 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting COVID-19 Diagnoses and Symptoms From Clinical Text: A New Annotated Corpus and Neural Event Extraction Framework
Dec 02, 2020
Coronavirus disease 2019 (COVID-19) is a global pandemic. Although much has been learned about the novel coronavirus since its emergence, there are many open questions related to tracking its spread, describing symptomology, predicting the severity of infection, and forecasting healthcare utilization. Free-text clinical notes contain critical information for resolving these questions. Data-driven, automatic information extraction models are needed to use this text-encoded information in large-scale studies. This work presents a new clinical corpus, referred to as the COVID-19 Annotated Clinical Text (CACT) Corpus, which comprises 1,472 notes with detailed annotations characterizing COVID-19 diagnoses, testing, and clinical presentation. We introduce a span-based event extraction model that jointly extracts all annotated phenomena, achieving high performance in identifying COVID-19 and symptom events with associated assertion values (0.83-0.97 F1 for events and 0.73-0.79 F1 for assertions). In a secondary use application, we explored the prediction of COVID-19 test results using structured patient data (e.g. vital signs and laboratory results) and automatically extracted symptom information. The automatically extracted symptoms improve prediction performance, beyond structured data alone.
Analysis of Disfluency in Children's Speech
Oct 08, 2020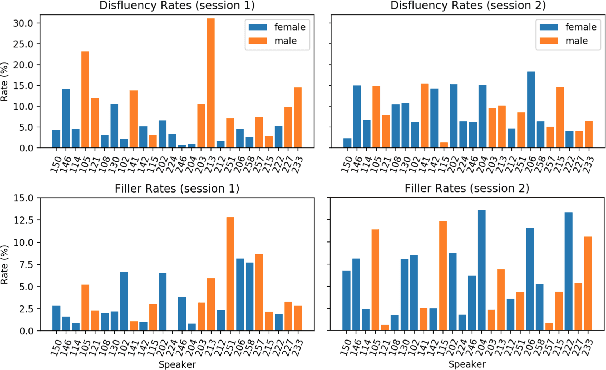
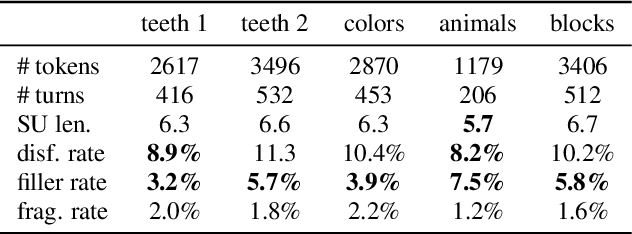
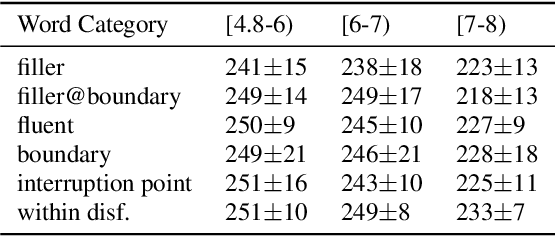
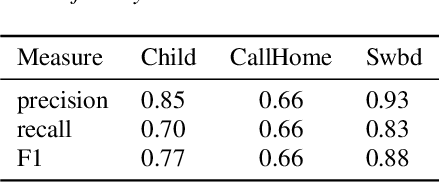
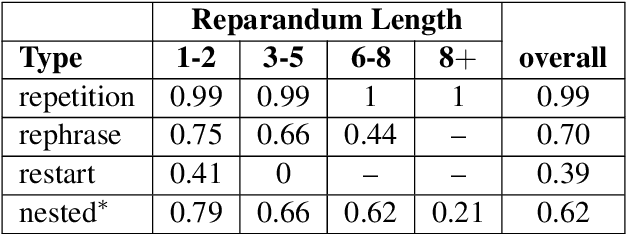
Disfluencies are prevalent in spontaneous speech, as shown in many studies of adult speech. Less is understood about children's speech, especially in pre-school children who are still developing their language skills. We present a novel dataset with annotated disfluencies of spontaneous explanations from 26 children (ages 5--8), interviewed twice over a year-long period. Our preliminary analysis reveals significant differences between children's speech in our corpus and adult spontaneous speech from two corpora (Switchboard and CallHome). Children have higher disfluency and filler rates, tend to use nasal filled pauses more frequently, and on average exhibit longer reparandums than repairs, in contrast to adult speakers. Despite the differences, an automatic disfluency detection system trained on adult (Switchboard) speech transcripts performs reasonably well on children's speech, achieving an F1 score that is 10\% higher than the score on an adult out-of-domain dataset (CallHome).
