 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Correlated Equilibria in Mean-Field Games
Aug 22, 2022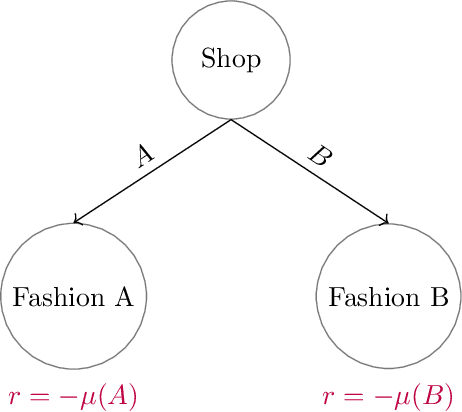
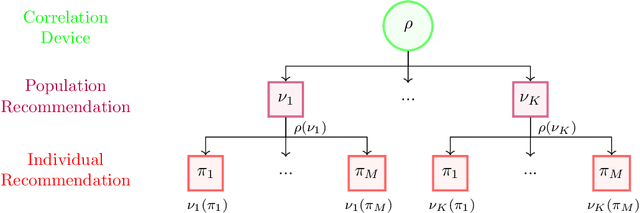
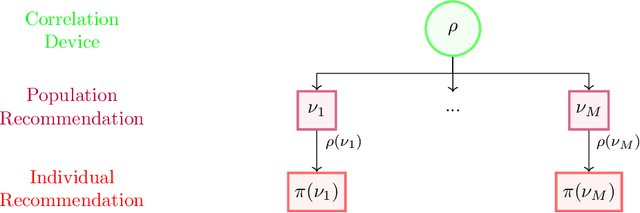
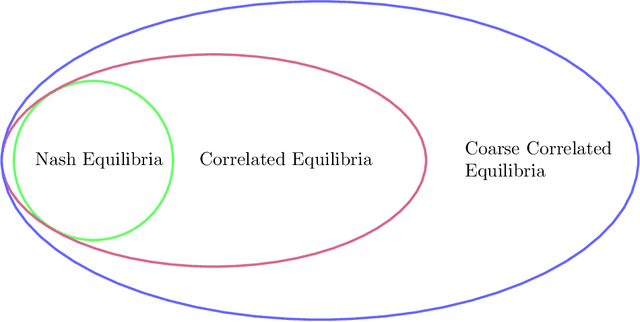
The designs of many large-scale systems today, from traffic routing environments to smart grids, rely on game-theoretic equilibrium concepts. However, as the size of an $N$-player game typically grows exponentially with $N$, standard game theoretic analysis becomes effectively infeasible beyond a low number of players. Recent approaches have gone around this limitation by instead considering Mean-Field games, an approximation of anonymous $N$-player games, where the number of players is infinite and the population's state distribution, instead of every individual player's state, is the object of interest. The practical computability of Mean-Field Nash equilibria, the most studied Mean-Field equilibrium to date, however, typically depends on beneficial non-generic structural properties such as monotonicity or contraction properties, which are required for known algorithms to converge. In this work, we provide an alternative route for studying Mean-Field games, by developing the concepts of Mean-Field correlated and coarse-correlated equilibria. We show that they can be efficiently learnt in \emph{all games}, without requiring any additional assumption on the structure of the game, using three classical algorithms. Furthermore, we establish correspondences between our notions and those already present in the literature, derive optimality bounds for the Mean-Field - $N$-player transition, and empirically demonstrate the convergence of these algorithms on simple games.
