 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Dense Subgraph Discovery via Blurred-Graph Feedback
Jun 24, 2020



Dense subgraph discovery aims to find a dense component in edge-weighted graphs. This is a fundamental graph-mining task with a variety of applications and thus has received much attention recently. Although most existing methods assume that each individual edge weight is easily obtained, such an assumption is not necessarily valid in practice. In this paper, we introduce a novel learning problem for dense subgraph discovery in which a learner queries edge subsets rather than only single edges and observes a noisy sum of edge weights in a queried subset. For this problem, we first propose a polynomial-time algorithm that obtains a nearly-optimal solution with high probability. Moreover, to deal with large-sized graphs, we design a more scalable algorithm with a theoretical guarantee. Computational experiments using real-world graphs demonstrate the effectiveness of our algorithms.
Coupling-based Invertible Neural Networks Are Universal Diffeomorphism Approximators
Jun 20, 2020
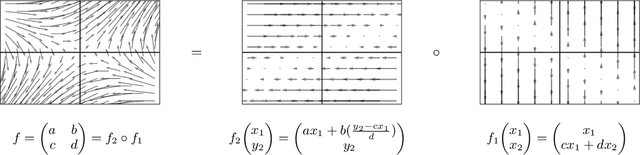
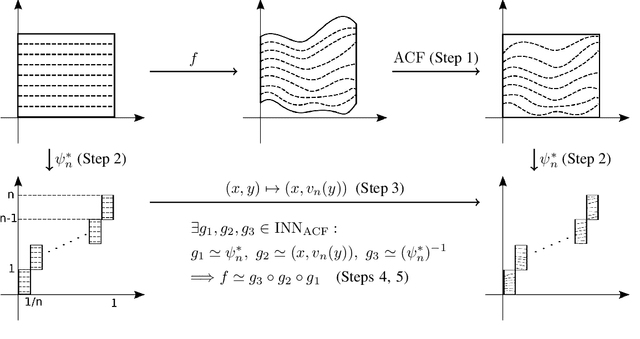
Invertible neural networks based on coupling flows (CF-INNs) have various machine learning applications such as image synthesis and representation learning. However, their desirable characteristics such as analytic invertibility come at the cost of restricting the functional forms. This poses a question on their representation power: are CF-INNs universal approximators for invertible functions? Without a universality, there could be a well-behaved invertible transformation that the CF-INN can never approximate, hence it would render the model class unreliable. We answer this question by showing a convenient criterion: a CF-INN is universal if its layers contain affine coupling and invertible linear functions as special cases. As its corollary, we can affirmatively resolve a previously unsolved problem: whether normalizing flow models based on affine coupling can be universal distributional approximators. In the course of proving the universality, we prove a general theorem to show the equivalence of the universality for certain diffeomorphism classes, a theoretical insight that is of interest by itself.
