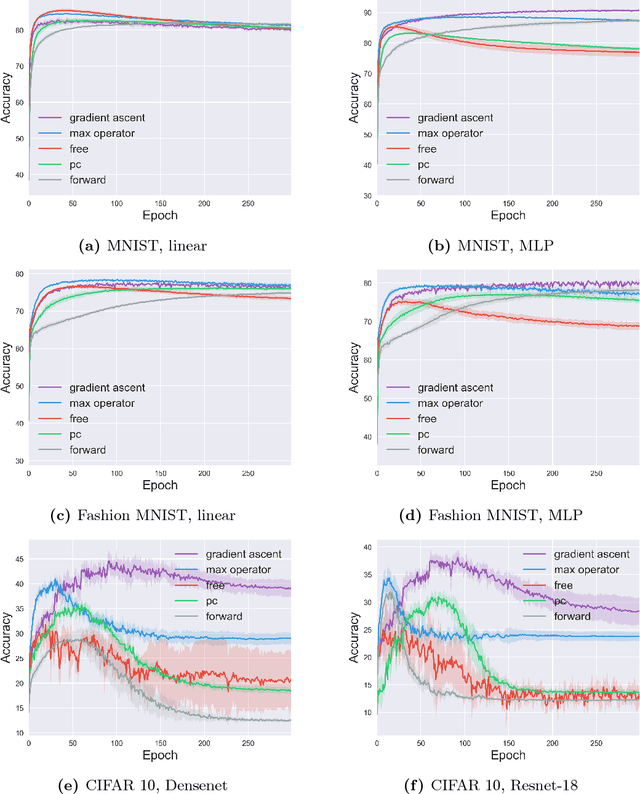
In contrast to the standard classification paradigm where the true (or possibly noisy) class is given to each training pattern, complementary-label learning only uses training patterns each equipped with a complementary label. This only specifies one of the classes that the pattern does not belong to. The seminal paper on complementary-label learning proposed an unbiased estimator of the classification risk that can be computed only from complementarily labeled data. However, it required a restrictive condition on the loss functions, making it impossible to use popular losses such as the softmax cross-entropy loss. Recently, another formulation with the softmax cross-entropy loss was proposed with consistency guarantee. However, this formulation does not explicitly involve a risk estimator. Thus model/hyper-parameter selection is not possible by cross-validation---we may need additional ordinarily labeled data for validation purposes, which is not available in the current setup. In this paper, we give a novel general framework of complementary-label learning, and derive an unbiased risk estimator for arbitrary losses and models. We further improve the risk estimator by non-negative correction and demonstrate its superiority through experiments.