 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Black-box Approach for Non-stationary Multi-agent Reinforcement Learning
Jun 12, 2023

We investigate learning the equilibria in non-stationary multi-agent systems and address the challenges that differentiate multi-agent learning from single-agent learning. Specifically, we focus on games with bandit feedback, where testing an equilibrium can result in substantial regret even when the gap to be tested is small, and the existence of multiple optimal solutions (equilibria) in stationary games poses extra challenges. To overcome these obstacles, we propose a versatile black-box approach applicable to a broad spectrum of problems, such as general-sum games, potential games, and Markov games, when equipped with appropriate learning and testing oracles for stationary environments. Our algorithms can achieve $\widetilde{O}\left(\Delta^{1/4}T^{3/4}\right)$ regret when the degree of nonstationarity, as measured by total variation $\Delta$, is known, and $\widetilde{O}\left(\Delta^{1/5}T^{4/5}\right)$ regret when $\Delta$ is unknown, where $T$ is the number of rounds. Meanwhile, our algorithm inherits the favorable dependence on number of agents from the oracles. As a side contribution that may be independent of interest, we show how to test for various types of equilibria by a black-box reduction to single-agent learning, which includes Nash equilibria, correlated equilibria, and coarse correlated equilibria.
No-Regret Online Prediction with Strategic Experts
May 24, 2023
We study a generalization of the online binary prediction with expert advice framework where at each round, the learner is allowed to pick $m\geq 1$ experts from a pool of $K$ experts and the overall utility is a modular or submodular function of the chosen experts. We focus on the setting in which experts act strategically and aim to maximize their influence on the algorithm's predictions by potentially misreporting their beliefs about the events. Among others, this setting finds applications in forecasting competitions where the learner seeks not only to make predictions by aggregating different forecasters but also to rank them according to their relative performance. Our goal is to design algorithms that satisfy the following two requirements: 1) $\textit{Incentive-compatible}$: Incentivize the experts to report their beliefs truthfully, and 2) $\textit{No-regret}$: Achieve sublinear regret with respect to the true beliefs of the best fixed set of $m$ experts in hindsight. Prior works have studied this framework when $m=1$ and provided incentive-compatible no-regret algorithms for the problem. We first show that a simple reduction of our problem to the $m=1$ setting is neither efficient nor effective. Then, we provide algorithms that utilize the specific structure of the utility functions to achieve the two desired goals.
Stochastic Contextual Bandits with Long Horizon Rewards
Feb 03, 2023The growing interest in complex decision-making and language modeling problems highlights the importance of sample-efficient learning over very long horizons. This work takes a step in this direction by investigating contextual linear bandits where the current reward depends on at most $s$ prior actions and contexts (not necessarily consecutive), up to a time horizon of $h$. In order to avoid polynomial dependence on $h$, we propose new algorithms that leverage sparsity to discover the dependence pattern and arm parameters jointly. We consider both the data-poor ($T<h$) and data-rich ($T\ge h$) regimes, and derive respective regret upper bounds $\tilde O(d\sqrt{sT} +\min\{ q, T\})$ and $\tilde O(\sqrt{sdT})$, with sparsity $s$, feature dimension $d$, total time horizon $T$, and $q$ that is adaptive to the reward dependence pattern. Complementing upper bounds, we also show that learning over a single trajectory brings inherent challenges: While the dependence pattern and arm parameters form a rank-1 matrix, circulant matrices are not isometric over rank-1 manifolds and sample complexity indeed benefits from the sparse reward dependence structure. Our results necessitate a new analysis to address long-range temporal dependencies across data and avoid polynomial dependence on the reward horizon $h$. Specifically, we utilize connections to the restricted isometry property of circulant matrices formed by dependent sub-Gaussian vectors and establish new guarantees that are also of independent interest.