The Nature of Temporal Difference Errors in Multi-step Distributional Reinforcement Learning
Jul 15, 2022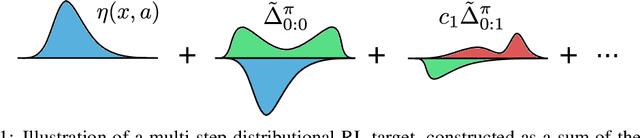
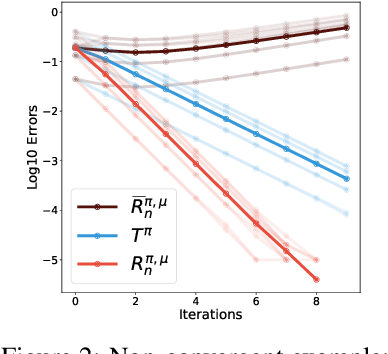
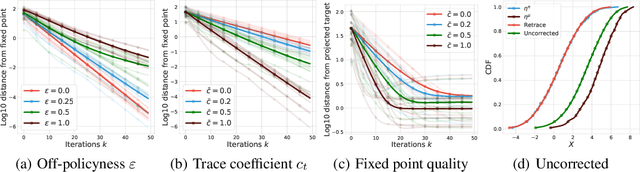
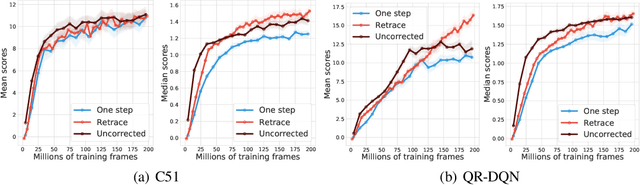
We study the multi-step off-policy learning approach to distributional RL. Despite the apparent similarity between value-based RL and distributional RL, our study reveals intriguing and fundamental differences between the two cases in the multi-step setting. We identify a novel notion of path-dependent distributional TD error, which is indispensable for principled multi-step distributional RL. The distinction from the value-based case bears important implications on concepts such as backward-view algorithms. Our work provides the first theoretical guarantees on multi-step off-policy distributional RL algorithms, including results that apply to the small number of existing approaches to multi-step distributional RL. In addition, we derive a novel algorithm, Quantile Regression-Retrace, which leads to a deep RL agent QR-DQN-Retrace that shows empirical improvements over QR-DQN on the Atari-57 benchmark. Collectively, we shed light on how unique challenges in multi-step distributional RL can be addressed both in theory and practice.
Mastering the Game of Stratego with Model-Free Multiagent Reinforcement Learning
Jun 30, 2022
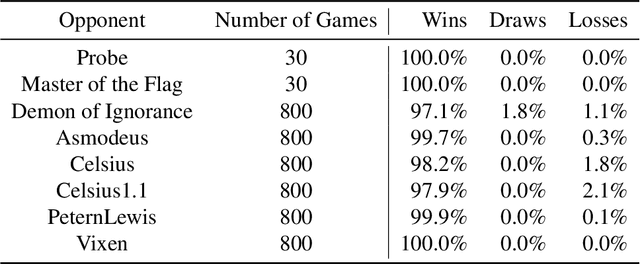
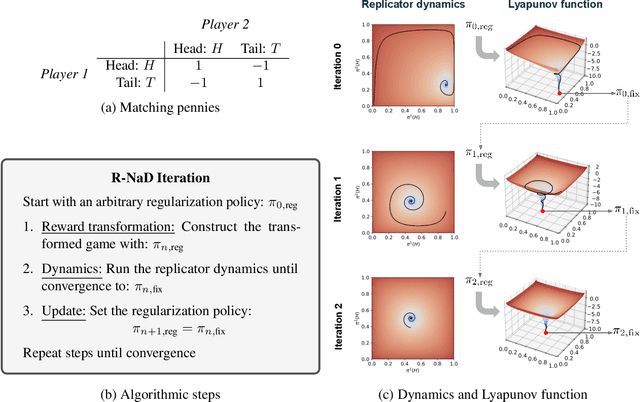

We introduce DeepNash, an autonomous agent capable of learning to play the imperfect information game Stratego from scratch, up to a human expert level. Stratego is one of the few iconic board games that Artificial Intelligence (AI) has not yet mastered. This popular game has an enormous game tree on the order of $10^{535}$ nodes, i.e., $10^{175}$ times larger than that of Go. It has the additional complexity of requiring decision-making under imperfect information, similar to Texas hold'em poker, which has a significantly smaller game tree (on the order of $10^{164}$ nodes). Decisions in Stratego are made over a large number of discrete actions with no obvious link between action and outcome. Episodes are long, with often hundreds of moves before a player wins, and situations in Stratego can not easily be broken down into manageably-sized sub-problems as in poker. For these reasons, Stratego has been a grand challenge for the field of AI for decades, and existing AI methods barely reach an amateur level of play. DeepNash uses a game-theoretic, model-free deep reinforcement learning method, without search, that learns to master Stratego via self-play. The Regularised Nash Dynamics (R-NaD) algorithm, a key component of DeepNash, converges to an approximate Nash equilibrium, instead of 'cycling' around it, by directly modifying the underlying multi-agent learning dynamics. DeepNash beats existing state-of-the-art AI methods in Stratego and achieved a yearly (2022) and all-time top-3 rank on the Gravon games platform, competing with human expert players.
