 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge distillation for semi-supervised domain adaptation
Aug 16, 2019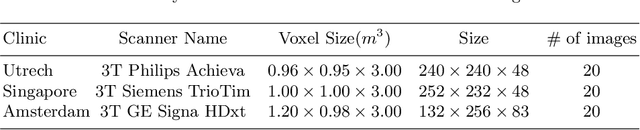
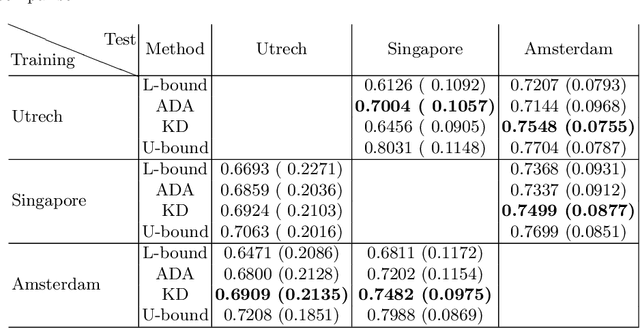
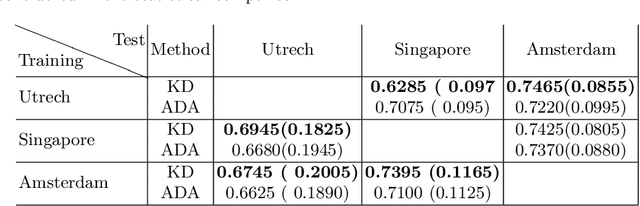
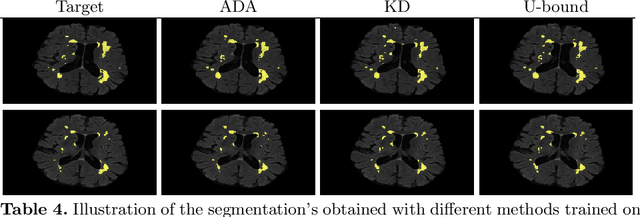
In the absence of sufficient data variation (e.g., scanner and protocol variability) in annotated data, deep neural networks (DNNs) tend to overfit during training. As a result, their performance is significantly lower on data from unseen sources compared to the performance on data from the same source as the training data. Semi-supervised domain adaptation methods can alleviate this problem by tuning networks to new target domains without the need for annotated data from these domains. Adversarial domain adaptation (ADA) methods are a popular choice that aim to train networks in such a way that the features generated are domain agnostic. However, these methods require careful dataset-specific selection of hyperparameters such as the complexity of the discriminator in order to achieve a reasonable performance. We propose to use knowledge distillation (KD) -- an efficient way of transferring knowledge between different DNNs -- for semi-supervised domain adaption of DNNs. It does not require dataset-specific hyperparameter tuning, making it generally applicable. The proposed method is compared to ADA for segmentation of white matter hyperintensities (WMH) in magnetic resonance imaging (MRI) scans generated by scanners that are not a part of the training set. Compared with both the baseline DNN (trained on source domain only and without any adaption to target domain) and with using ADA for semi-supervised domain adaptation, the proposed method achieves significantly higher WMH dice scores.
