 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Posterior Learning: few-shot learning with a surprise-based memory module
Feb 07, 2019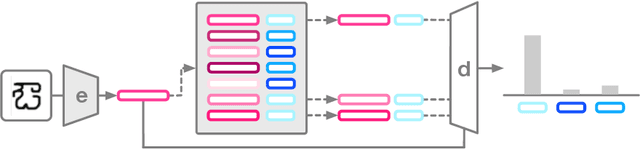
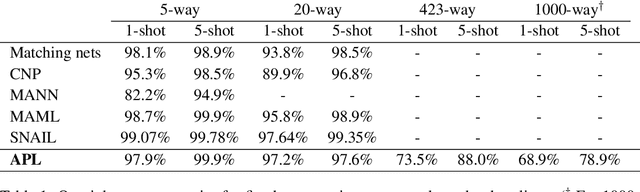

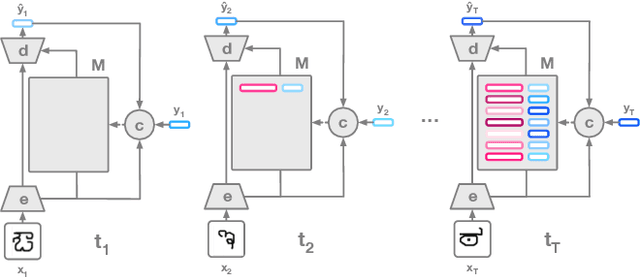
The ability to generalize quickly from few observations is crucial for intelligent systems. In this paper we introduce APL, an algorithm that approximates probability distributions by remembering the most surprising observations it has encountered. These past observations are recalled from an external memory module and processed by a decoder network that can combine information from different memory slots to generalize beyond direct recall. We show this algorithm can perform as well as state of the art baselines on few-shot classification benchmarks with a smaller memory footprint. In addition, its memory compression allows it to scale to thousands of unknown labels. Finally, we introduce a meta-learning reasoning task which is more challenging than direct classification. In this setting, APL is able to generalize with fewer than one example per class via deductive reasoning.
Open-ended Learning in Symmetric Zero-sum Games
Jan 23, 2019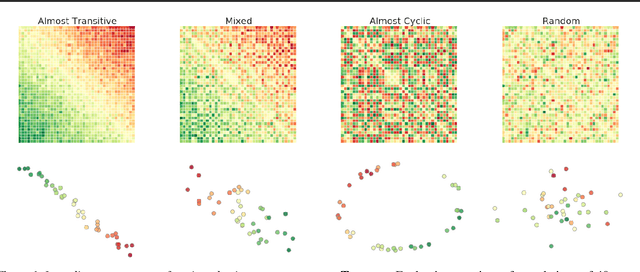
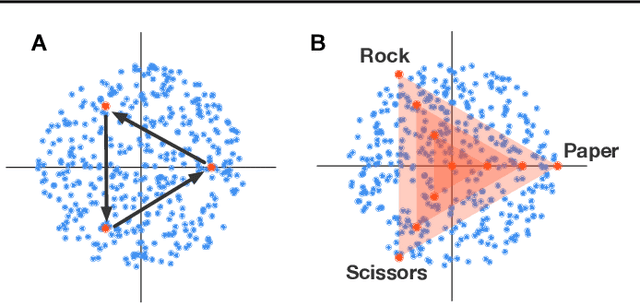
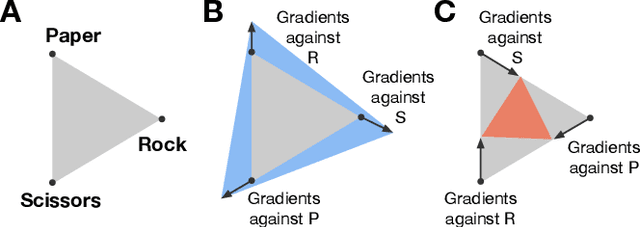
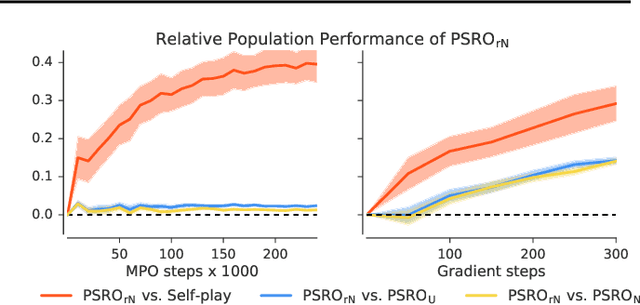
Zero-sum games such as chess and poker are, abstractly, functions that evaluate pairs of agents, for example labeling them `winner' and `loser'. If the game is approximately transitive, then self-play generates sequences of agents of increasing strength. However, nontransitive games, such as rock-paper-scissors, can exhibit strategic cycles, and there is no longer a clear objective -- we want agents to increase in strength, but against whom is unclear. In this paper, we