Generalised Policy Improvement with Geometric Policy Composition
Jun 17, 2022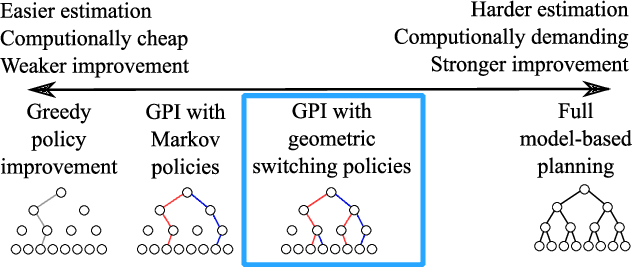

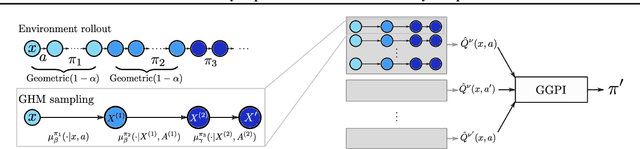
We introduce a method for policy improvement that interpolates between the greedy approach of value-based reinforcement learning (RL) and the full planning approach typical of model-based RL. The new method builds on the concept of a geometric horizon model (GHM, also known as a gamma-model), which models the discounted state-visitation distribution of a given policy. We show that we can evaluate any non-Markov policy that switches between a set of base Markov policies with fixed probability by a careful composition of the base policy GHMs, without any additional learning. We can then apply generalised policy improvement (GPI) to collections of such non-Markov policies to obtain a new Markov policy that will in general outperform its precursors. We provide a thorough theoretical analysis of this approach, develop applications to transfer and standard RL, and empirically demonstrate its effectiveness over standard GPI on a challenging deep RL continuous control task. We also provide an analysis of GHM training methods, proving a novel convergence result regarding previously proposed methods and showing how to train these models stably in deep RL settings.
