 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Assumptions in Deep Anomaly Detection
May 30, 2020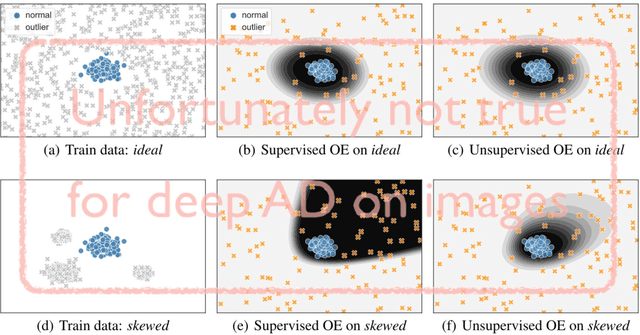
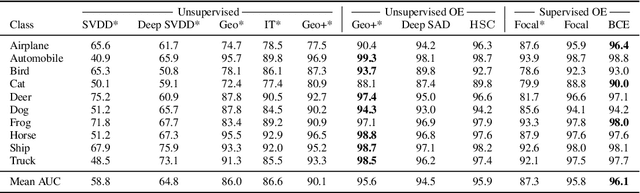
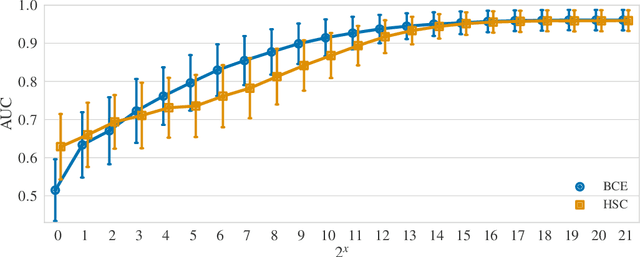
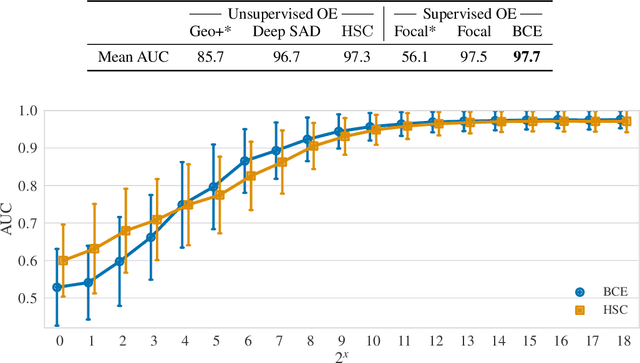
Though anomaly detection (AD) can be viewed as a classification problem (nominal vs. anomalous) it is usually treated in an unsupervised manner since one typically does not have access to, or it is infeasible to utilize, a dataset that sufficiently characterizes what it means to be "anomalous." In this paper we present results demonstrating that this intuition surprisingly does not extend to deep AD on images. For a recent AD benchmark on ImageNet, classifiers trained to discern between normal samples and just a few (64) random natural images are able to outperform the current state of the art in deep AD. We find that this approach is also very effective at other common image AD benchmarks. Experimentally we discover that the multiscale structure of image data makes example anomalies exceptionally informative.