introduce a geometric framework for formulating agent objectives in zero-sum games, in order to construct adaptive sequences of objectives that yield open-ended learning. The framework allows us to reason about population performance in nontransitive games, and enables the development of a new algorithm (rectified Nash response, PSRO_rN) that uses game-theoretic niching to construct diverse populations of effective agents, producing a stronger set of agents than existing algorithms. We apply PSRO_rN to two highly nontransitive resource allocation games and find that PSRO_rN consistently outperforms the existing alternatives.
Attentive Neural Processes
Jan 17, 2019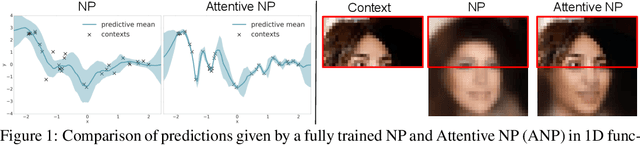
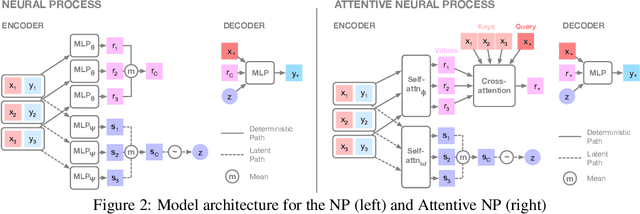
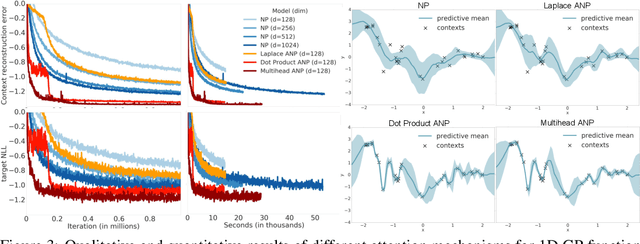
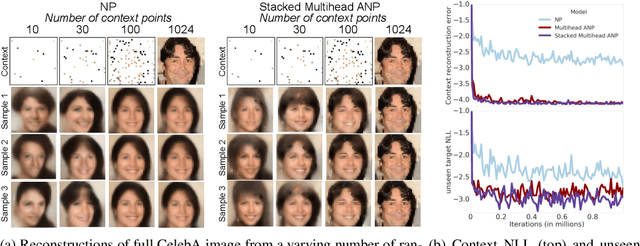
Neural Processes (NPs) (Garnelo et al 2018a;b) approach regression by learning to map a context set of observed input-output pairs to a distribution over regression functions. Each function models the distribution of the output given an input, conditioned on the context. NPs have the benefit of fitting observed data efficiently with linear complexity in the number of context input-output pairs, and can learn a wide family of conditional distributions; they learn predictive distributions conditioned on context sets of arbitrary size. Nonetheless, we show that NPs suffer a fundamental drawback of underfitting, giving inaccurate predictions at the inputs of the observed data they condition on. We address this issue by incorporating attention into NPs, allowing each input location to attend to the relevant context points for the prediction. We show that this greatly improves the accuracy of predictions, results in noticeably faster training, and expands the range of functions that can be modelled.