On the Role of Style in Parsing Speech with Neural Models
Oct 08, 2020
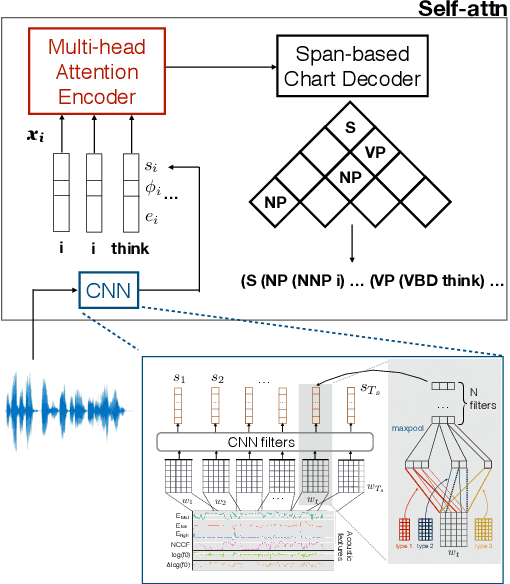

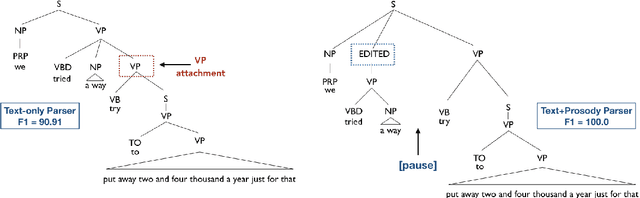
The differences in written text and conversational speech are substantial; previous parsers trained on treebanked text have given very poor results on spontaneous speech. For spoken language, the mismatch in style also extends to prosodic cues, though it is less well understood. This paper re-examines the use of written text in parsing speech in the context of recent advances in neural language processing. We show that neural approaches facilitate using written text to improve parsing of spontaneous speech, and that prosody further improves over this state-of-the-art result. Further, we find an asymmetric degradation from read vs. spontaneous mismatch, with spontaneous speech more generally useful for training parsers.
Extracting Summary Knowledge Graphs from Long Documents
Sep 19, 2020
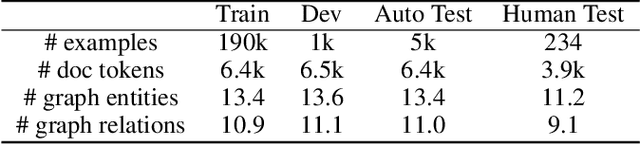

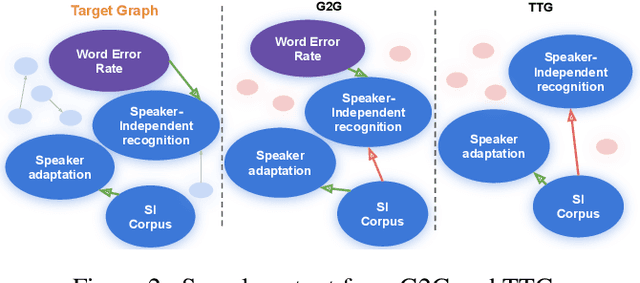
Knowledge graphs capture entities and relations from long documents and can facilitate reasoning in many downstream applications. Extracting compact knowledge graphs containing only salient entities and relations is important but challenging for understanding and summarizing long documents. We introduce a new text-to-graph task of predicting summarized knowledge graphs from long documents. We develop a dataset of 200k document/graph pairs using automatic and human annotations. We also develop strong baselines for this task based on graph learning and text summarization, and provide quantitative and qualitative studies of their effect.