Offline congestion games: How feedback type affects data coverage requirement
Oct 24, 2022This paper investigates when one can efficiently recover an approximate Nash Equilibrium (NE) in offline congestion games.The existing dataset coverage assumption in offline general-sum games inevitably incurs a dependency on the number of actions, which can be exponentially large in congestion games. We consider three different types of feedback with decreasing revealed information. Starting from the facility-level (a.k.a., semi-bandit) feedback, we propose a novel one-unit deviation coverage condition and give a pessimism-type algorithm that can recover an approximate NE. For the agent-level (a.k.a., bandit) feedback setting, interestingly, we show the one-unit deviation coverage condition is not sufficient. On the other hand, we convert the game to multi-agent linear bandits and show that with a generalized data coverage assumption in offline linear bandits, we can efficiently recover the approximate NE. Lastly, we consider a novel type of feedback, the game-level feedback where only the total reward from all agents is revealed. Again, we show the coverage assumption for the agent-level feedback setting is insufficient in the game-level feedback setting, and with a stronger version of the data coverage assumption for linear bandits, we can recover an approximate NE. Together, our results constitute the first study of offline congestion games and imply formal separations between different types of feedback.
Towards a Theoretical Foundation of Policy Optimization for Learning Control Policies
Oct 10, 2022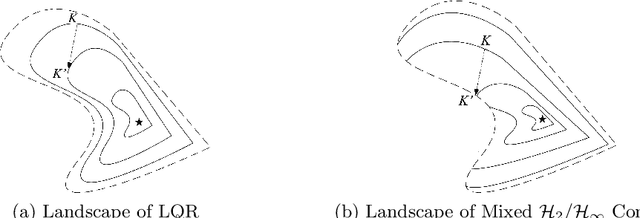
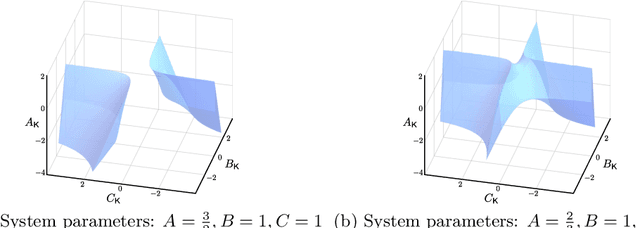
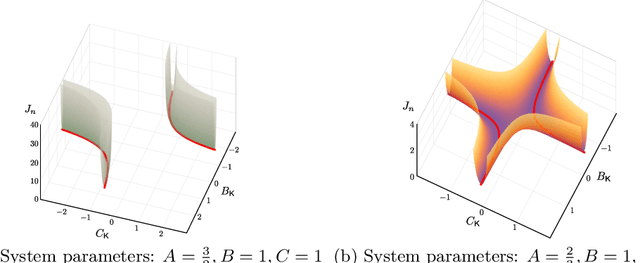
Gradient-based methods have been widely used for system design and optimization in diverse application domains. Recently, there has been a renewed interest in studying theoretical properties of these methods in the context of control and reinforcement learning. This article surveys some of the recent developments on policy optimization, a gradient-based iterative approach for feedback control synthesis, popularized by successes of reinforcement learning. We take an interdisciplinary perspective in our exposition that connects control theory, reinforcement learning, and large-scale optimization. We review a number of recently-developed theoretical results on the optimization landscape, global convergence, and sample complexity of gradient-based methods for various continuous control problems such as the linear quadratic regulator (LQR), $\mathcal{H}_\infty$ control, risk-sensitive control, linear quadratic Gaussian (LQG) control, and output feedback synthesis. In conjunction with these optimization results, we also discuss how direct policy optimization handles stability and robustness concerns in learning-based control, two main desiderata in control engineering. We conclude the survey by pointing out several challenges and opportunities at the intersection of learning and control.
