 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Source-Target Domain Mismatch Problem in Machine Translation
Paper and Code
Sep 28, 2019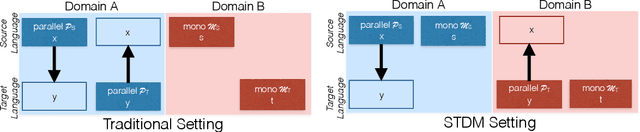
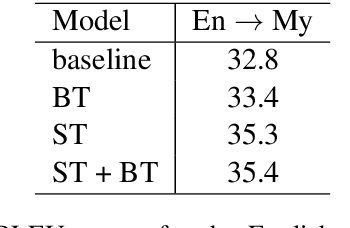
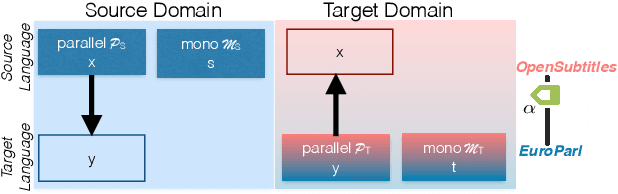
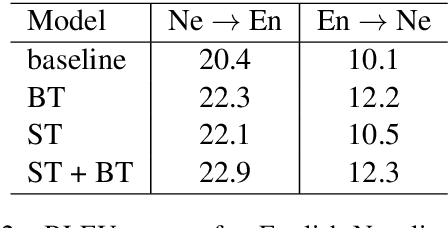
While we live in an increasingly interconnected world, different places still exhibit strikingly different cultures and many events we experience in our every day life pertain only to the specific place we live in. As a result, people often talk about different things in different parts of the world. In this work we study the effect of local context in machine translation and postulate that particularly in low resource settings this causes the domains of the source and target language to greatly mismatch, as the two languages are often spoken in further apart regions of the world with more distinctive cultural traits and unrelated local events. In this work we first propose a controlled setting to carefully analyze the source-target domain mismatch, and its dependence on the amount of parallel and monolingual data. Second, we test both a model trained with back-translation and one trained with self-training. The latter leverages in-domain source monolingual data but uses potentially incorrect target references. We found that these two approaches are often complementary to each other. For instance, on a low-resource Nepali-English dataset the combined approach improves upon the baseline using just parallel data by 2.5 BLEU points, and by 0.6 BLEU point when compared to back-translation.