Robust parametric modeling of Alzheimer's disease progression
Aug 14, 2019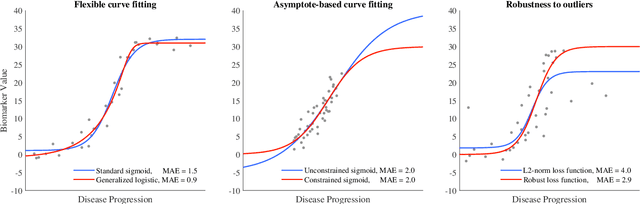
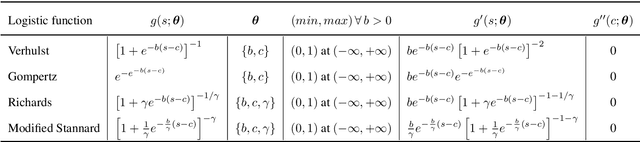

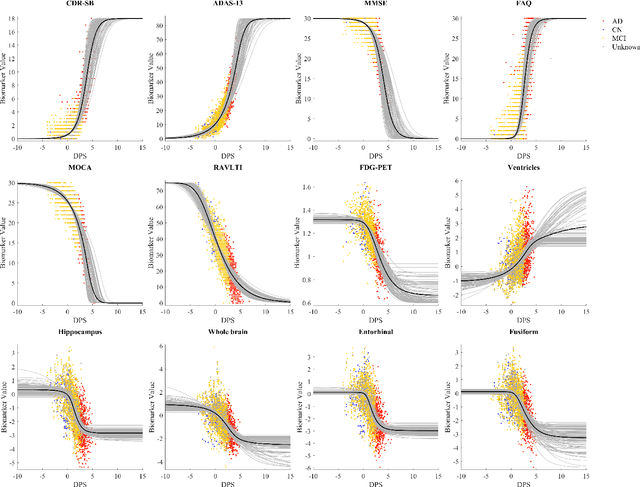
Quantitative characterization of disease progression using longitudinal data can provide long-term predictions for the pathological stages of individuals. This work studies robust modeling of Alzheimer's disease progression using parametric methods. The proposed method linearly maps individual's chronological age to a disease progression score (DPS) and robustly fits a constrained generalized logistic function to the longitudinal dynamic of a biomarker as a function of the DPS using M-estimation. Robustness of the estimates is quantified using bootstrapping via Monte Carlo resampling, and the inflection points are used to temporally order the modeled biomarkers in the disease course. Moreover, kernel density estimation is applied to the obtained DPSs for clinical status prediction using a Bayesian classifier. Different M-estimators and logistic functions, including a new generalized type proposed in this study called modified Stannard, are evaluated on the ADNI database for robust modeling of volumetric MRI and PET biomarkers, as well as neuropsychological tests. The results show that the modified Stannard function fitted using the modified Huber loss achieves the best modeling performance with a mean of median absolute errors (MMAE) of 0.059 across all biomarkers and bootstraps. In addition, applied to the ADNI test set, this model achieves a multi-class area under the ROC curve (MAUC) of 0.87 in clinical status prediction, and it significantly outperforms an analogous state-of-the-art method with a biomarker modeling MMAE of 0.059 vs. 0.061 (p < 0.001). Finally, the experiments show that the proposed model, trained using abundant ADNI data, generalizes well to data from the independent NACC database, where both modeling and diagnostic performance are significantly improved (p < 0.001) compared with using a model trained using relatively sparse NACC data.
Hetero-Modal Variational Encoder-Decoder for Joint Modality Completion and Segmentation
Jul 25, 2019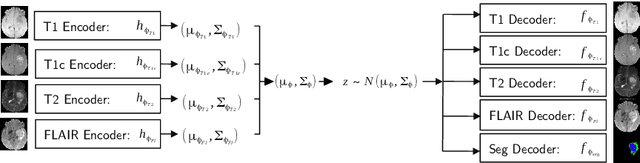

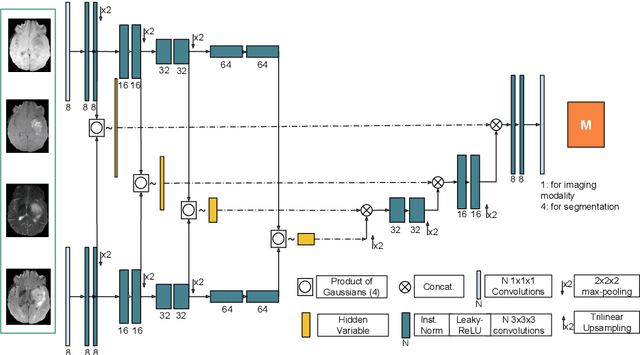
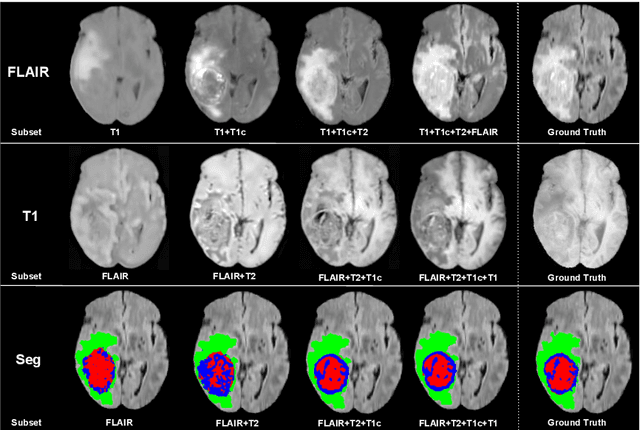