Analysis and Design of Thompson Sampling for Stochastic Partial Monitoring
Jun 17, 2020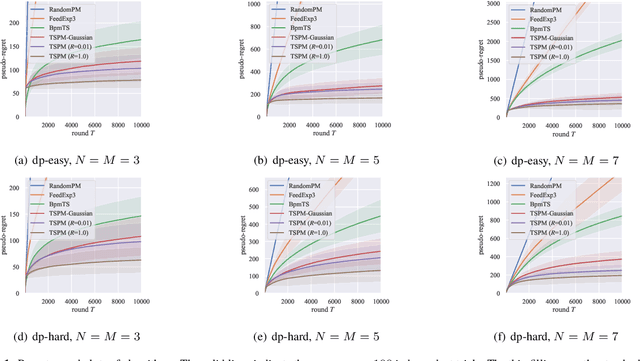

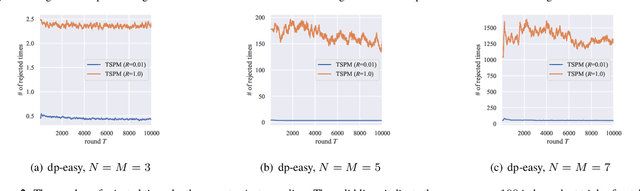
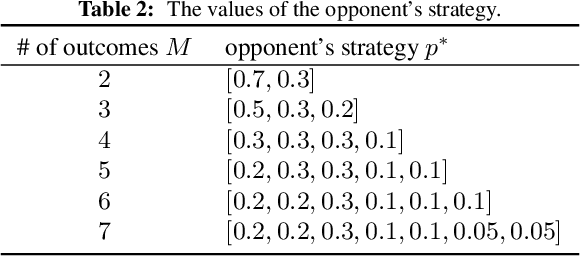
We investigate finite stochastic partial monitoring, which is a general model for sequential learning with limited feedback. While Thompson sampling is one of the most promising algorithms on a variety of online decision-making problems, its properties for stochastic partial monitoring have not been theoretically investigated, and the existing algorithm relies on a heuristic approximation of the posterior distribution. To mitigate these problems, we present a novel Thompson-sampling-based algorithm, which enables us to exactly sample the target parameter from the posterior distribution. Besides, we prove that the new algorithm achieves the logarithmic problem-dependent expected pseudo-regret $\mathrm{O}(\log T)$ for a linearized variant of the problem with local observability. This result is the first regret bound of Thompson sampling for partial monitoring, which also becomes the first logarithmic regret bound of Thompson sampling for linear bandits.
LFD-ProtoNet: Prototypical Network Based on Local Fisher Discriminant Analysis for Few-shot Learning
Jun 15, 2020
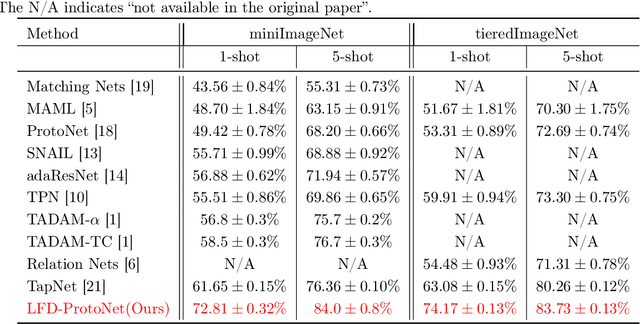
The prototypical network (ProtoNet) is a few-shot learning framework that performs metric learning and classification using the distance to prototype representations of each class. It has attracted a great deal of attention recently since it is simple to implement, highly extensible, and performs well in experiments. However, it only takes into account the mean of the support vectors as prototypes and thus it performs poorly when the support set has high variance. In this paper, we propose to combine ProtoNet with local Fisher discriminant analysis to reduce the local within-class covariance and increase the local between-class covariance of the support set. We show the usefulness of the proposed method by theoretically providing an expected risk bound and empirically demonstrating its superior classification accuracy on miniImageNet and tieredImageNet.