A Controllable Model of Grounded Response Generation
May 01, 2020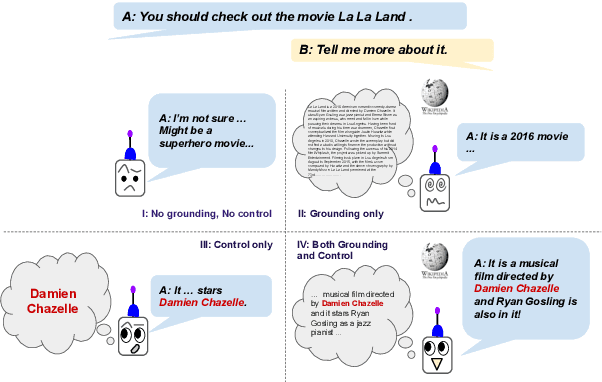
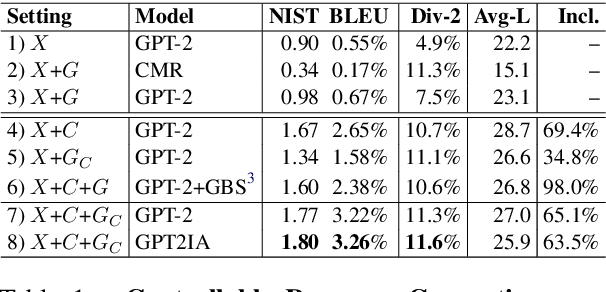
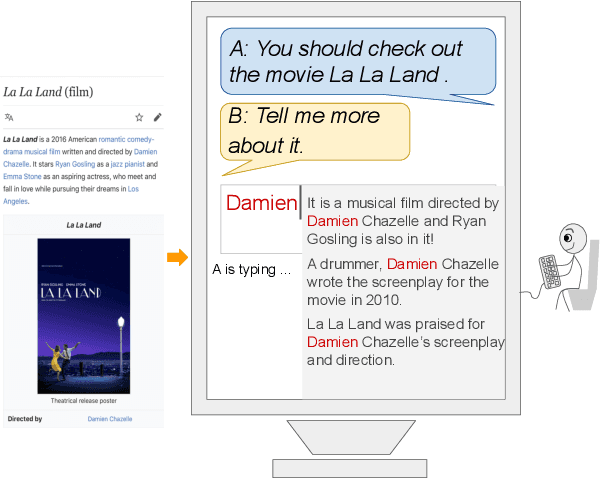
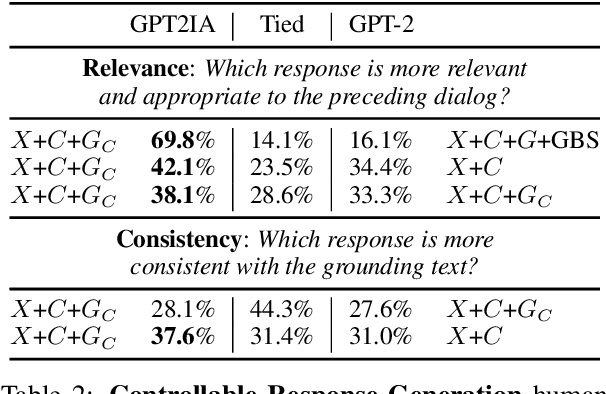
Current end-to-end neural conversation models inherently lack the flexibility to impose semantic control in the response generation process. This control is essential to ensure that users' semantic intents are satisfied and to impose a degree of specificity on generated outputs. Attempts to boost informativeness alone come at the expense of factual accuracy, as attested by GPT-2's propensity to "hallucinate" facts. While this may be mitigated by access to background knowledge, there is scant guarantee of relevance and informativeness in generated responses. We propose a framework that we call controllable grounded response generation (CGRG), in which lexical control phrases are either provided by an user or automatically extracted by a content planner from dialogue context and grounding knowledge. Quantitative and qualitative results show that, using this framework, a GPT-2 based model trained on a conversation-like Reddit dataset outperforms strong generation baselines.
