 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Biases Shift as Inputs Approach Context Window Limits
Paper and Code
Aug 10, 2025


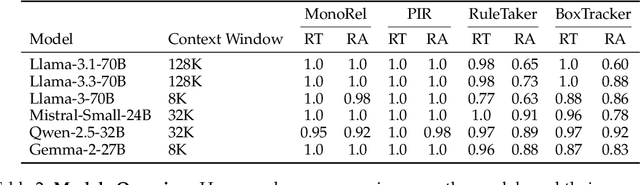
Large Language Models (LLMs) often struggle to use information across long inputs effectively. Prior work has identified positional biases, such as the Lost in the Middle (LiM) effect, where models perform better when information appears at the beginning (primacy bias) or end (recency bias) of the input, rather than in the middle. However, long-context studies have not consistently replicated these effects, raising questions about their intensity and the conditions under which they manifest. To address this, we conducted a comprehensive analysis using relative rather than absolute input lengths, defined with respect to each model's context window. Our findings reveal that the LiM effect is strongest when inputs occupy up to 50% of a model's context window. Beyond that, the primacy bias weakens, while recency bias remains relatively stable. This effectively eliminates the LiM effect; instead, we observe a distance-based bias, where model performance is better when relevant information is closer to the end of the input. Furthermore, our results suggest that successful retrieval is a prerequisite for reasoning in LLMs, and that the observed positional biases in reasoning are largely inherited from retrieval. These insights have implications for long-context tasks, the design of future LLM benchmarks, and evaluation methodologies for LLMs handling extended inputs.