 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Continual Learning with Modular Networks and Task-Driven Priors
Dec 23, 2020
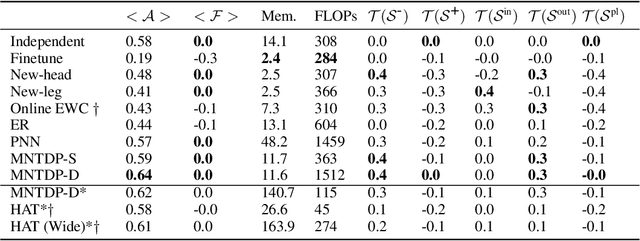

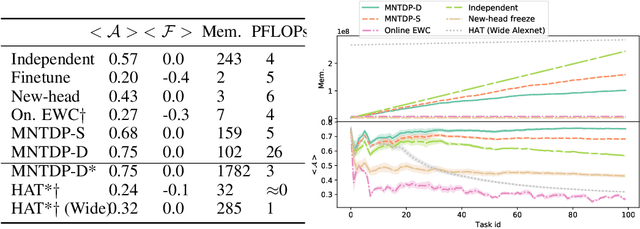
Existing literature in Continual Learning (CL) has focused on overcoming catastrophic forgetting, the inability of the learner to recall how to perform tasks observed in the past. There are however other desirable properties of a CL system, such as the ability to transfer knowledge from previous tasks and to scale memory and compute sub-linearly with the number of tasks. Since most current benchmarks focus only on forgetting using short streams of tasks, we first propose a new suite of benchmarks to probe CL algorithms across these new axes. Finally, we introduce a new modular architecture, whose modules represent atomic skills that can be composed to perform a certain task. Learning a task reduces to figuring out which past modules to re-use, and which new modules to instantiate to solve the current task. Our learning algorithm leverages a task-driven prior over the exponential search space of all possible ways to combine modules, enabling efficient learning on long streams of tasks. Our experiments show that this modular architecture and learning algorithm perform competitively on widely used CL benchmarks while yielding superior performance on the more challenging benchmarks we introduce in this work.
Few-shot Sequence Learning with Transformers
Dec 17, 2020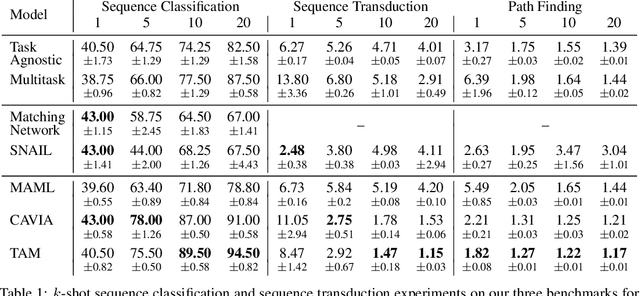
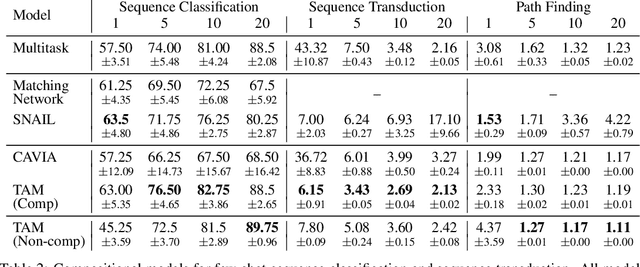
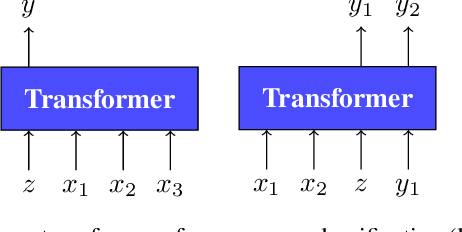
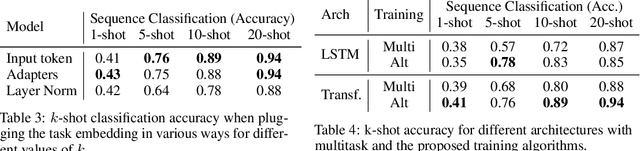
Few-shot algorithms aim at learning new tasks provided only a handful of training examples. In this work we investigate few-shot learning in the setting where the data points are sequences of tokens and propose an efficient learning algorithm based on Transformers. In the simplest setting, we append a token to an input sequence which represents the particular task to be undertaken, and show that the embedding of this token can be optimized on the fly given few labeled examples. Our approach does not require complicated changes to the model architecture such as adapter layers nor computing second order derivatives as is currently popular in the meta-learning and few-shot learning literature. We demonstrate our approach on a variety of tasks, and analyze the generalization properties of several model variants and baseline approaches. In particular, we show that compositional task descriptors can improve performance. Experiments show that our approach works at least as well as other methods, while being more computationally efficient.