Parts-dependent Label Noise: Towards Instance-dependent Label Noise
Jun 14, 2020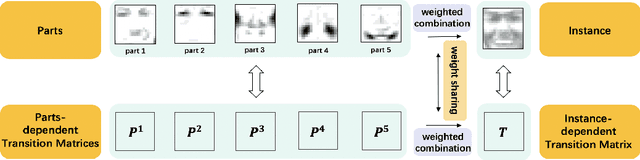
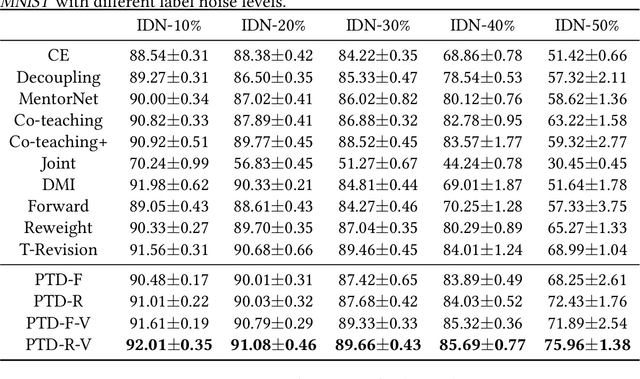
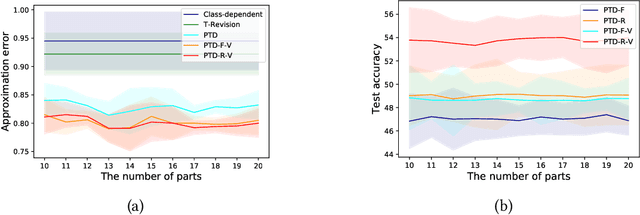
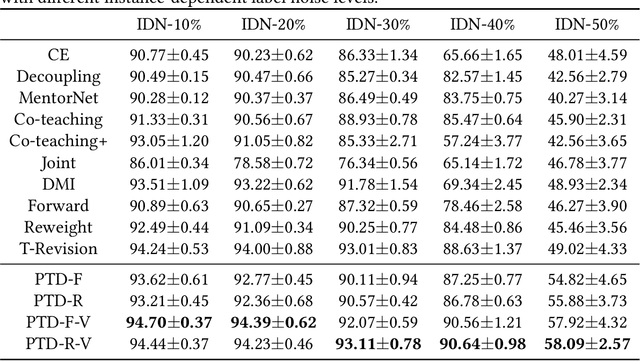
Learning with the \textit{instance-dependent} label noise is challenging, because it is hard to model such real-world noise. Note that there are psychological and physiological evidences showing that we humans perceive instances by decomposing them into parts. Annotators are therefore more likely to annotate instances based on the parts rather than the whole instances. Motivated by this human cognition, in this paper, we approximate the instance-dependent label noise by exploiting \textit{parts-dependent} label noise. Specifically, since instances can be approximately reconstructed by a combination of parts, we approximate the instance-dependent \textit{transition matrix} for an instance by a combination of the transition matrices for the parts of the instance. The transition matrices for parts can be learned by exploiting anchor points (i.e., data points that belong to a specific class almost surely). Empirical evaluations on synthetic and real-world datasets demonstrate our method is superior to the state-of-the-art approaches for learning from the instance-dependent label noise.
Dual T: Reducing Estimation Error for Transition Matrix in Label-noise Learning
Jun 14, 2020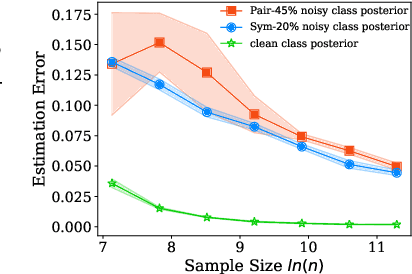
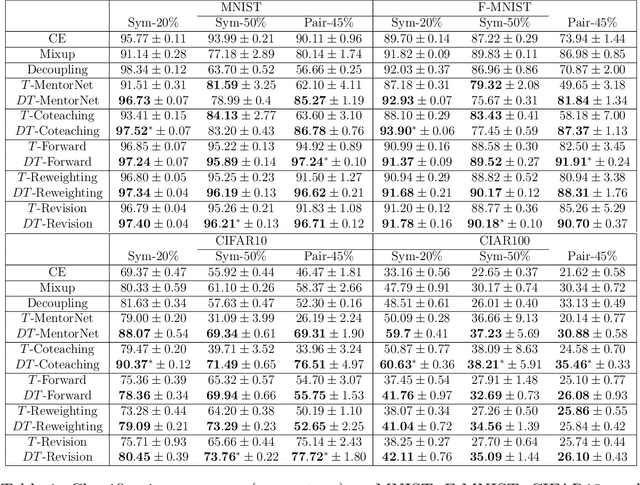
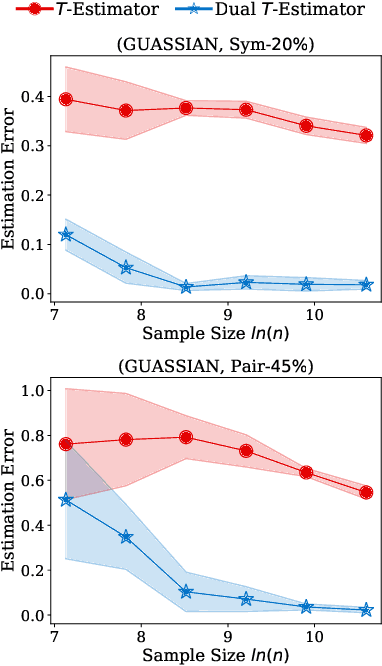