Orthogonal Inductive Matrix Completion
Apr 23, 2020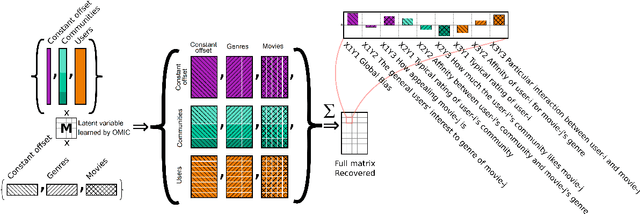

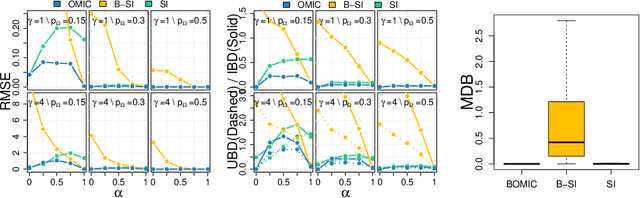

We propose orthogonal inductive matrix completion (OMIC), an interpretable model composed of a sum of matrix completion terms, each with orthonormal side information. We can inject prior knowledge about the eigenvectors of the ground truth matrix, whilst maintaining the representation capability of the model. We present a provably converging algorithm that optimizes all components of the model simultaneously, using nuclear-norm regularisation. Our method is backed up by \textit{distribution-free} learning guarantees that improve with the quality of the injected knowledge. As a special case of our general framework, we study a model consisting of a sum of user and item biases (generic behaviour), a non-inductive term (specific behaviour), and an inductive term using side information. Our theoretical analysis shows that $\epsilon$-recovering the ground truth matrix requires at most $O\left( \frac{n+m+(\sqrt{n}+\sqrt{m})\sqrt{rmn}C}{\epsilon^2}\right)$ entries, where $r$ (resp. $C$) is the rank (resp. maximum entry) of the bias-free part of the ground truth matrix. We analyse the performance of OMIC on several synthetic and real datasets. On synthetic datasets with a sliding scale of user bias relevance, we show that OMIC better adapts to different regimes than other methods and can recover the ground truth. On real life datasets containing user/items recommendations and relevant side information, we find that OMIC surpasses the state of the art, with the added benefit of greater interpretability.
Machine Learning in Thermodynamics: Prediction of Activity Coefficients by Matrix Completion
Jan 29, 2020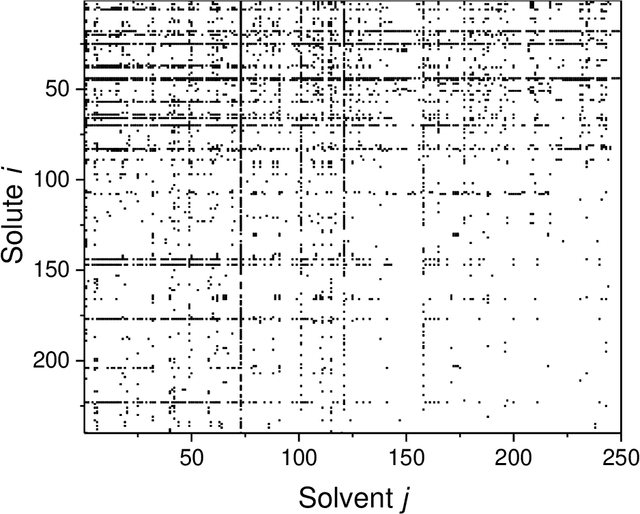
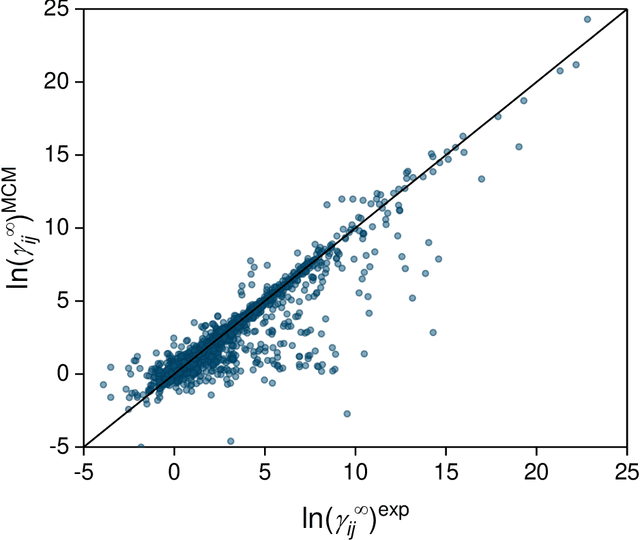
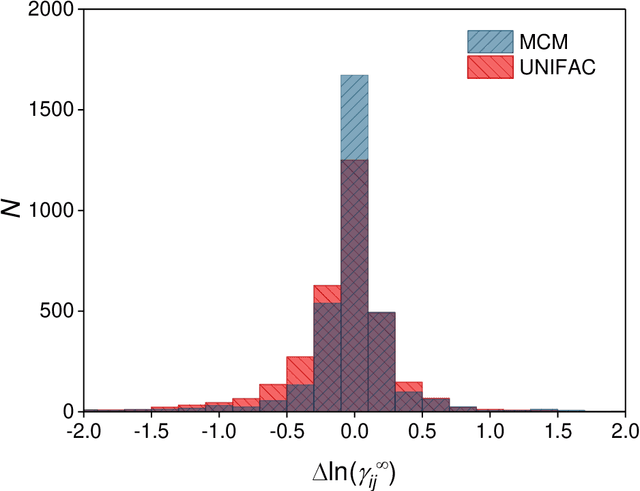