Multi-scale Transformer Language Models
May 01, 2020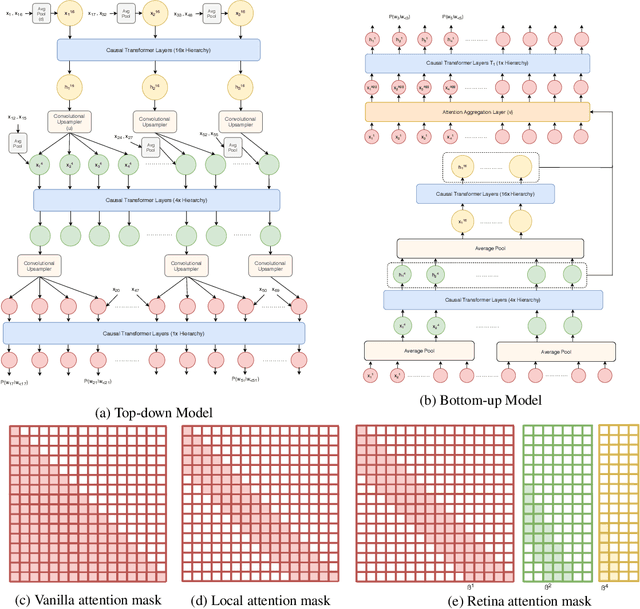
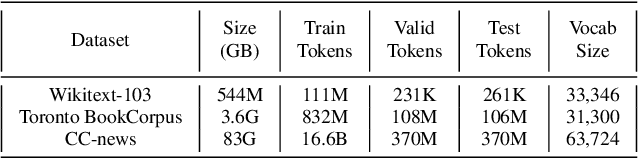
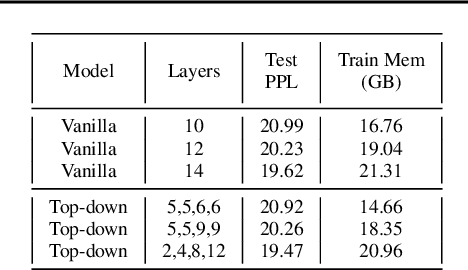
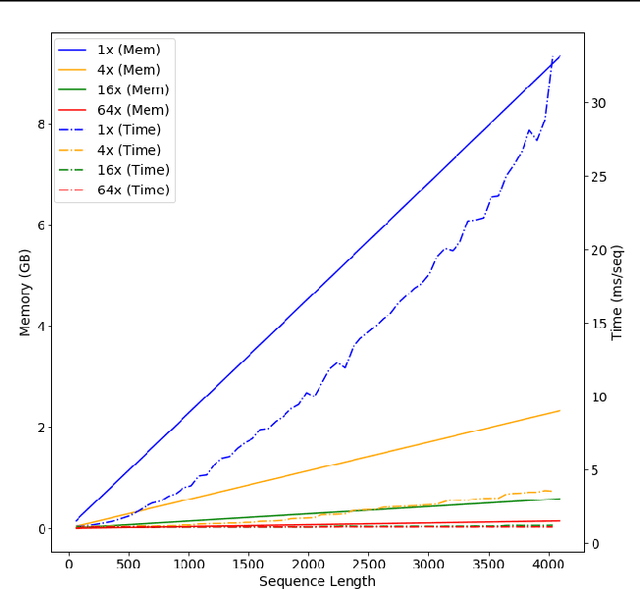
We investigate multi-scale transformer language models that learn representations of text at multiple scales, and present three different architectures that have an inductive bias to handle the hierarchical nature of language. Experiments on large-scale language modeling benchmarks empirically demonstrate favorable likelihood vs memory footprint trade-offs, e.g. we show that it is possible to train a hierarchical variant with 30 layers that has 23% smaller memory footprint and better perplexity, compared to a vanilla transformer with less than half the number of layers, on the Toronto BookCorpus. We analyze the advantages of learned representations at multiple scales in terms of memory footprint, compute time, and perplexity, which are particularly appealing given the quadratic scaling of transformers' run time and memory usage with respect to sequence length.