Learning Dynamics and Generalization in Reinforcement Learning
Jun 05, 2022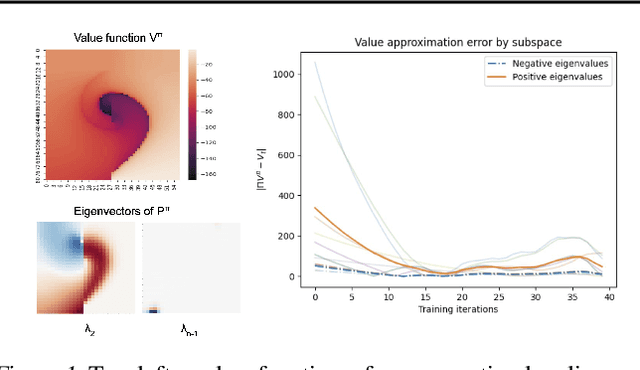
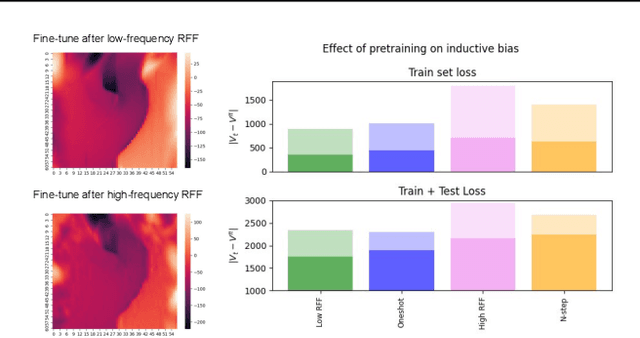
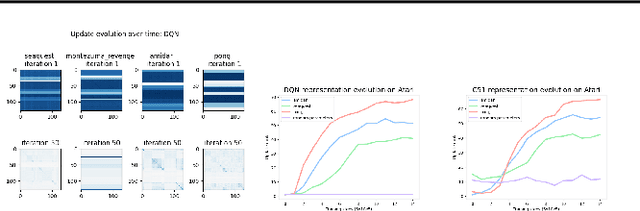
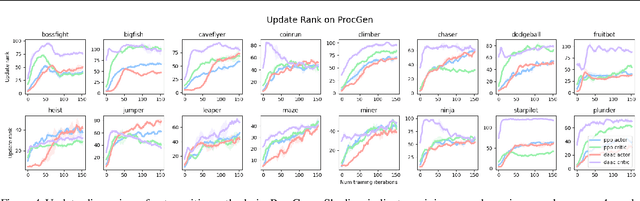
Solving a reinforcement learning (RL) problem poses two competing challenges: fitting a potentially discontinuous value function, and generalizing well to new observations. In this paper, we analyze the learning dynamics of temporal difference algorithms to gain novel insight into the tension between these two objectives. We show theoretically that temporal difference learning encourages agents to fit non-smooth components of the value function early in training, and at the same time induces the second-order effect of discouraging generalization. We corroborate these findings in deep RL agents trained on a range of environments, finding that neural networks trained using temporal difference algorithms on dense reward tasks exhibit weaker generalization between states than randomly initialized networks and networks trained with policy gradient methods. Finally, we investigate how post-training policy distillation may avoid this pitfall, and show that this approach improves generalization to novel environments in the ProcGen suite and improves robustness to input perturbations.
Understanding and Preventing Capacity Loss in Reinforcement Learning
Apr 20, 2022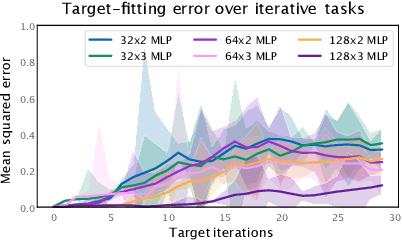
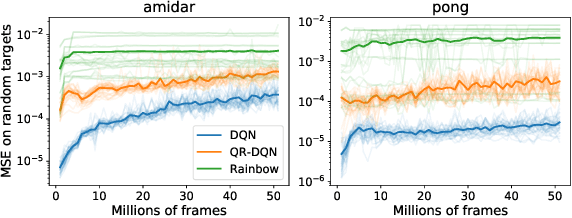

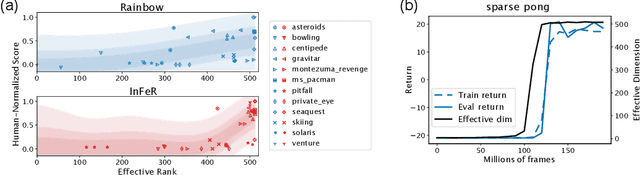
The reinforcement learning (RL) problem is rife with sources of non-stationarity, making it a notoriously difficult problem domain for the application of neural networks. We identify a mechanism by which non-stationary prediction targets can prevent learning progress in deep RL agents: \textit{capacity loss}, whereby networks trained on a sequence of target values lose their ability to quickly update their predictions over time. We demonstrate that capacity loss occurs in a range of RL agents and environments, and is particularly damaging to performance in sparse-reward tasks. We then present a simple regularizer, Initial Feature Regularization (InFeR), that mitigates this phenomenon by regressing a subspace of features towards its value at initialization, leading to significant performance improvements in sparse-reward environments such as Montezuma's Revenge. We conclude that preventing capacity loss is crucial to enable agents to maximally benefit from the learning signals they obtain throughout the entire training trajectory.