Activity coefficients, which are a measure of the non-ideality of liquid mixtures, are a key property in chemical engineering with relevance to modeling chemical and phase equilibria as well as transport processes. Although experimental data on thousands of binary mixtures are available, prediction methods are needed to calculate the activity coefficients in many relevant mixtures that have not been explored to-date. In this report, we propose a probabilistic matrix factorization model for predicting the activity coefficients in arbitrary binary mixtures. Although no physical descriptors for the considered components were used, our method outperforms the state-of-the-art method that has been refined over three decades while requiring much less training effort. This opens perspectives to novel methods for predicting physico-chemical properties of binary mixtures with the potential to revolutionize modeling and simulation in chemical engineering.
* Published version: J. Phys. Chem. Lett. 11 (2020) 981-985; https://pubs.acs.org/doi/full/10.1021/acs.jpclett.9b03657
Simple and Effective Prevention of Mode Collapse in Deep One-Class Classification
Jan 28, 2020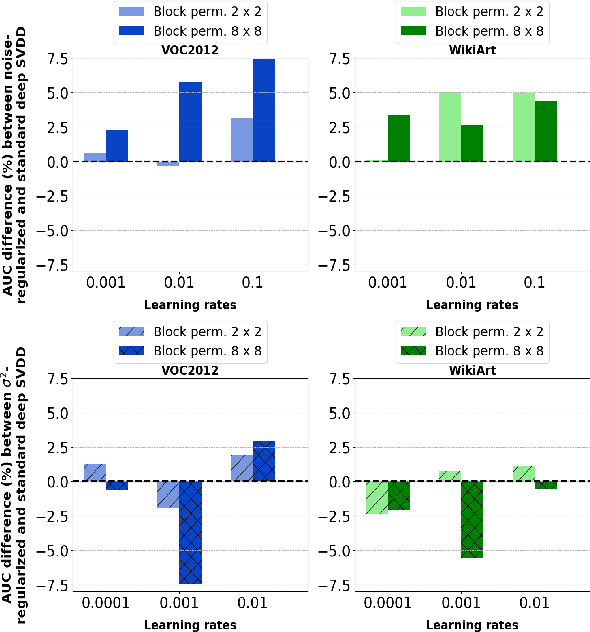
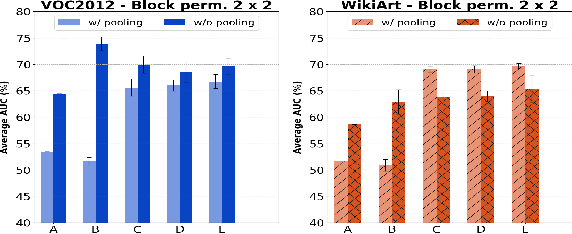
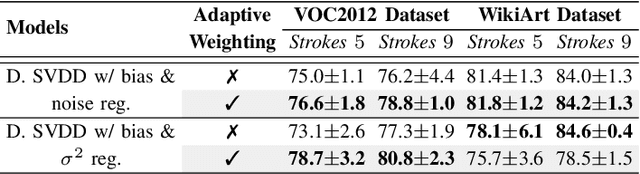
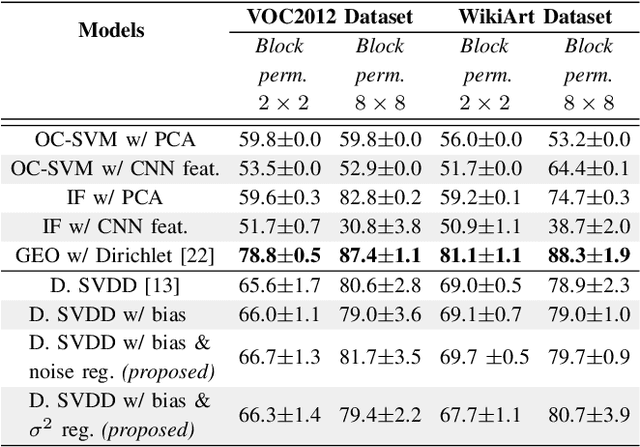
Anomaly detection algorithms find extensive use in various fields. This area of research has recently made great advances thanks to deep learning. A recent method, the deep Support Vector Data Description (deep SVDD), which is inspired by the classic kernel-based Support Vector Data Description (SVDD), is capable of simultaneously learning a feature representation of the data and a data-enclosing hypersphere. The method has shown promising results in both unsupervised and semi-supervised settings. However, deep SVDD suffers from hypersphere collapse---also known as mode collapse---, if the architecture of the model does not comply