The \textit{transition matrix}, denoting the transition relationship from clean labels to noisy labels, is essential to build \textit{statistically consistent} classifiers in label-noise learning. Existing methods for estimating the transition matrix rely heavily on estimating the noisy class posterior. However, the estimation error for \textit{noisy class posterior} could be large due to the randomness of label noise. The estimation error would lead the transition matrix to be poorly estimated. Therefore, in this paper, we aim to solve this problem by exploiting the divide-and-conquer paradigm. Specifically, we introduce an \textit{intermediate class} to avoid directly estimating the noisy class posterior. By this intermediate class, the original transition matrix can then be factorized into the product of two easy-to-estimate transition matrices. We term the proposed method the \textit{dual $T$-estimator}. Both theoretical analyses and empirical results illustrate the effectiveness of the dual $T$-estimator for estimating transition matrices, leading to better classification performances.
Similarity-based Classification: Connecting Similarity Learning to Binary Classification
Jun 11, 2020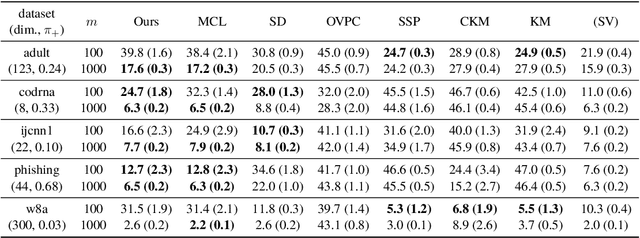
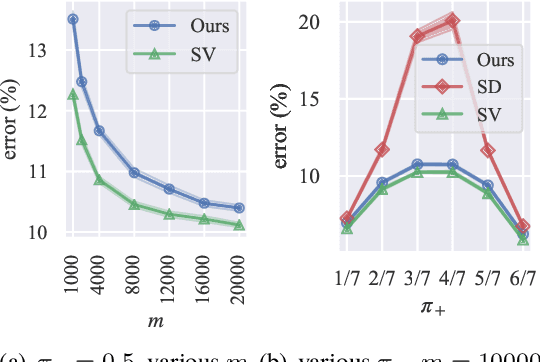
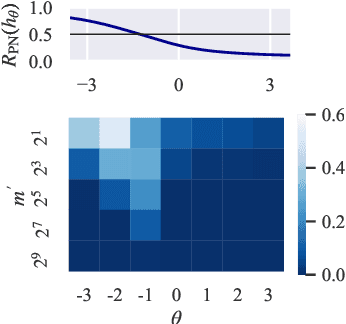
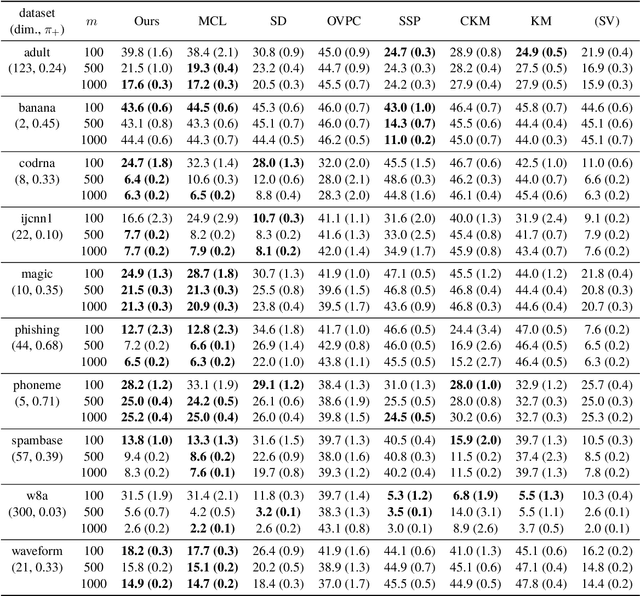
In real-world classification problems, pairwise supervision (i.e., a pair of patterns with a binary label indicating whether they belong to the same class or not) can often be obtained at a lower cost than ordinary class labels. Similarity learning is a general framework to utilize such pairwise supervision to elicit useful representations by inferring the relationship between two data points, which encompasses various important preprocessing