 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSD-2: Scaling and Inference-time Fusion of Diffusion Language Models
May 24, 2023Diffusion-based language models (LMs) have been shown to be competent generative models that are easy to control at inference and are a promising alternative to autoregressive LMs. While autoregressive LMs have benefited immensely from scaling and instruction-based learning, existing studies on diffusion LMs have been conducted on a relatively smaller scale. Starting with a recently proposed diffusion model SSD-LM, in this work we explore methods to scale it from 0.4B to 13B parameters, proposing several techniques to improve its training and inference efficiency. We call the new model SSD-2. We further show that this model can be easily finetuned to follow instructions. Finally, leveraging diffusion models' capability at inference-time control, we show that SSD-2 facilitates novel ensembles with 100x smaller models that can be customized and deployed by individual users. We find that compared to autoregressive models, the collaboration between diffusion models is more effective, leading to higher-quality and more relevant model responses due to their ability to incorporate bi-directional contexts.
Dictionary-based Phrase-level Prompting of Large Language Models for Machine Translation
Feb 15, 2023



Large language models (LLMs) demonstrate remarkable machine translation (MT) abilities via prompting, even though they were not explicitly trained for this task. However, even given the incredible quantities of data they are trained on, LLMs can struggle to translate inputs with rare words, which are common in low resource or domain transfer scenarios. We show that LLM prompting can provide an effective solution for rare words as well, by using prior knowledge from bilingual dictionaries to provide control hints in the prompts. We propose a novel method, DiPMT, that provides a set of possible translations for a subset of the input words, thereby enabling fine-grained phrase-level prompted control of the LLM. Extensive experiments show that DiPMT outperforms the baseline both in low-resource MT, as well as for out-of-domain MT. We further provide a qualitative analysis of the benefits and limitations of this approach, including the overall level of controllability that is achieved.
Representation Deficiency in Masked Language Modeling
Feb 04, 2023



Masked Language Modeling (MLM) has been one of the most prominent approaches for pretraining bidirectional text encoders due to its simplicity and effectiveness. One notable concern about MLM is that the special $\texttt{[MASK]}$ symbol causes a discrepancy between pretraining data and downstream data as it is present only in pretraining but not in fine-tuning. In this work, we offer a new perspective on the consequence of such a discrepancy: We demonstrate empirically and theoretically that MLM pretraining allocates some model dimensions exclusively for representing $\texttt{[MASK]}$ tokens, resulting in a representation deficiency for real tokens and limiting the pretrained model's expressiveness when it is adapted to downstream data without $\texttt{[MASK]}$ tokens. Motivated by the identified issue, we propose MAE-LM, which pretrains the Masked Autoencoder architecture with MLM where $\texttt{[MASK]}$ tokens are excluded from the encoder. Empirically, we show that MAE-LM improves the utilization of model dimensions for real token representations, and MAE-LM consistently outperforms MLM-pretrained models across different pretraining settings and model sizes when fine-tuned on the GLUE and SQuAD benchmarks.
XLM-V: Overcoming the Vocabulary Bottleneck in Multilingual Masked Language Models
Jan 25, 2023



Large multilingual language models typically rely on a single vocabulary shared across 100+ languages. As these models have increased in parameter count and depth, vocabulary size has remained largely unchanged. This vocabulary bottleneck limits the representational capabilities of multilingual models like XLM-R. In this paper, we introduce a new approach for scaling to very large multilingual vocabularies by de-emphasizing token sharing between languages with little lexical overlap and assigning vocabulary capacity to achieve sufficient coverage for each individual language. Tokenizations using our vocabulary are typically more semantically meaningful and shorter compared to XLM-R. Leveraging this improved vocabulary, we train XLM-V, a multilingual language model with a one million token vocabulary. XLM-V outperforms XLM-R on every task we tested on ranging from natural language inference (XNLI), question answering (MLQA, XQuAD, TyDiQA), and named entity recognition (WikiAnn) to low-resource tasks (Americas NLI, MasakhaNER).
In-context Examples Selection for Machine Translation
Dec 05, 2022



Large-scale generative models show an impressive ability to perform a wide range of Natural Language Processing (NLP) tasks using in-context learning, where a few examples are used to describe a task to the model. For Machine Translation (MT), these examples are typically randomly sampled from the development dataset with a similar distribution as the evaluation set. However, it is unclear how the choice of these in-context examples and their ordering impacts the output translation quality. In this work, we aim to understand the properties of good in-context examples for MT in both in-domain and out-of-domain settings. We show that the translation quality and the domain of the in-context examples matter and that 1-shot noisy unrelated example can have a catastrophic impact on output quality. While concatenating multiple random examples reduces the effect of noise, a single good prompt optimized to maximize translation quality on the development dataset can elicit learned information from the pre-trained language model. Adding similar examples based on an n-gram overlap with the test source significantly and consistently improves the translation quality of the outputs, outperforming a strong kNN-MT baseline in 2 out of 4 out-of-domain datasets.