Iterative Linear Quadratic Optimization for Nonlinear Control: Differentiable Programming Algorithmic Templates
Jul 13, 2022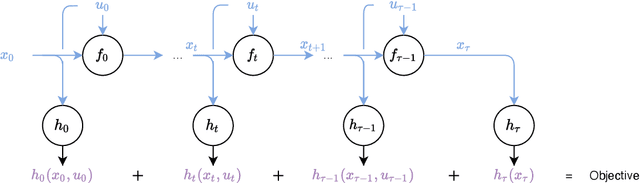


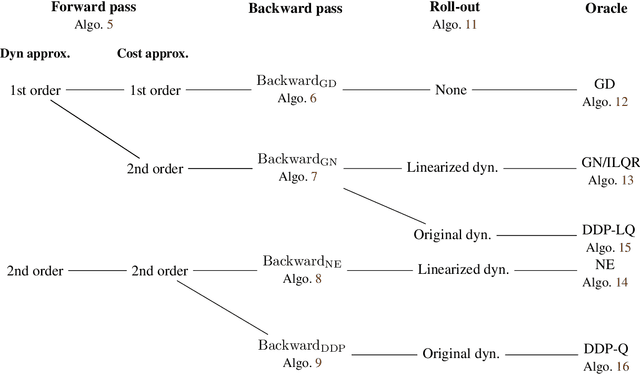
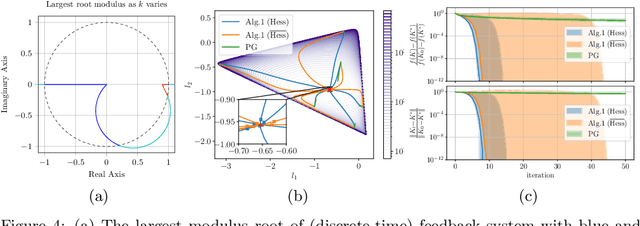
We present the implementation of nonlinear control algorithms based on linear and quadratic approximations of the objective from a functional viewpoint. We present a gradient descent, a Gauss-Newton method, a Newton method, differential dynamic programming approaches with linear quadratic or quadratic approximations, various line-search strategies, and regularized variants of these algorithms. We derive the computational complexities of all algorithms in a differentiable programming framework and present sufficient optimality conditions. We compare the algorithms on several benchmarks, such as autonomous car racing using a bicycle model of a car. The algorithms are coded in a differentiable programming language in a publicly available package.
Interactive Combinatorial Bandits: Balancing Competitivity and Complementarity
Jul 07, 2022

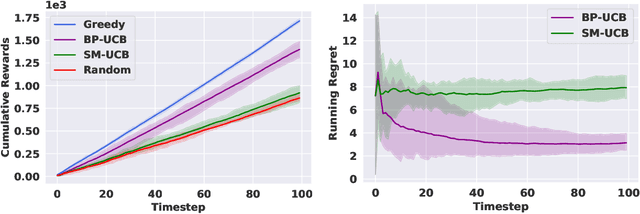

We study non-modular function maximization in the online interactive bandit setting. We are motivated by applications where there is a natural complementarity between certain elements: e.g., in a movie recommendation system, watching the first movie in a series complements the experience of watching a second (and a third, etc.). This is not expressible using only submodular functions which can represent only competitiveness between elements. We extend the purely submodular approach in two ways. First, we assume that the objective can be decomposed into the sum of monotone suBmodular and suPermodular function, known as a BP objective. Here, complementarity is naturally modeled by the supermodular component. We develop a UCB-style algorithm, where at each round a noisy gain is revealed after an action is taken that balances refining beliefs about the unknown objectives (exploration) and choosing actions that appear promising (exploitation). Defining regret in terms of submodular and supermodular curvature with respect to a full-knowledge greedy baseline, we show that this algorithm achieves at most $O(\sqrt{T})$ regret after $T$ rounds of play. Second, for those functions that do not admit a BP structure, we provide analogous regret guarantees in terms of their submodularity ratio; this is applicable for functions that are almost, but not quite, submodular. We numerically study the tasks of movie recommendation on the MovieLens dataset, and selection of training subsets for classification. Through these examples, we demonstrate the algorithm's performance as well as the shortcomings of viewing these problems as being solely submodular.