Verification of deep probabilistic models
Dec 06, 2018Probabilistic models are a critical part of the modern deep learning toolbox - ranging from generative models (VAEs, GANs), sequence to sequence models used in machine translation and speech processing to models over functional spaces (conditional neural processes, neural processes). Given the size and complexity of these models, safely deploying them in applications requires the development of tools to analyze their behavior rigorously and provide some guarantees that these models are consistent with a list of desirable properties or specifications. For example, a machine translation model should produce semantically equivalent outputs for innocuous changes in the input to the model. A functional regression model that is learning a distribution over monotonic functions should predict a larger value at a larger input. Verification of these properties requires a new framework that goes beyond notions of verification studied in deterministic feedforward networks, since requiring worst-case guarantees in probabilistic models is likely to produce conservative or vacuous results. We propose a novel formulation of verification for deep probabilistic models that take in conditioning inputs and sample latent variables in the course of producing an output: We require that the output of the model satisfies a linear constraint with high probability over the sampling of latent variables and for every choice of conditioning input to the model. We show that rigorous lower bounds on the probability that the constraint is satisfied can be obtained efficiently. Experiments with neural processes show that several properties of interest while modeling functional spaces can be modeled within this framework (monotonicity, convexity) and verified efficiently using our algorithms
Consistent Jumpy Predictions for Videos and Scenes
Oct 02, 2018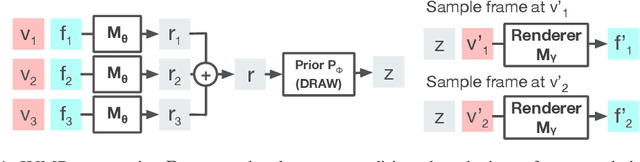
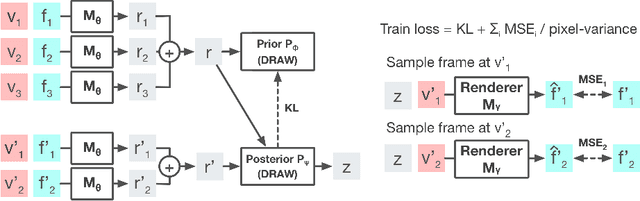


Stochastic video prediction models take in a sequence of image frames, and generate a sequence of consecutive future image frames. These models typically generate future frames in an autoregressive fashion, which is slow and requires the input and output frames to be consecutive. We introduce a model that overcomes these drawbacks by generating a latent representation from an arbitrary set of frames that can then be used to simultaneously and efficiently sample temporally consistent frames at arbitrary time-points. For example, our model can "jump" and directly sample frames at the end of the video, without sampling intermediate frames. Synthetic video evaluations confirm substantial gains in speed and functionality without loss in fidelity. We also apply our framework to a 3D scene reconstruction dataset. Here, our model is conditioned on camera location and can sample consistent sets of images for what an occluded region of a 3D scene might look like, even if there are multiple possibilities for what that region might contain. Reconstructions and videos are available at https://bit.ly/2O4Pc4R.
Neural Processes
Jul 04, 2018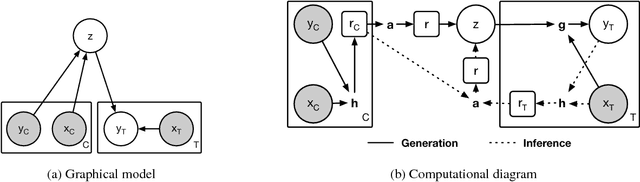

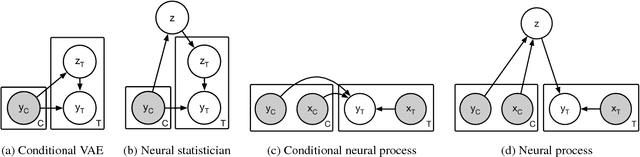
A neural network (NN) is a parameterised function that can be tuned via gradient descent to approximate a labelled collection of data with high precision. A Gaussian process (GP), on the other hand, is a probabilistic model that defines a distribution over possible functions, and is updated in light of data via the rules of probabilistic inference. GPs are probabilistic, data-efficient and flexible, however they are also computationally intensive and thus limited in their applicability. We introduce a class of neural latent variable models which we call Neural Processes (NPs), combining the best of both worlds. Like GPs, NPs define distributions over functions, are capable of rapid adaptation to new observations, and can estimate the uncertainty in their predictions. Like NNs, NPs are computationally efficient during training and evaluation but also learn to adapt their priors to data. We demonstrate the performance of NPs on a range of learning tasks, including regression and optimisation, and compare and contrast with related models in the literature.