Residual Energy-Based Models for Text Generation
Apr 22, 2020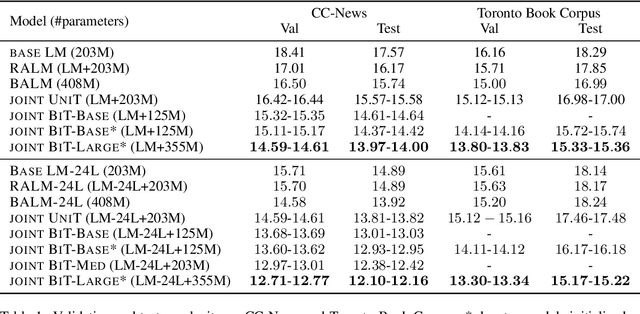
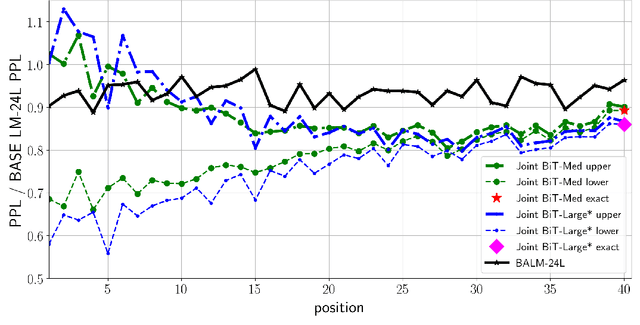
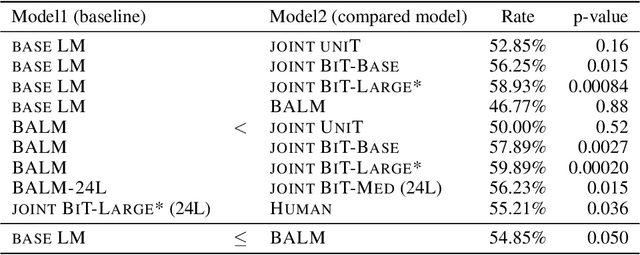
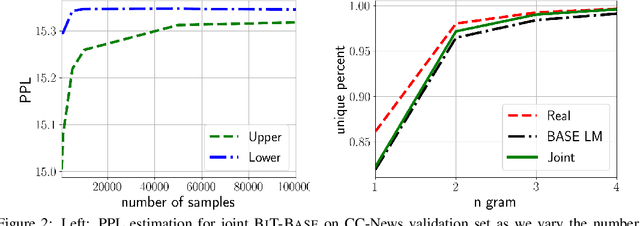
Text generation is ubiquitous in many NLP tasks, from summarization, to dialogue and machine translation. The dominant parametric approach is based on locally normalized models which predict one word at a time. While these work remarkably well, they are plagued by exposure bias due to the greedy nature of the generation process. In this work, we investigate un-normalized energy-based models (EBMs) which operate not at the token but at the sequence level. In order to make training tractable, we first work in the residual of a pretrained locally normalized language model and second we train using noise contrastive estimation. Furthermore, since the EBM works at the sequence level, we can leverage pretrained bi-directional contextual representations, such as BERT and RoBERTa. Our experiments on two large language modeling datasets show that residual EBMs yield lower perplexity compared to locally normalized baselines. Moreover, generation via importance sampling is very efficient and of higher quality than the baseline models according to human evaluation.