Natural Language to Code Translation with Execution
Apr 25, 2022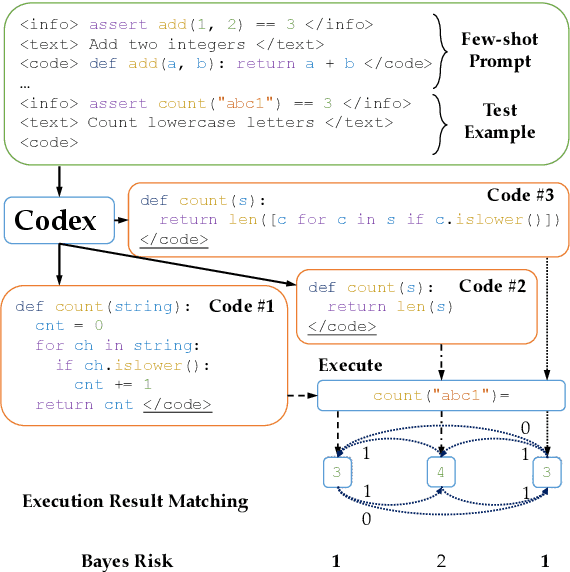

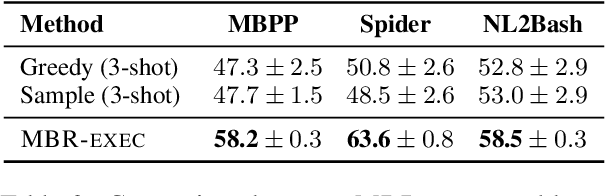
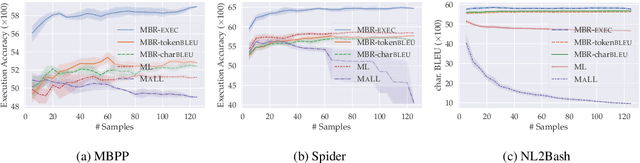
Generative models of code, pretrained on large corpora of programs, have shown great success in translating natural language to code (Chen et al., 2021; Austin et al., 2021; Li et al., 2022, inter alia). While these models do not explicitly incorporate program semantics (i.e., execution results) during training, they are able to generate correct solutions for many problems. However, choosing a single correct program from among a generated set for each problem remains challenging. In this work, we introduce execution result--based minimum Bayes risk decoding (MBR-EXEC) for program selection and show that it improves the few-shot performance of pretrained code models on natural-language-to-code tasks. We select output programs from a generated candidate set by marginalizing over program implementations that share the same semantics. Because exact equivalence is intractable, we execute each program on a small number of test inputs to approximate semantic equivalence. Across datasets, execution or simulated execution significantly outperforms the methods that do not involve program semantics. We find that MBR-EXEC consistently improves over all execution-unaware selection methods, suggesting it as an effective approach for natural language to code translation.
A Review on Language Models as Knowledge Bases
Apr 12, 2022
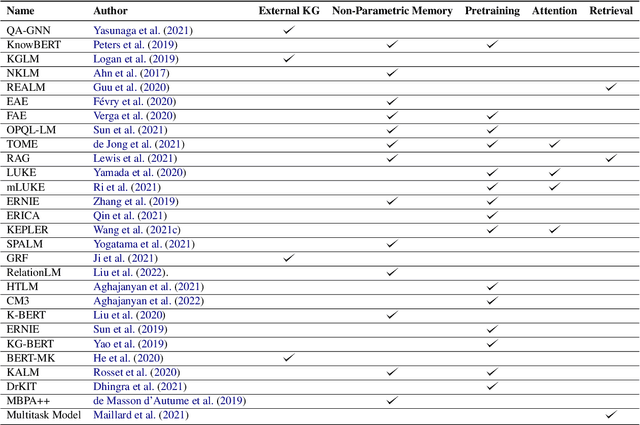
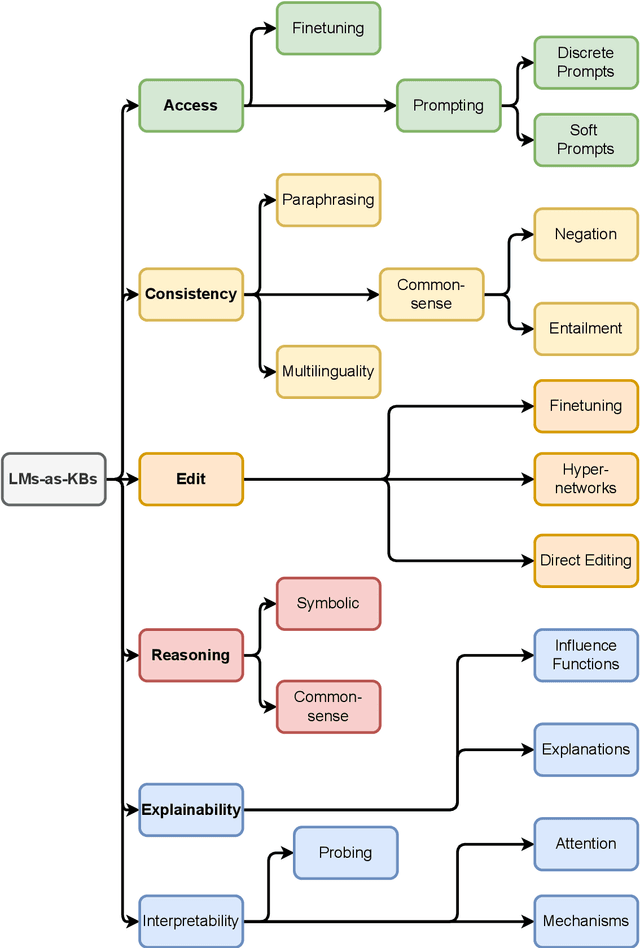
Recently, there has been a surge of interest in the NLP community on the use of pretrained Language Models (LMs) as Knowledge Bases (KBs). Researchers have shown that LMs trained on a sufficiently large (web) corpus will encode a significant amount of knowledge implicitly in its parameters. The resulting LM can be probed for