Conditional Neural Processes
Jul 04, 2018



Deep neural networks excel at function approximation, yet they are typically trained from scratch for each new function. On the other hand, Bayesian methods, such as Gaussian Processes (GPs), exploit prior knowledge to quickly infer the shape of a new function at test time. Yet GPs are computationally expensive, and it can be hard to design appropriate priors. In this paper we propose a family of neural models, Conditional Neural Processes (CNPs), that combine the benefits of both. CNPs are inspired by the flexibility of stochastic processes such as GPs, but are structured as neural networks and trained via gradient descent. CNPs make accurate predictions after observing only a handful of training data points, yet scale to complex functions and large datasets. We demonstrate the performance and versatility of the approach on a range of canonical machine learning tasks, including regression, classification and image completion.
Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders
Jan 13, 2017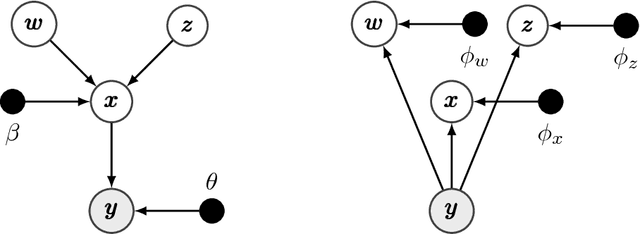
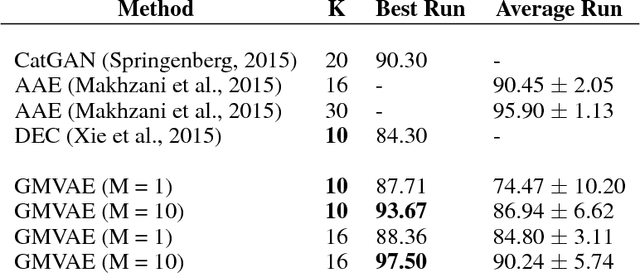
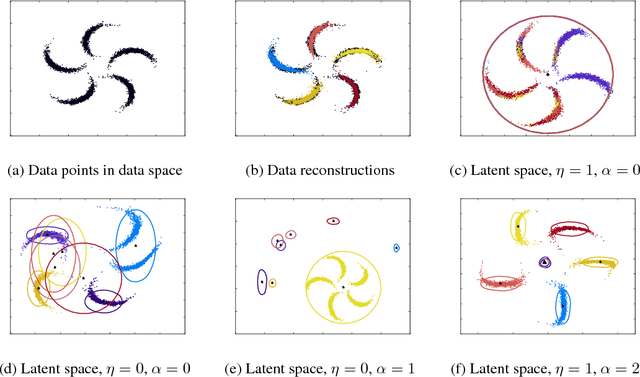

We study a variant of the variational autoencoder model (VAE) with a Gaussian mixture as a prior distribution, with the goal of performing unsupervised clustering through deep generative models. We observe that the known problem of over-regularisation that has been shown to arise in regular VAEs also manifests itself in our model and leads to cluster degeneracy. We show that a heuristic called minimum information constraint that has been shown to mitigate this effect in VAEs can also be applied to improve unsupervised clustering performance with our model. Furthermore we analyse the effect of this heuristic and provide an intuition of the various processes with the help of visualizations. Finally, we demonstrate the performance of our model on synthetic data, MNIST and SVHN, showing that the obtained clusters are distinct, interpretable and result in achieving competitive performance on unsupervised clustering to the state-of-the-art results.