* published at ICLR 2020. arXiv admin note: substantial text overlap with arXiv:2004.10188
Energy-Based Models for Text
Apr 06, 2020
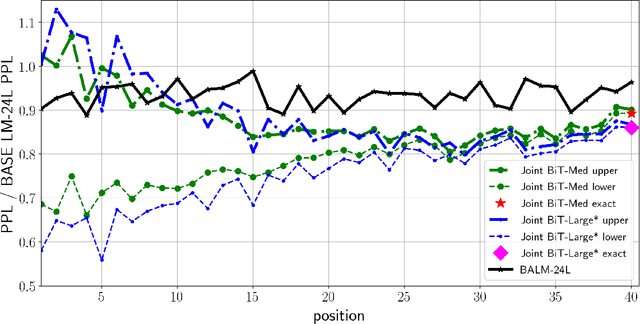

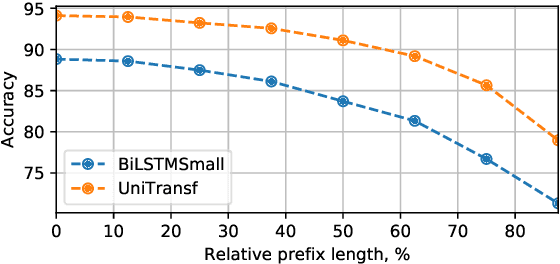
Current large-scale auto-regressive language models display impressive fluency and can generate convincing text. In this work we start by asking the question: Can the generations of these models be reliably distinguished from real text by statistical discriminators? We find experimentally that the answer is affirmative when we have access to the training data for the model, and guardedly affirmative even if we do not. This suggests that the auto-regressive models can be improved by incorporating the (globally normalized) discriminators into the generative process. We give a formalism for this using the Energy-Based Model framework, and show that it indeed improves the results of the generative models, measured both in terms of perplexity and in terms of human evaluation.
Facebook AI's WAT19 Myanmar-English Translation Task Submission
Oct 15, 2019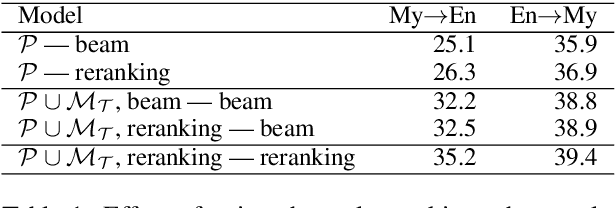
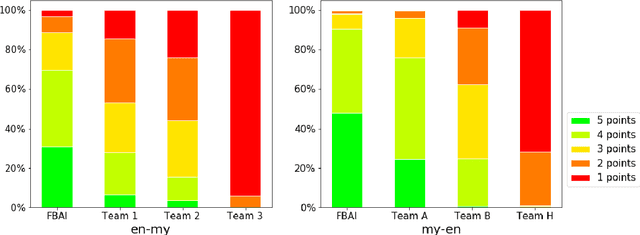
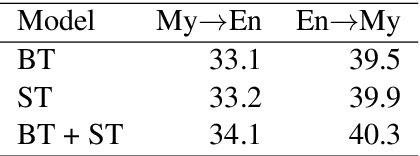
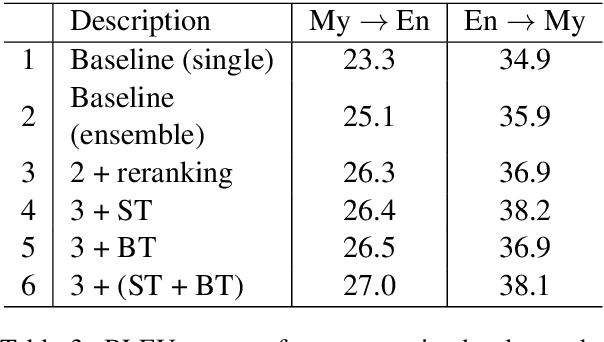
This paper describes Facebook AI's submission to the WAT 2019 Myanmar-English translation task. Our baseline systems are BPE-based transformer models. We explore methods to leverage monolingual data to improve generalization, including self-training, back-translation and their combination. We further improve results by using noisy channel re-ranking and ensembling. We demonstrate that these techniques can significantly improve not only a system trained with additional monolingual data, but even the baseline system trained exclusively on the provided small parallel dataset. Our system ranks first in both directions according to human evaluation and BLEU, with a gain of over 8 BLEU points above the second best system.