Marginalized Operators for Off-policy Reinforcement Learning
Mar 30, 2022
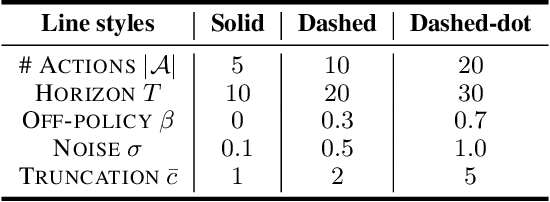
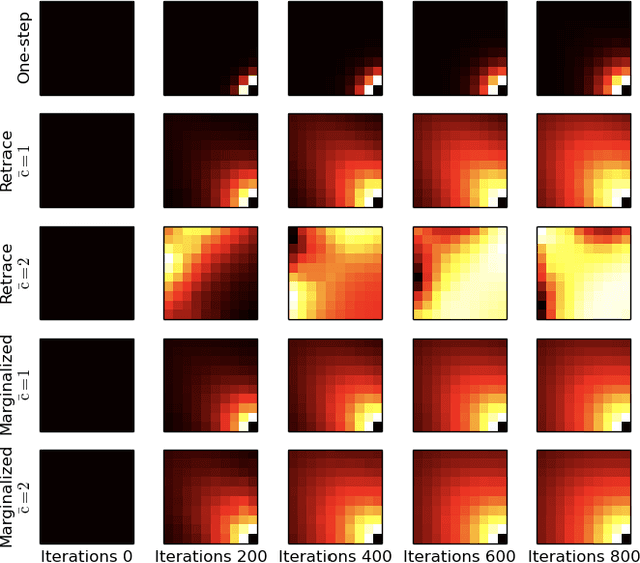
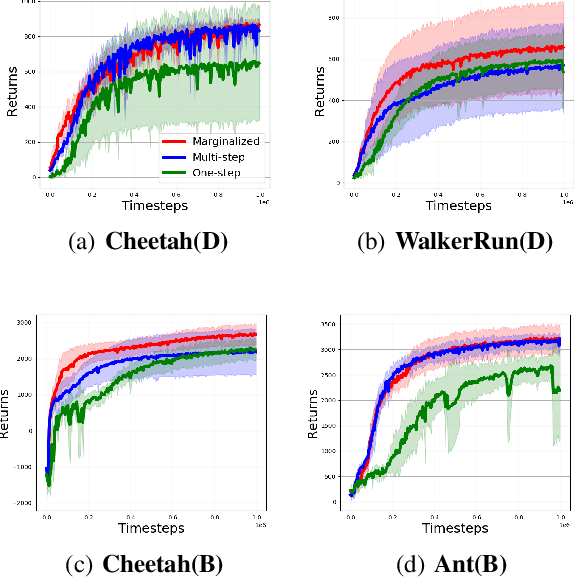
In this work, we propose marginalized operators, a new class of off-policy evaluation operators for reinforcement learning. Marginalized operators strictly generalize generic multi-step operators, such as Retrace, as special cases. Marginalized operators also suggest a form of sample-based estimates with potential variance reduction, compared to sample-based estimates of the original multi-step operators. We show that the estimates for marginalized operators can be computed in a scalable way, which also generalizes prior results on marginalized importance sampling as special cases. Finally, we empirically demonstrate that marginalized operators provide performance gains to off-policy evaluation and downstream policy optimization algorithms.