Annotating Social Determinants of Health Using Active Learning, and Characterizing Determinants Using Neural Event Extraction
Apr 11, 2020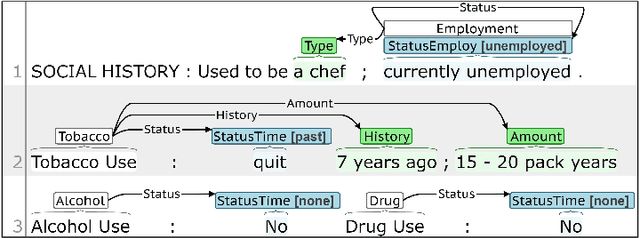
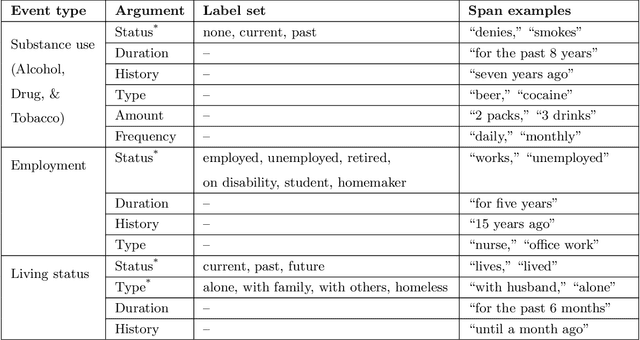
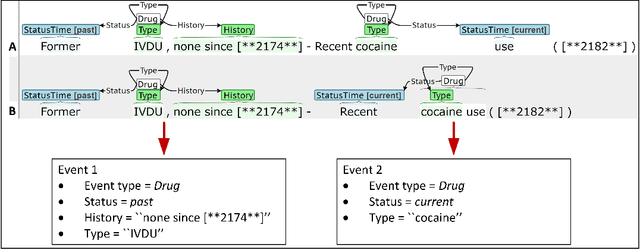
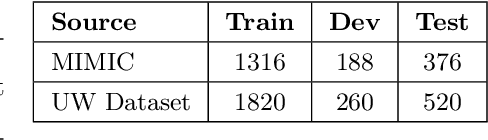
Social determinants of health (SDOH) affect health outcomes, and knowledge of SDOH can inform clinical decision-making. Automatically extracting SDOH information from clinical text requires data-driven information extraction models trained on annotated corpora that are heterogeneous and frequently include critical SDOH. This work presents a new corpus with SDOH annotations, a novel active learning framework, and the first extraction results on the new corpus. The Social History Annotation Corpus (SHAC) includes 4,480 social history sections with detailed annotation for 12 SDOH characterizing the status, extent, and temporal information of 18K distinct events. We introduce a novel active learning framework that selects samples for annotation using a surrogate text classification task as a proxy for a more complex event extraction task. The active learning framework successfully increases the frequency of health risk factors and improves automatic detection of these events over undirected annotation. An event extraction model trained on SHAC achieves high extraction performance for substance use status (0.82-0.93 F1), employment status (0.81-0.86 F1), and living status type (0.81-0.93 F1) on data from three institutions.
Disfluencies and Human Speech Transcription Errors
Apr 08, 2019
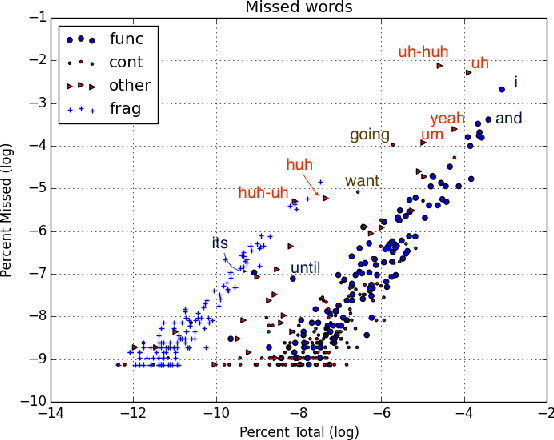
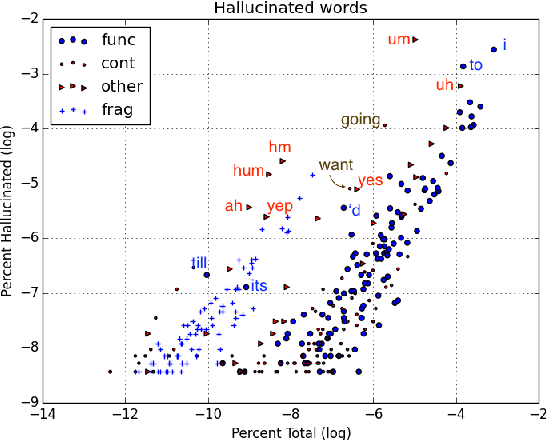
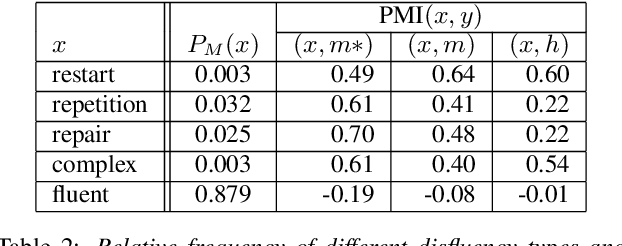
This paper explores contexts associated with errors in transcrip-tion of spontaneous speech, shedding light on human perceptionof disfluencies and other conversational speech phenomena. Anew version of the Switchboard corpus is provided with disfluency annotations for careful speech transcripts, together with results showing the impact of transcription errors on evaluation of automatic disfluency detection.