Revisiting Self-Training for Neural Sequence Generation
Sep 30, 2019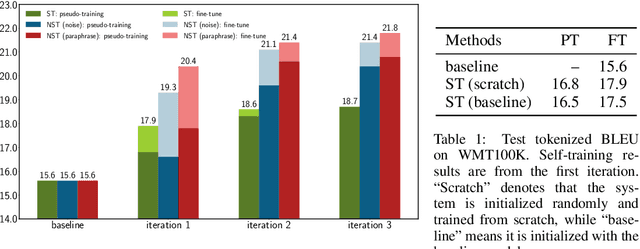


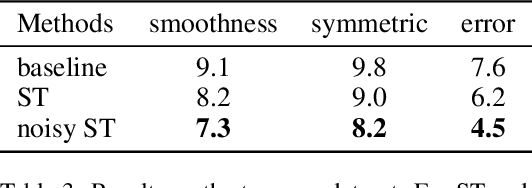
Self-training is one of the earliest and simplest semi-supervised methods. The key idea is to augment the original labeled dataset with unlabeled data paired with the model's prediction (i.e. pseudo-parallel data). While self-training has been extensively studied on classification problems, in complex sequence generation tasks (e.g. machine translation) it is still unclear how self-training works due to the compositionality of the target space. In this work, we first empirically show that self-training is able to decently improve the supervised baseline on neural sequence generation tasks. Through careful examination of the performance gains, we find that the perturbation on the hidden states (i.e. dropout) is critical for self-training to benefit from the pseudo-parallel data, which acts as a regularizer and forces the model to yield close predictions for similar unlabeled inputs. Such effect helps the model correct some incorrect predictions on unlabeled data. To further encourage this mechanism, we propose to inject noise to the input space, resulting in a "noisy" version of self-training. Empirical study on standard machine translation and text summarization benchmarks shows that noisy self-training is able to effectively utilize unlabeled data and improve the performance of the supervised baseline by a large margin.
The Source-Target Domain Mismatch Problem in Machine Translation
Sep 28, 2019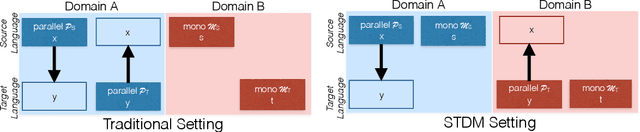
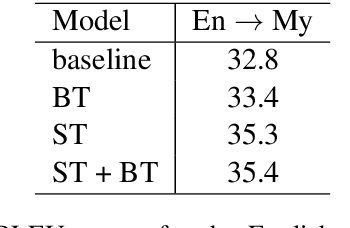
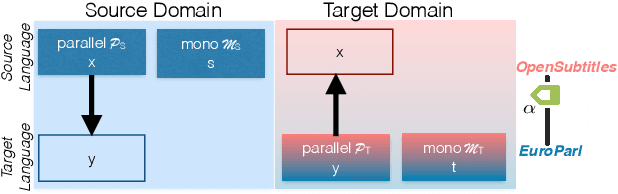
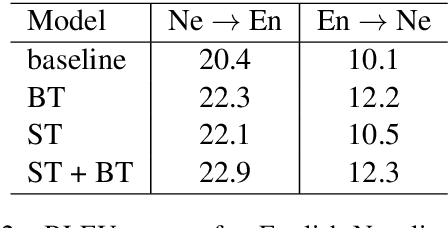
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that particularly in low resource settings this causes the domains of the source and target language to greatly mismatch, as the two languages are often spoken in further apart regions of the world with more distinctive cultural traits and unrelated local events. In this work we first propose a controlled setting to carefully analyze the source-target domain mismatch, and its dependence on the amount of parallel and monolingual data. Second, we test both a model trained with back-translation and one trained with self-training. The latter leverages in-domain source monolingual data but uses potentially incorrect target references. We found that these two approaches are often complementary to each other. For instance, on a low-resource Nepali-English dataset the combined approach improves upon the baseline using just parallel data by 2.5 BLEU points, and by 0.6 BLEU point when compared to back-translation.