Evolutionary Dynamics and $Φ$-Regret Minimization in Games
Jun 28, 2021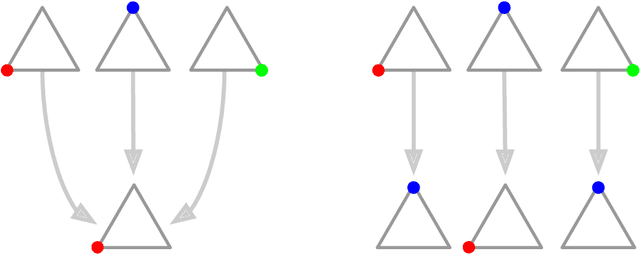
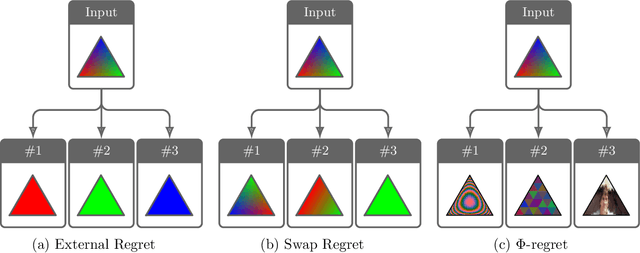
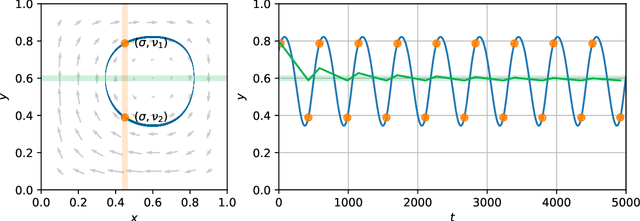
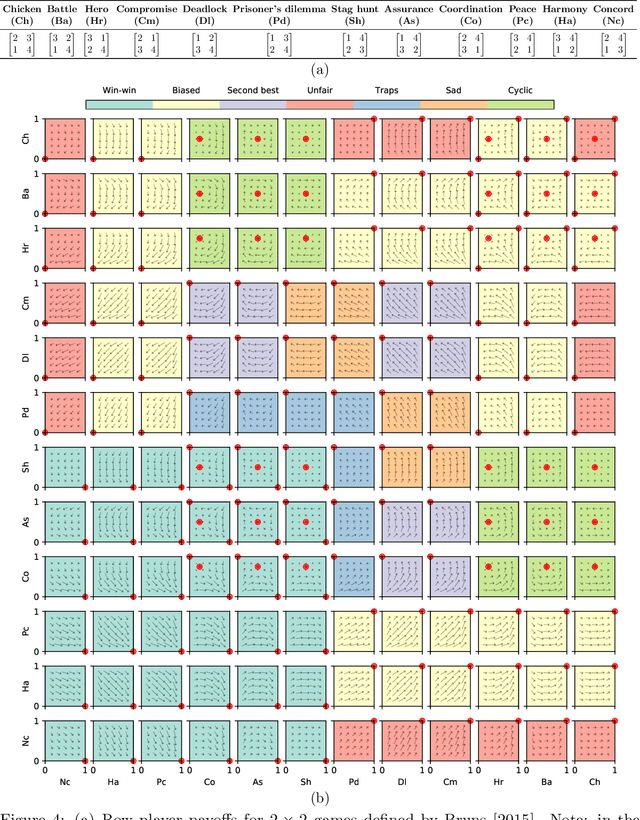
Regret has been established as a foundational concept in online learning, and likewise has important applications in the analysis of learning dynamics in games. Regret quantifies the difference between a learner's performance against a baseline in hindsight. It is well-known that regret-minimizing algorithms converge to certain classes of equilibria in games; however, traditional forms of regret used in game theory predominantly consider baselines that permit deviations to deterministic actions or strategies. In this paper, we revisit our understanding of regret from the perspective of deviations over partitions of the full \emph{mixed} strategy space (i.e., probability distributions over pure strategies), under the lens of the previously-established $\Phi$-regret framework, which provides a continuum of stronger regret measures. Importantly, $\Phi$-regret enables learning agents to consider deviations from and to mixed strategies, generalizing several existing notions of regret such as external, internal, and swap regret, and thus broadening the insights gained from regret-based analysis of learning algorithms. We prove here that the well-studied evolutionary learning algorithm of replicator dynamics (RD) seamlessly minimizes the strongest possible form of $\Phi$-regret in generic $2 \times 2$ games, without any modification of the underlying algorithm itself. We subsequently conduct experiments validating our theoretical results in a suite of 144 $2 \times 2$ games wherein RD exhibits a diverse set of behaviors. We conclude by providing empirical evidence of $\Phi$-regret minimization by RD in some larger games, hinting at further opportunity for $\Phi$-regret based study of such algorithms from both a theoretical and empirical perspective.