We propose a new deep learning method for tumour segmentation when dealing with missing imaging modalities. Instead of producing one network for each possible subset of observed modalities or using arithmetic operations to combine feature maps, our hetero-modal variational 3D encoder-decoder independently embeds all observed modalities into a shared latent representation. Missing data and tumour segmentation can be then generated from this embedding. In our scenario, the input is a random subset of modalities. We demonstrate that the optimisation problem can be seen as a mixture sampling. In addition to this, we introduce a new network architecture building upon both the 3D U-Net and the Multi-Modal Variational Auto-Encoder (MVAE). Finally, we evaluate our method on BraTS2018 using subsets of the imaging modalities as input. Our model outperforms the current state-of-the-art method for dealing with missing modalities and achieves similar performance to the subset-specific equivalent networks.
Permutohedral Attention Module for Efficient Non-Local Neural Networks
Jul 01, 2019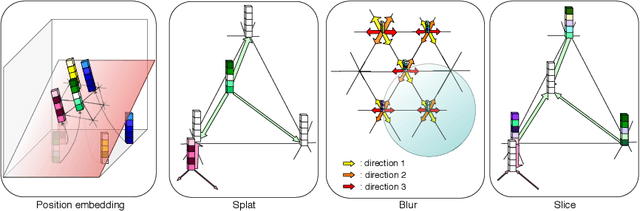
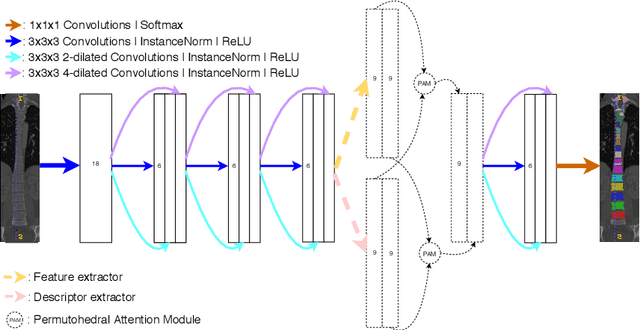
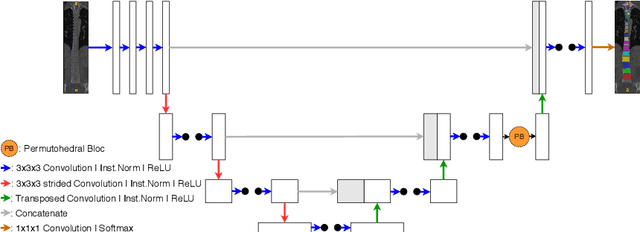
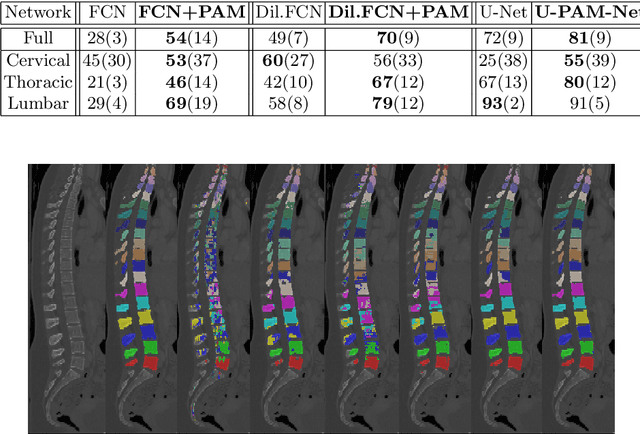
Medical image processing tasks such as segmentation often require capturing non-local information. As organs, bones, and tissues share common characteristics such as intensity, shape, and texture, the contextual information plays a critical role in correctly labeling them. Segmentation and labeling is now typically done with convolutional neural networks (CNNs) but the context of the CNN is limited by the receptive field which itself is limited by memory requirements and other properties. In this paper, we propose a new attention module, that we call Permutohedral Attention Module (PAM), to efficiently capture non-local characteristics of the image. The proposed method is both memory and computationally efficient. We provide a GPU implementation of this module suitable for 3D medical imaging problems. We demonstrate the efficiency and scalability of our module with the challenging task of vertebrae segmentation and labeling where context plays a crucial role because of the very similar appearance of different vertebrae.