with certain architectural constraints, e.g. the removal of bias terms. These constraints limit the adaptability of the model and in some cases, may affect the model performance due to learning sub-optimal features. In this work, we consider two regularizers to prevent hypersphere collapse in deep SVDD. The first regularizer is based on injecting random noise via the standard cross-entropy loss. The second regularizer penalizes the minibatch variance when it becomes too small. Moreover, we introduce an adaptive weighting scheme to control the amount of penalization between the SVDD loss and the respective regularizer. Our proposed regularized variants of deep SVDD show encouraging results and outperform a prominent state-of-the-art method on a setup where the anomalies have no apparent geometrical structure.
Two-sample Testing Using Deep Learning
Oct 14, 2019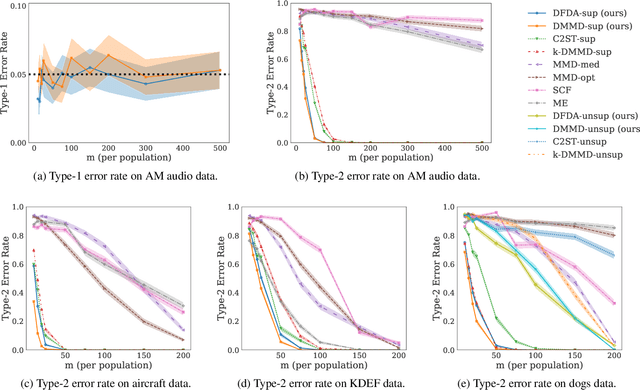
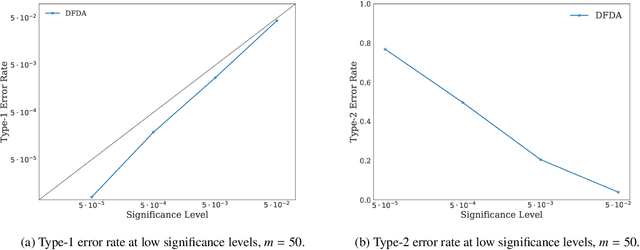
We propose a two-sample testing procedure based on learned deep neural network representations. To this end, we define two test statistics that perform an asymptotic location test on data samples mapped onto a hidden layer. The tests are consistent and asymptotically control the type-1 error rate. Their test statistics can be evaluated in linear time (in the sample size). Suitable data representations are obtained in a data-driven way, by solving a supervised or unsupervised transfer-learning task on an auxiliary (potentially distinct) data set. If no auxiliary data is available, we split the data into two chunks: one for learning representations and one for computing the test statistic. In experiments on audio samples, natural images and three-dimensional neuroimaging data our tests yield significant decreases in type-2 error rate (up to 35 percentage points) compared to state-of-the-art two-sample tests such as kernel-methods and classifier two-sample tests.