tasks such as metric learning, kernel learning, graph embedding, and contrastive representation learning. Although elicited representations are expected to perform well in downstream tasks such as classification, little theoretical insight has been given in the literature so far. In this paper, we reveal that a specific formulation of similarity learning is strongly related to the objective of binary classification, which spurs us to learn a binary classifier without ordinary class labels---by fitting the product of real-valued prediction functions of pairwise patterns to their similarity. Our formulation of similarity learning does not only generalize many existing ones, but also admits an excess risk bound showing an explicit connection to classification. Finally, we empirically demonstrate the practical usefulness of the proposed method on benchmark datasets.
Rethinking Importance Weighting for Deep Learning under Distribution Shift
Jun 08, 2020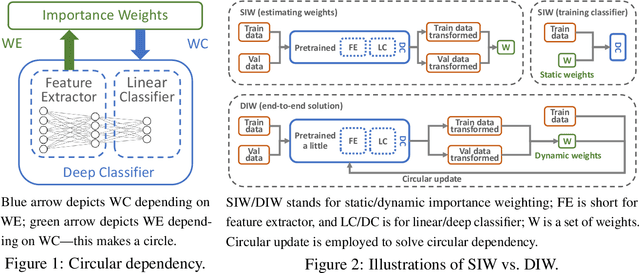
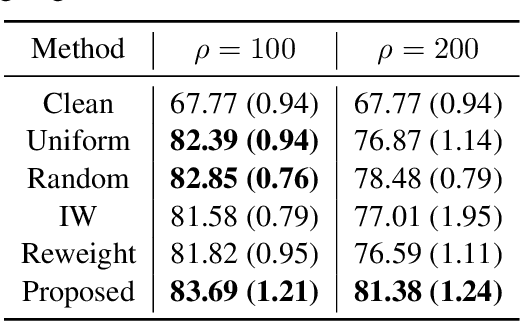
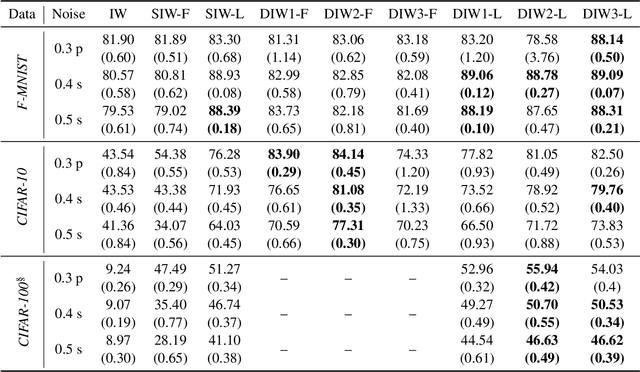
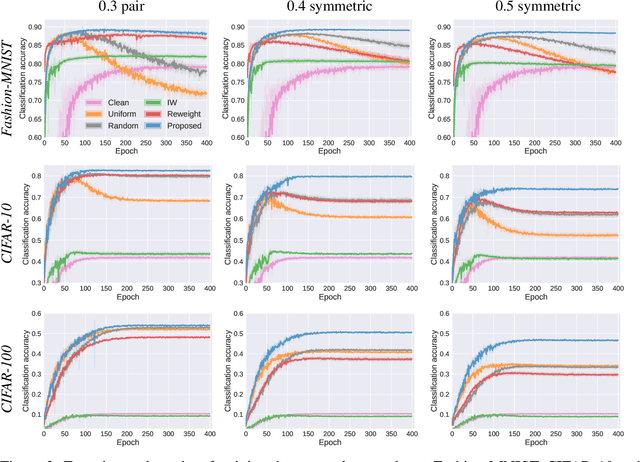
Under distribution shift (DS) where the training data distribution differs from the test one, a powerful technique is importance weighting (IW) which handles DS in two separate steps: weight estimation (WE) estimates the test-over-training density ratio and weighted classification (WC) trains the classifier from weighted training data. However, IW cannot work well on complex data, since WE is incompatible with deep learning. In this paper, we rethink IW and theoretically show it suffers from a circular dependency: we need not only WE for WC, but also WC for