Unifying Gradient Estimators for Meta-Reinforcement Learning via Off-Policy Evaluation
Jun 24, 2021
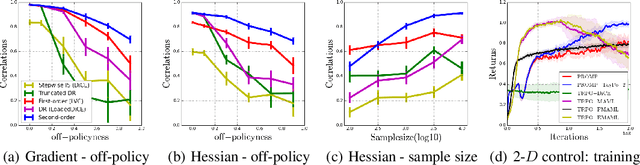
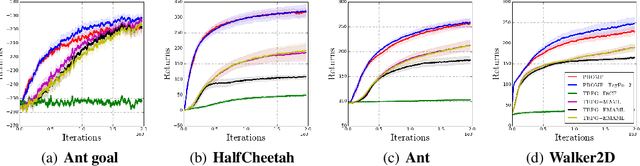

Model-agnostic meta-reinforcement learning requires estimating the Hessian matrix of value functions. This is challenging from an implementation perspective, as repeatedly differentiating policy gradient estimates may lead to biased Hessian estimates. In this work, we provide a unifying framework for estimating higher-order derivatives of value functions, based on off-policy evaluation. Our framework interprets a number of prior approaches as special cases and elucidates the bias and variance trade-off of Hessian estimates. This framework also opens the door to a new family of estimates, which can be easily implemented with auto-differentiation libraries, and lead to performance gains in practice.