Analyzing the Variance of Policy Gradient Estimators for the Linear-Quadratic Regulator
Oct 02, 2019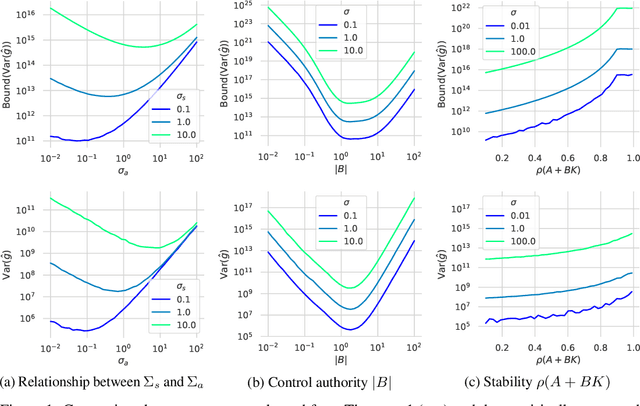
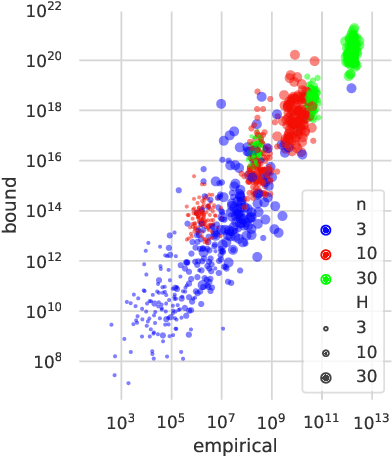
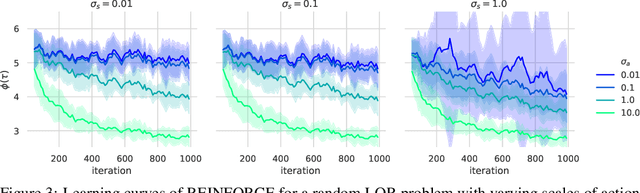
We study the variance of the REINFORCE policy gradient estimator in environments with continuous state and action spaces, linear dynamics, quadratic cost, and Gaussian noise. These simple environments allow us to derive bounds on the estimator variance in terms of the environment and noise parameters. We compare the predictions of our bounds to the empirical variance in simulation experiments.