Multi-learner risk reduction under endogenous participation dynamics
Jun 06, 2022
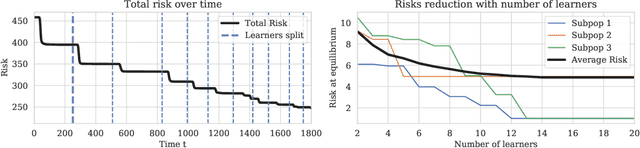
Prediction systems face exogenous and endogenous distribution shift -- the world constantly changes, and the predictions the system makes change the environment in which it operates. For example, a music recommender observes exogeneous changes in the user distribution as different communities have increased access to high speed internet. If users under the age of 18 enjoy their recommendations, the proportion of the user base comprised of those under 18 may endogeneously increase. Most of the study of endogenous shifts has focused on the single decision-maker setting, where there is one learner that users either choose to use or not. This paper studies participation dynamics between sub-populations and possibly many learners. We study the behavior of systems with \emph{risk-reducing} learners and sub-populations. A risk-reducing learner updates their decision upon observing a mixture distribution of the sub-populations $\mathcal{D}$ in such a way that it decreases the risk of the learner on that mixture. A risk reducing sub-population updates its apportionment amongst learners in a way which reduces its overall loss. Previous work on the single learner case shows that myopic risk minimization can result in high overall loss~\citep{perdomo2020performative, miller2021outside} and representation disparity~\citep{hashimoto2018fairness, zhang2019group}. Our work analyzes the outcomes of multiple myopic learners and market forces, often leading to better global loss and less representation disparity.
Learning in Congestion Games with Bandit Feedback
Jun 04, 2022
Learning Nash equilibria is a central problem in multi-agent systems. In this paper, we investigate congestion games, a class of games with benign theoretical structure and broad real-world applications. We first propose a centralized algorithm based on the optimism in the face of uncertainty principle for congestion games with (semi-)bandit feedback, and obtain finite-sample guarantees. Then we propose a decentralized algorithm via a novel combination of the Frank-Wolfe method and G-optimal design. By exploiting the structure of the congestion game, we show the sample complexity of both algorithms depends only polynomially on the number of players and the number of facilities, but not the size of the action set, which can be exponentially large in terms of the number of facilities. We further define a new problem class, Markov congestion games, which allows us to model the non-stationarity in congestion games. We propose a centralized algorithm for Markov congestion games, whose sample complexity again has only polynomial dependence on all relevant problem parameters, but not the size of the action set.
Decision-Dependent Risk Minimization in Geometrically Decaying Dynamic Environments
Apr 08, 2022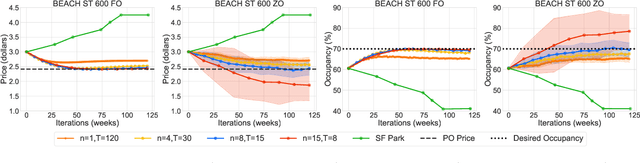

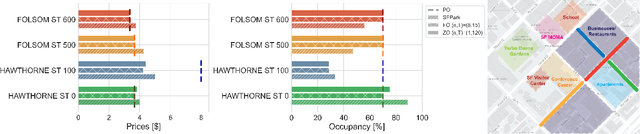
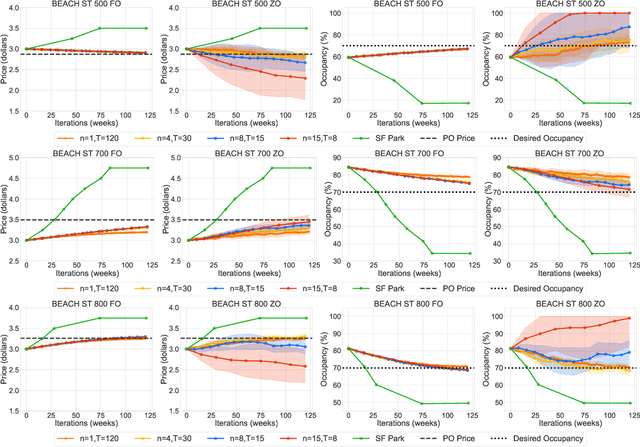
This paper studies the problem of expected loss minimization given a data distribution that is dependent on the decision-maker's action and evolves dynamically in time according to a geometric decay process. Novel algorithms for both the information setting in which the decision-maker has a first order gradient oracle and the setting in which they have simply a loss function oracle are introduced. The algorithms operate on the same underlying principle: the decision-maker repeatedly deploys a fixed decision over the length of an epoch, thereby allowing the dynamically changing environment to sufficiently mix before updating the decision. The iteration complexity in each of the settings is shown to match existing rates for first and zero order stochastic gradient methods up to logarithmic factors. The algorithms are evaluated on a "semi-synthetic" example using real world data from the SFpark dynamic pricing pilot study; it is shown that the announced prices result in an improvement for the institution's objective (target occupancy), while achieving an overall reduction in parking rates.