Giving Attention to the Unexpected: Using Prosody Innovations in Disfluency Detection
Apr 08, 2019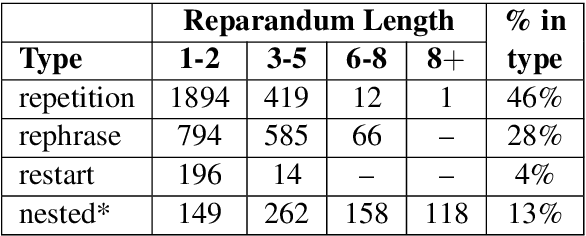
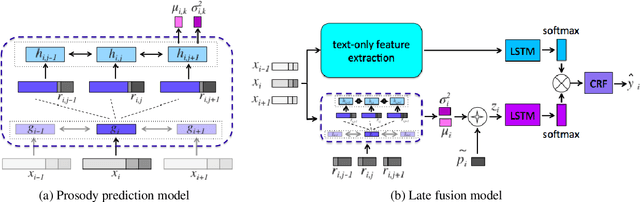
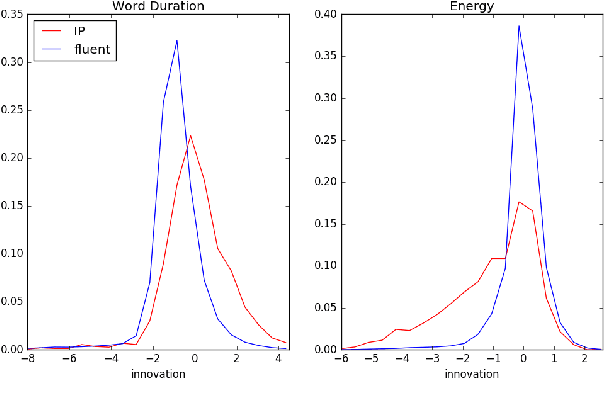
Disfluencies in spontaneous speech are known to be associated with prosodic disruptions. However, most algorithms for disfluency detection use only word transcripts. Integrating prosodic cues has proved difficult because of the many sources of variability affecting the acoustic correlates. This paper introduces a new approach to extracting acoustic-prosodic cues using text-based distributional prediction of acoustic cues to derive vector z-score features (innovations). We explore both early and late fusion techniques for integrating text and prosody, showing gains over a high-accuracy text-only model.