On The Evaluation of Machine Translation Systems Trained With Back-Translation
Aug 14, 2019
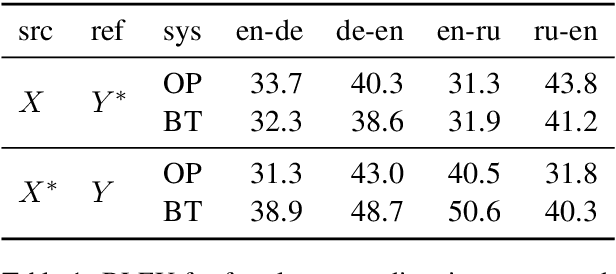
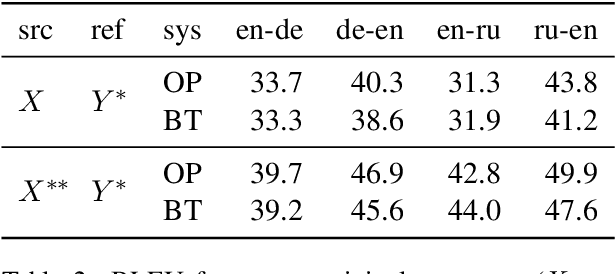
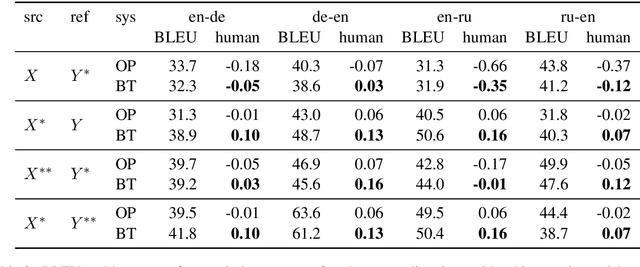
Back-translation is a widely used data augmentation technique which leverages target monolingual data. However, its effectiveness has been challenged since automatic metrics such as BLEU only show significant improvements for test examples where the source itself is a translation, or translationese. This is believed to be due to translationese inputs better matching the back-translated training data. In this work, we show that this conjecture is not empirically supported and that back-translation improves translation quality of both naturally occurring text as well as translationese according to professional human translators. We provide empirical evidence to support the view that back-translation is preferred by humans because it produces more fluent outputs. BLEU cannot capture human preferences because references are translationese when source sentences are natural text. We recommend complementing BLEU with a language model score to measure fluency.
Large Memory Layers with Product Keys
Jul 10, 2019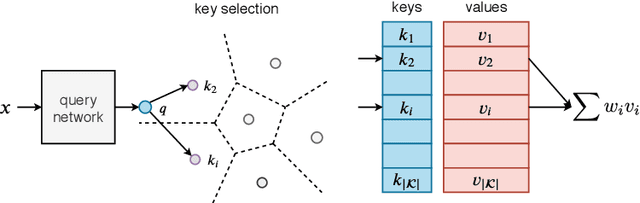
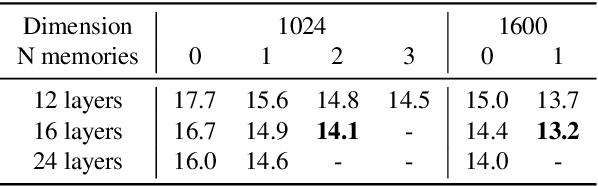
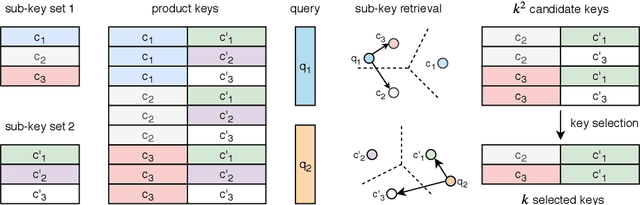

This paper introduces a structured memory which can be easily integrated into a neural network. The memory is very large by design and therefore significantly increases the capacity of the architecture, by up to a billion parameters with a negligible computational overhead. Its design and access pattern is based on product keys, which enable fast and exact nearest neighbor search. The ability to increase the number of parameters while keeping the same computational budget lets the overall system strike a better trade-off between prediction accuracy and computation efficiency both at training and test time. This memory layer allows us to tackle very large scale language modeling tasks. In our experiments we consider a dataset with up to 30 billion words, and we plug our memory layer in a state-of-the-art transformer-based architecture. In particular, we found that a memory augmented model with only 12 layers outperforms a baseline transformer model with 24 layers, while being twice faster at inference time. We release our code for reproducibility purposes.