WE where a trained deep classifier is used as the feature extractor (FE). To cut off the dependency, we try to pretrain FE from unweighted training data, which leads to biased FE. To overcome the bias, we propose an end-to-end solution dynamic IW that iterates between WE and WC and combines them in a seamless manner, and hence our WE can also enjoy deep networks and stochastic optimizers indirectly. Experiments with two representative DSs on Fashion-MNIST and CIFAR-10/100 demonstrate that dynamic IW compares favorably with state-of-the-art methods.
Calibrated Surrogate Losses for Adversarially Robust Classification
May 28, 2020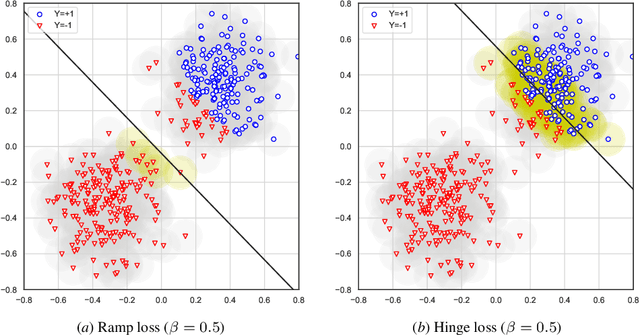
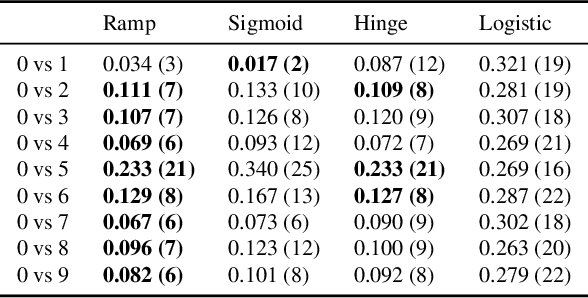
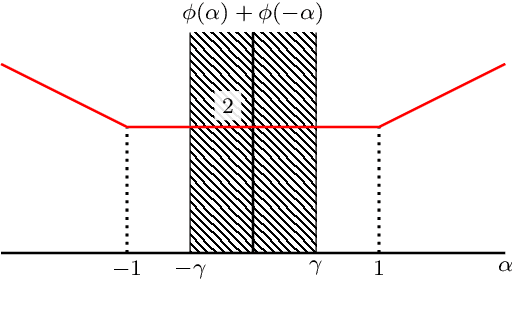
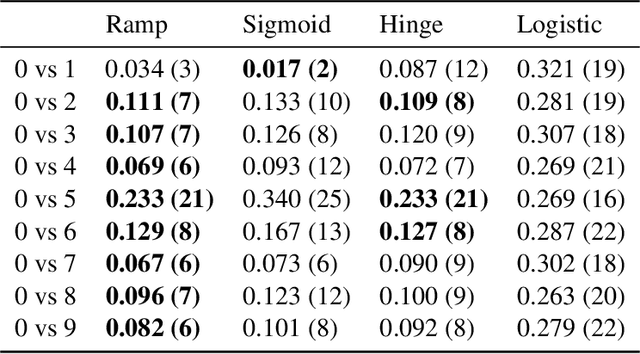
Adversarially robust classification seeks a classifier that is insensitive to adversarial perturbations of test patterns. This problem is often formulated via a minimax objective, where the target loss is the worst-case value of the 0-1 loss subject to a bound on the size of perturbation. Recent work has proposed convex surrogates for the adversarial 0-1 loss, in an effort to make optimization more tractable. In this work, we consider the question of which surrogate losses are calibrated with respect to the adversarial 0-1 loss, meaning that minimization of the former implies minimization of the latter. We show that no convex surrogate loss is calibrated with respect to the adversarial 0-1 loss when restricted to the class of linear models. We further introduce a class of nonconvex losses and offer necessary and sufficient conditions for losses in this class to be calibrated.