A General Framework for Information Extraction using Dynamic Span Graphs
Apr 05, 2019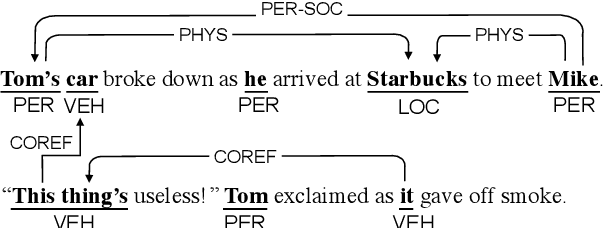
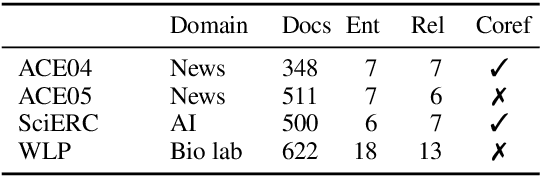
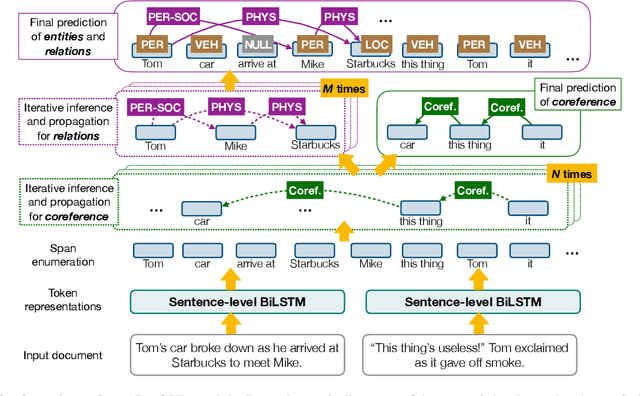
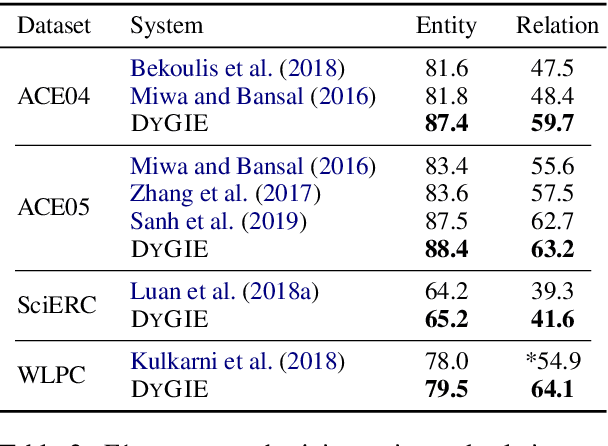
We introduce a general framework for several information extraction tasks that share span representations using dynamically constructed span graphs. The graphs are constructed by selecting the most confident entity spans and linking these nodes with confidence-weighted relation types and coreferences. The dynamic span graph allows coreference and relation type confidences to propagate through the graph to iteratively refine the span representations. This is unlike previous multi-task frameworks for information extraction in which the only interaction between tasks is in the shared first-layer LSTM. Our framework significantly outperforms the state-of-the-art on multiple information extraction tasks across multiple datasets reflecting different domains. We further observe that the span enumeration approach is good at detecting nested span entities, with significant F1 score improvement on the ACE dataset.
Robust cross-domain disfluency detection with pattern match networks
Nov 17, 2018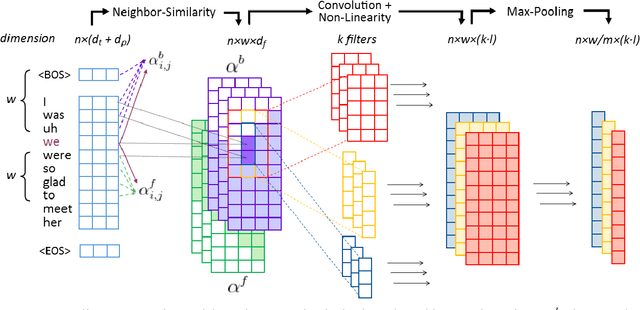
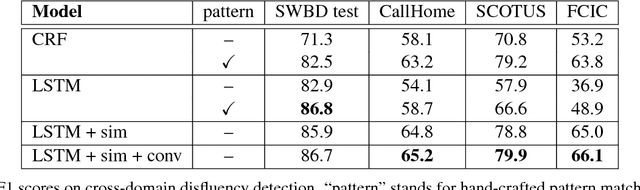

In this paper we introduce a novel pattern match neural network architecture that uses neighbor similarity scores as features, eliminating the need for feature engineering in a disfluency detection task. We evaluate the approach in disfluency detection for four different speech genres, showing that the approach is as effective as hand-engineered pattern match features when used on in-domain data and achieves superior performance in cross-domain scenarios.