Training recurrent neural networks robust to incomplete data: application to Alzheimer's disease progression modeling
Mar 17, 2019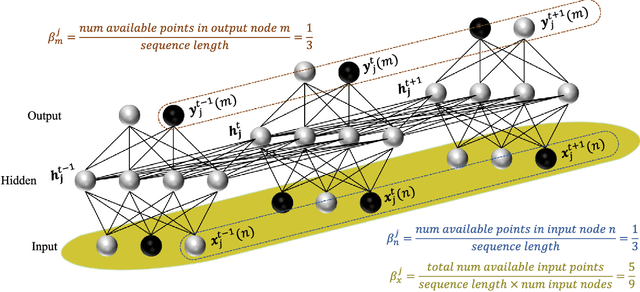
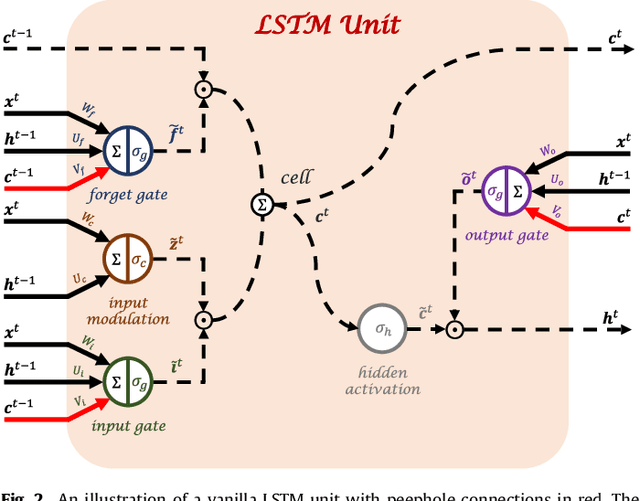
Disease progression modeling (DPM) using longitudinal data is a challenging machine learning task. Existing DPM algorithms neglect temporal dependencies among measurements, make parametric assumptions about biomarker trajectories, do not model multiple biomarkers jointly, and need an alignment of subjects' trajectories. In this paper, recurrent neural networks (RNNs) are utilized to address these issues. However, in many cases, longitudinal cohorts contain incomplete data, which hinders the application of standard RNNs and requires a pre-processing step such as imputation of the missing values. Instead, we propose a generalized training rule for the most widely used RNN architecture, long short-term memory (LSTM) networks, that can handle both missing predictor and target values. The proposed LSTM algorithm is applied to model the progression of Alzheimer's disease (AD) using six volumetric magnetic resonance imaging (MRI) biomarkers, i.e., volumes of ventricles, hippocampus, whole brain, fusiform, middle temporal gyrus, and entorhinal cortex, and it is compared to standard LSTM networks with data imputation and a parametric, regression-based DPM method. The results show that the proposed algorithm achieves a significantly lower mean absolute error (MAE) than the alternatives with p < 0.05 using Wilcoxon signed rank test in predicting values of almost all of the MRI biomarkers. Moreover, a linear discriminant analysis (LDA) classifier applied to the predicted biomarker values produces a significantly larger AUC of 0.90 vs. at most 0.84 with p < 0.001 using McNemar's test for clinical diagnosis of AD. Inspection of MAE curves as a function of the amount of missing data reveals that the proposed LSTM algorithm achieves the best performance up until more than 74% missing values. Finally, it is illustrated how the method can successfully be applied to data with varying time intervals.