Deep Semi-Supervised Anomaly Detection
Jun 06, 2019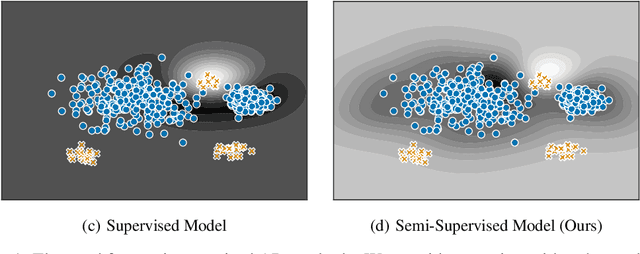
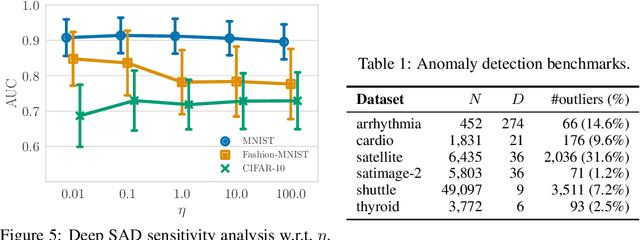
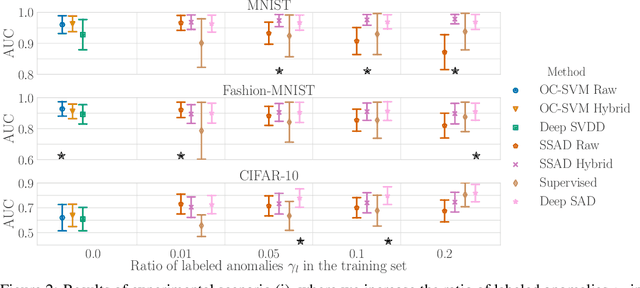
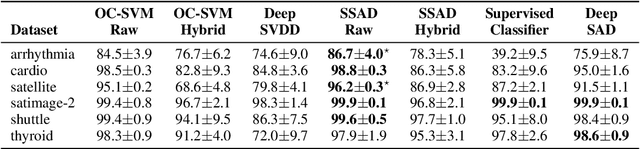
Deep approaches to anomaly detection have recently shown promising results over shallow approaches on high-dimensional data. Typically anomaly detection is treated as an unsupervised learning problem. In practice however, one may have---in addition to a large set of unlabeled samples---access to a small pool of labeled samples, e.g. a subset verified by some domain expert as being normal or anomalous. Semi-supervised approaches to anomaly detection make use of such labeled data to improve detection performance. Few deep semi-supervised approaches to anomaly detection have been proposed so far and those that exist are domain-specific. In this work, we present Deep SAD, an end-to-end methodology for deep semi-supervised anomaly detection. Using an information-theoretic perspective on anomaly detection, we derive a loss motivated by the idea that the entropy for the latent distribution of normal data should be lower than the entropy of the anomalous distribution. We demonstrate in extensive experiments on MNIST, Fashion-MNIST, and CIFAR-10 along with other anomaly detection benchmark datasets that our approach is on par or outperforms shallow, hybrid, and deep competitors, even when provided with only few labeled training data.
Improved Generalisation Bounds for Deep Learning Through $L^\infty$ Covering Numbers
May 29, 2019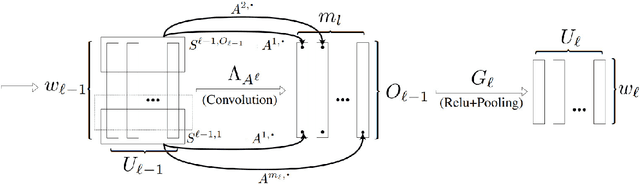
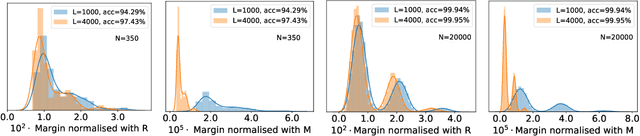
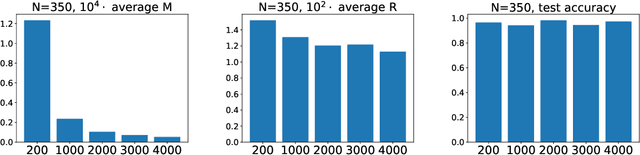
Using proof techniques involving $L^\infty$ covering numbers, we show generalisation error bounds for deep learning with two main improvements over the state of the art. First, our bounds have no explicit dependence on the number of classes except for logarithmic factors. This holds even when formulating the bounds in terms of the $L^2$-norm of the weight matrices, while previous bounds exhibit at least a square-root dependence on the number of classes in this case. Second, we adapt the Rademacher analysis of DNNs to incorporate weight sharing---a task of fundamental theoretical importance which was previously attempted only under very restrictive assumptions. In our results, each convolutional filter contributes only once to the bound, regardless of how many times it is applied. Finally we provide a few further technical improvements, including improving the width dependence from before to after pooling. We also examine our bound's behaviour on artificial data.