Learning from Aggregate Observations
Apr 14, 2020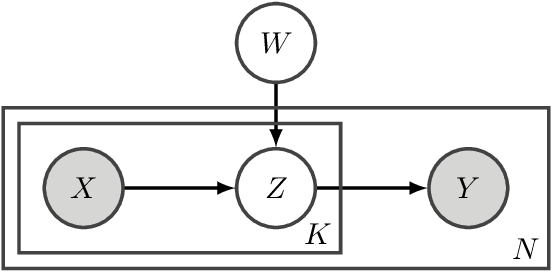

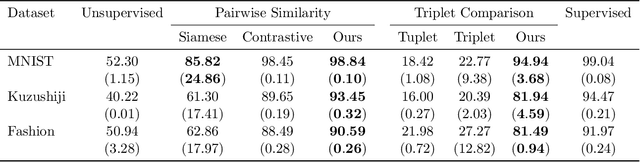
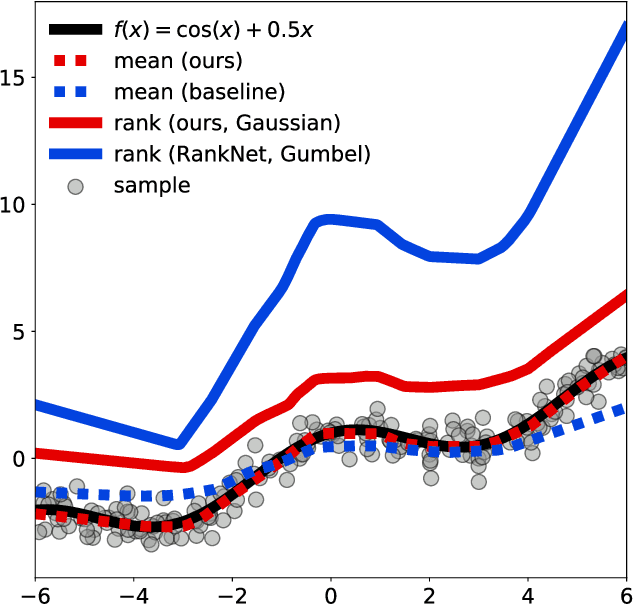
We study the problem of learning from aggregate observations where supervision signals are given to sets of instances instead of individual instances, while the goal is still to predict labels of unseen individuals. A well-known example is multiple instance learning (MIL). In this paper, we extend MIL beyond binary classification to other problems such as multiclass classification and regression. We present a probabilistic framework that is applicable to a variety of aggregate observations, e.g., pairwise similarity for classification and mean/difference/rank observation for regression. We propose a simple yet effective method based on the maximum likelihood principle, which can be simply implemented for various differentiable models such as deep neural networks and gradient boosting machines. Experiments on three novel problem settings -- classification via triplet comparison and regression via mean/rank observation indicate the effectiveness of the proposed method.