different kinds of knowledge and thus acting as a KB. This has a major advantage over traditional KBs in that this method requires no human supervision. In this paper, we present a set of aspects that we deem a LM should have to fully act as a KB, and review the recent literature with respect to those aspects.
Discourse-Aware Prompt Design for Text Generation
Dec 10, 2021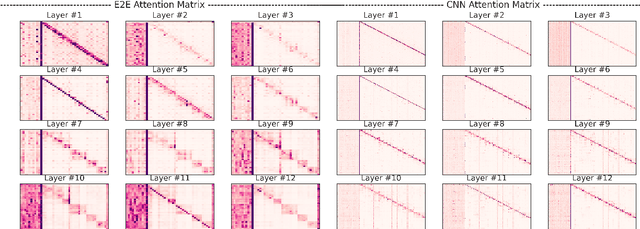
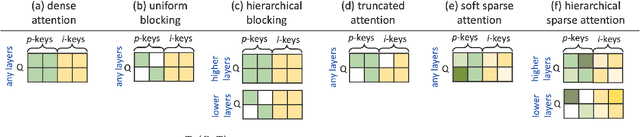

Current efficient fine-tuning methods (e.g., adapters, prefix-tuning, etc.) have optimized conditional text generation via training a small set of extra parameters of the neural language model, while freezing the rest for efficiency. While showing strong performance on some generation tasks, they don't generalize across all generation tasks. In this work, we show that prompt based conditional text generation can be improved with simple and efficient methods that simulate modeling the discourse structure of human written text. We introduce two key design choices: First we show that a higher-level discourse structure of human written text can be modelled with \textit{hierarchical blocking} on prefix parameters that enable spanning different parts of the input and output text and yield more coherent output generations. Second, we propose sparse prefix tuning by introducing \textit{attention sparsity} on the prefix parameters at different layers of the network and learn sparse transformations on the softmax-function, respectively. We find that sparse attention enables the prefix-tuning to better control of the input contents (salient facts) yielding more efficient tuning of the prefix-parameters. Experiments on a wide-variety of text generation tasks show that structured design of prefix parameters can achieve comparable results to fine-tuning all parameters while outperforming standard prefix-tuning on all generation tasks even in low-resource settings.