Scalable Generalized Dynamic Topic Models
Mar 21, 2018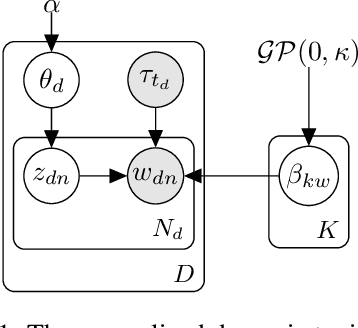
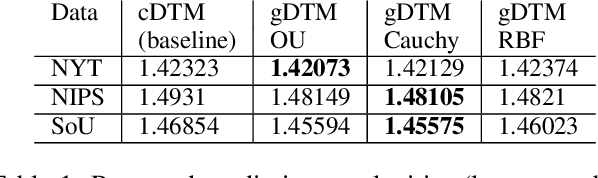
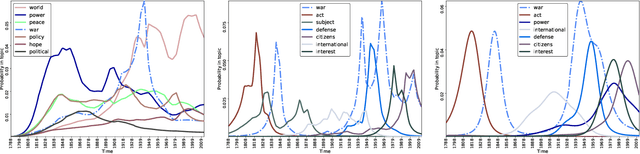
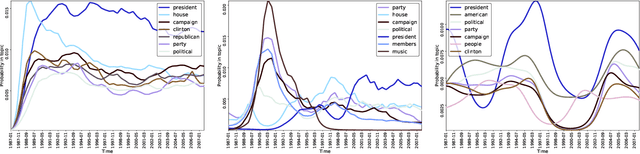
Dynamic topic models (DTMs) model the evolution of prevalent themes in literature, online media, and other forms of text over time. DTMs assume that word co-occurrence statistics change continuously and therefore impose continuous stochastic process priors on their model parameters. These dynamical priors make inference much harder than in regular topic models, and also limit scalability. In this paper, we present several new results around DTMs. First, we extend the class of tractable priors from Wiener processes to the generic class of Gaussian processes (GPs). This allows us to explore topics that develop smoothly over time, that have a long-term memory or are temporally concentrated (for event detection). Second, we show how to perform scalable approximate inference in these models based on ideas around stochastic variational inference and sparse Gaussian processes. This way we can train a rich family of DTMs to massive data. Our experiments on several large-scale datasets show that our generalized model allows us to find interesting patterns that were not accessible by previous approaches.