Towards Deep Symbolic Reinforcement Learning
Oct 01, 2016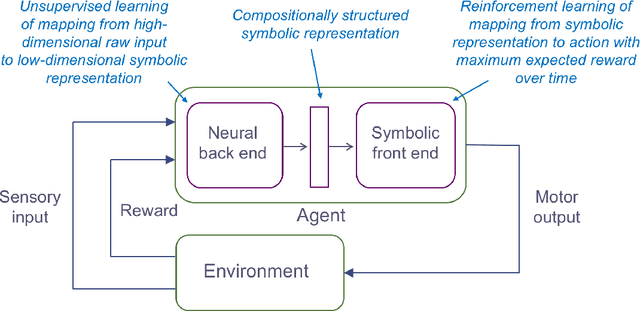

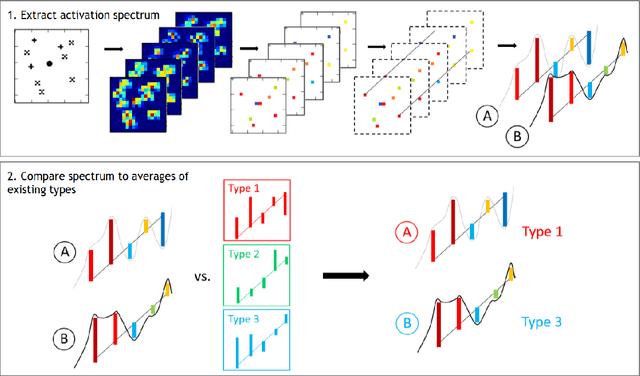
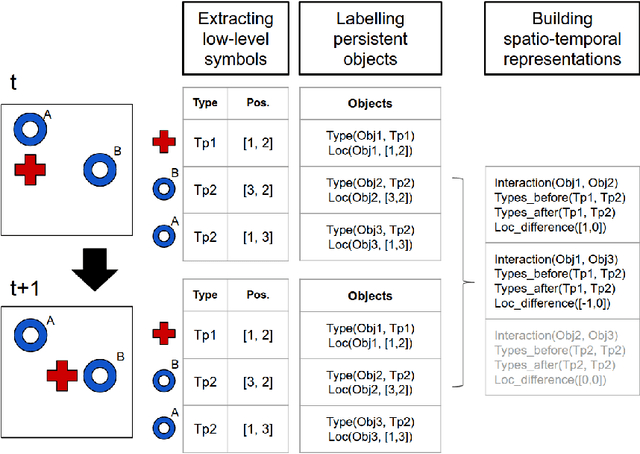
Deep reinforcement learning (DRL) brings the power of deep neural networks to bear on the generic task of trial-and-error learning, and its effectiveness has been convincingly demonstrated on tasks such as Atari video games and the game of Go. However, contemporary DRL systems inherit a number of shortcomings from the current generation of deep learning techniques. For example, they require very large datasets to work effectively, entailing that they are slow to learn even when such datasets are available. Moreover, they lack the ability to reason on an abstract level, which makes it difficult to implement high-level cognitive functions such as transfer learning, analogical reasoning, and hypothesis-based reasoning. Finally, their operation is largely opaque to humans, rendering them unsuitable for domains in which verifiability is important. In this paper, we propose an end-to-end reinforcement learning architecture comprising a neural back end and a symbolic front end with the potential to overcome each of these shortcomings. As proof-of-concept, we present a preliminary implementation of the architecture and apply it to several variants of a simple video game. We show that the resulting system -- though just a prototype -- learns effectively, and, by acquiring a set of symbolic rules that are easily comprehensible to humans, dramatically outperforms a conventional, fully neural DRL system on a stochastic variant of the game.