Taylor Expansion of Discount Factors
Jun 14, 2021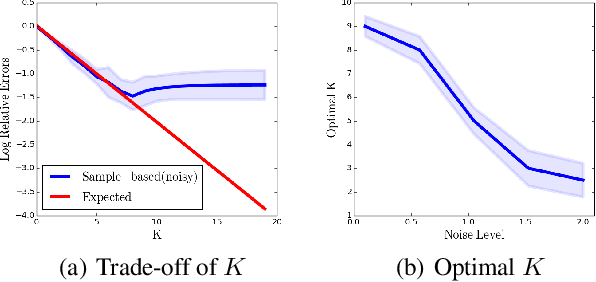
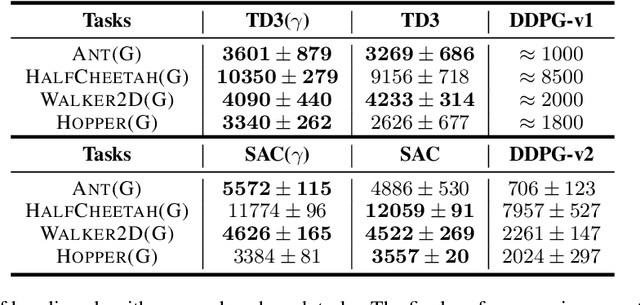
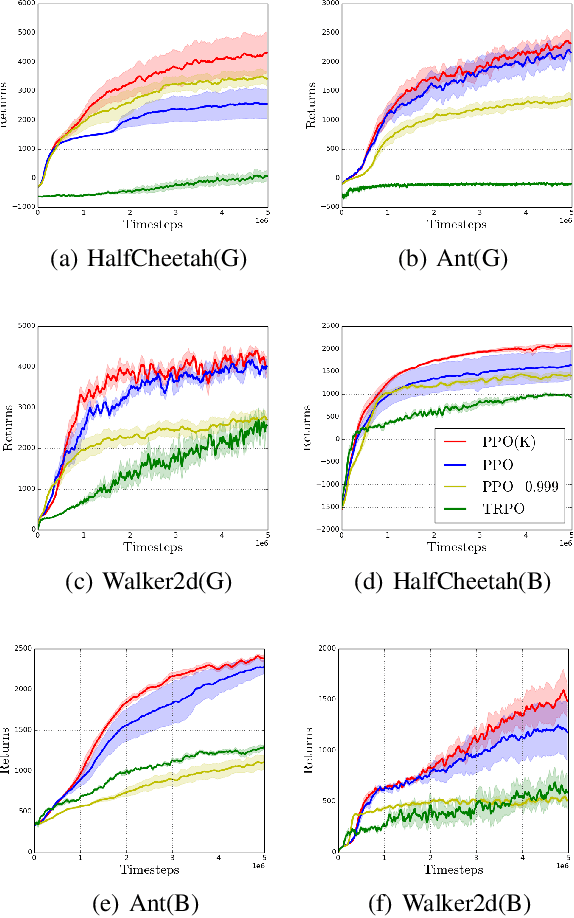
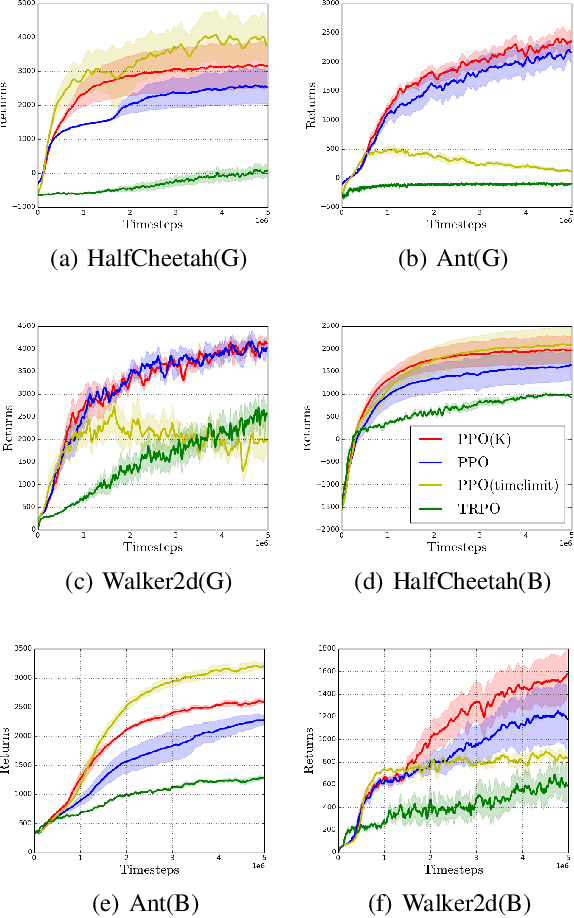
In practical reinforcement learning (RL), the discount factor used for estimating value functions often differs from that used for defining the evaluation objective. In this work, we study the effect that this discrepancy of discount factors has during learning, and discover a family of objectives that interpolate value functions of two distinct discount factors. Our analysis suggests new ways for estimating value functions and performing policy optimization updates, which demonstrate empirical performance gains. This framework also leads to new insights on commonly-used deep RL heuristic modifications to policy optimization algorithms.