Efficient Gaussian Process Classification Using Polya-Gamma Data Augmentation
Feb 18, 2018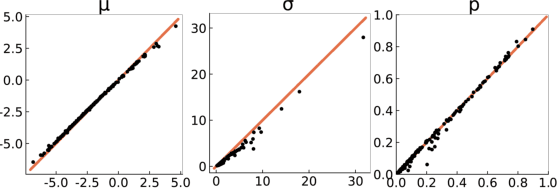
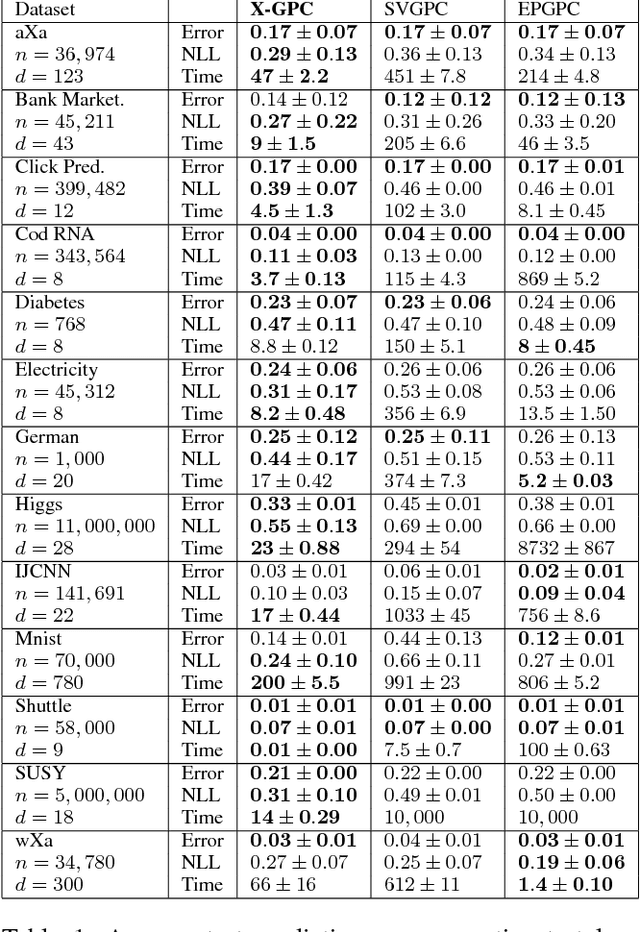
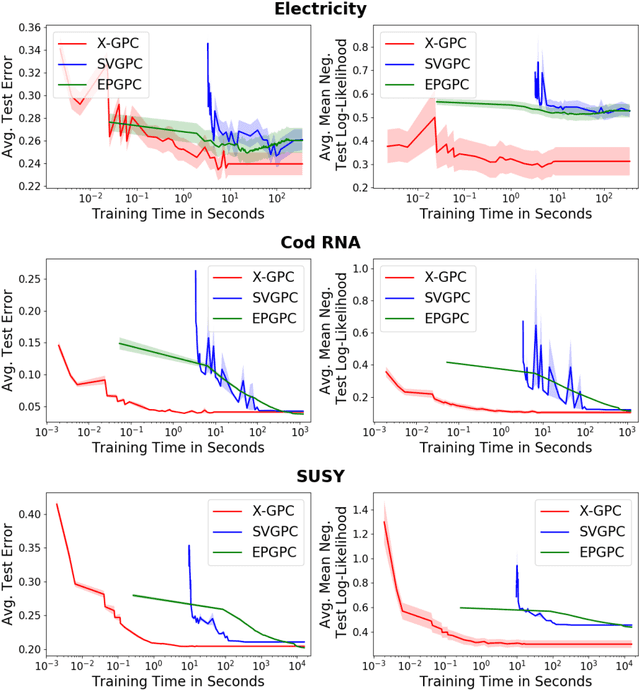
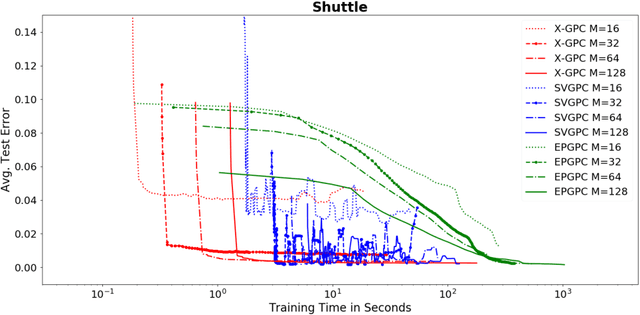
We propose an efficient stochastic variational approach to GP classification building on Polya- Gamma data augmentation and inducing points, which is based on closed-form updates of natural gradients. We evaluate the algorithm on real-world datasets containing up to 11 million data points and demonstrate that it is up to three orders of magnitude faster than the state-of-the-art while being competitive in terms of prediction performance.