BitextEdit: Automatic Bitext Editing for Improved Low-Resource Machine Translation
Nov 12, 2021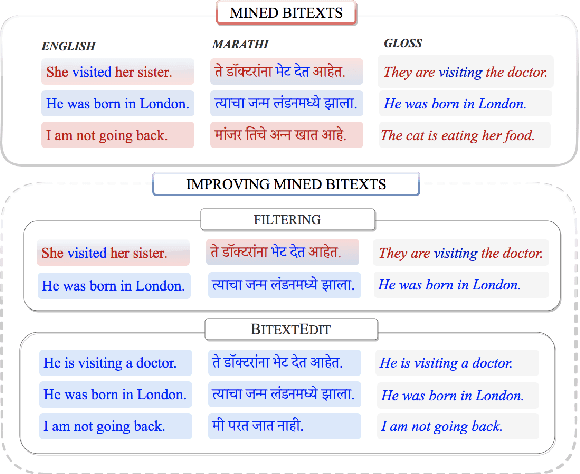
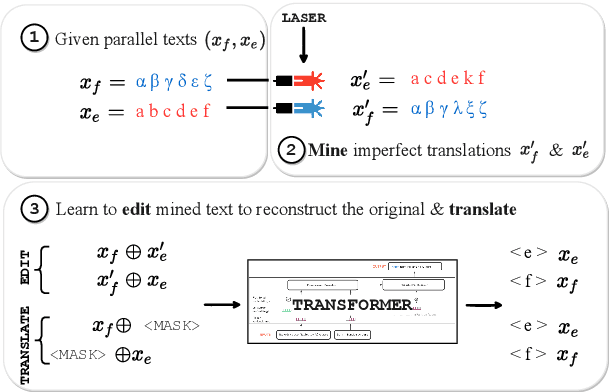
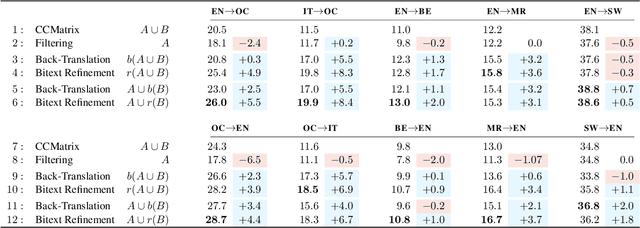
Mined bitexts can contain imperfect translations that yield unreliable training signals for Neural Machine Translation (NMT). While filtering such pairs out is known to improve final model quality, we argue that it is suboptimal in low-resource conditions where even mined data can be limited. In our work, we propose instead, to refine the mined bitexts via automatic editing: given a sentence in a language xf, and a possibly imperfect translation of it xe, our model generates a revised version xf' or xe' that yields a more equivalent translation pair (i.e., <xf, xe'> or <xf', xe>). We use a simple editing strategy by (1) mining potentially imperfect translations for each sentence in a given bitext, (2) learning a model to reconstruct the original translations and translate, in a multi-task fashion. Experiments demonstrate that our approach successfully improves the quality of CCMatrix mined bitext for 5 low-resource language-pairs and 10 translation directions by up to ~ 8 BLEU points, in most cases improving upon a competitive back-translation baseline.
Distributionally Robust Multilingual Machine Translation
Sep 09, 2021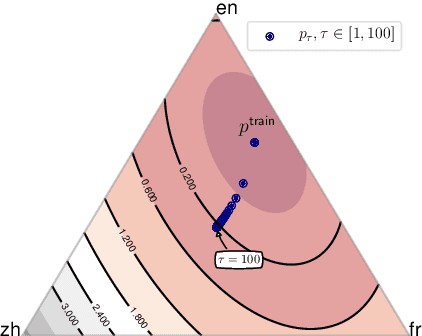
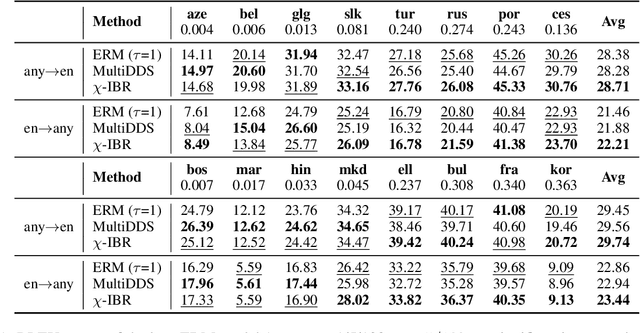
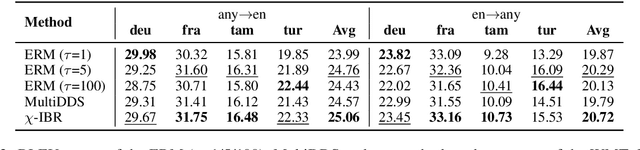
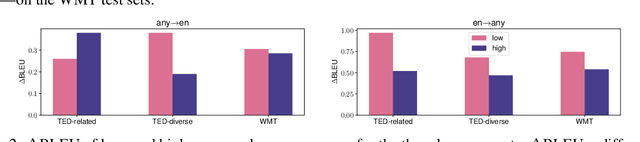
Multilingual neural machine translation (MNMT) learns to translate multiple language pairs with a single model, potentially improving both the accuracy and the memory-efficiency of deployed models. However, the heavy data imbalance between languages hinders the model from performing uniformly across language pairs. In this paper, we propose a new learning objective for MNMT based on distributionally robust optimization, which minimizes the worst-case expected loss over the set of language pairs. We further show how to practically optimize this objective for large translation corpora using an iterated best response scheme, which is both effective and incurs negligible additional computational cost compared to standard empirical risk minimization. We perform extensive experiments on three sets of languages from two datasets and show that our method consistently outperforms strong baseline methods in terms of average and per-language performance under both many-to-one and one-to-many translation settings.