* arXiv admin note: substantial text overlap with arXiv:1808.05500
Grey matter sublayer thickness estimation in themouse cerebellum
Jan 08, 2019


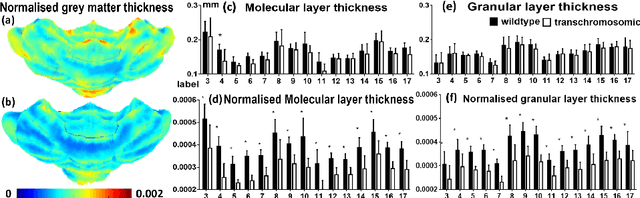
The cerebellar grey matter morphology is an important feature to study neurodegenerative diseases such as Alzheimer's disease or Down's syndrome. Its volume or thickness is commonly used as a surrogate imaging biomarker for such diseases. Most studies about grey matter thickness estimation focused on the cortex, and little attention has been drawn on the morphology of the cerebellum. Using ex vivo high-resolution MRI, it is now possible to visualise the different cell layers in the mouse cerebellum. In this work, we introduce a framework to extract the Purkinje layer within the grey matter, enabling the estimation of the thickness of the cerebellar grey matter, the granular layer and molecular layer from gadolinium-enhanced ex vivo mouse brain MRI. Application to mouse model of Down's syndrome found reduced cortical and layer thicknesses in the transchromosomic group.
* 8 pages, 7 figures, International Conference on Medical Image Computing and Computer-Assisted Intervention 2015
PADDIT: Probabilistic Augmentation of Data using Diffeomorphic Image Transformation
Oct 03, 2018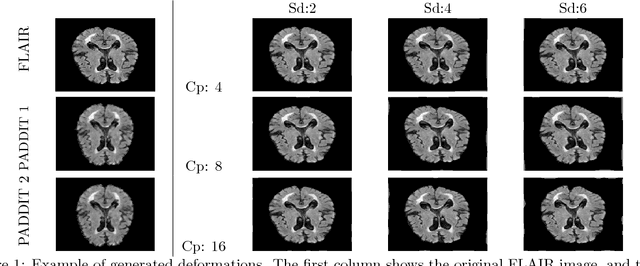
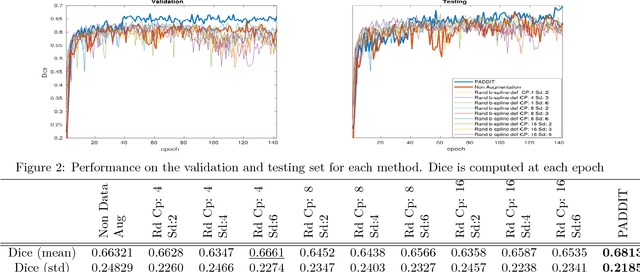
For proper generalization performance of convolutional neural networks (CNNs) in medical image segmentation, the learnt features should be invariant under particular non-linear shape variations of the input. To induce invariance in CNNs to such transformations, we propose Probabilistic Augmentation of Data using Diffeomorphic Image Transformation (PADDIT) -- a systematic framework for generating realistic transformations that can be used to augment data for training CNNs. We show that CNNs trained with PADDIT outperforms CNNs trained without augmentation and with generic augmentation in segmenting white matter hyperintensities from T1 and FLAIR brain MRI scans.
Deep Boosted Regression for MR to CT Synthesis
Aug 22, 2018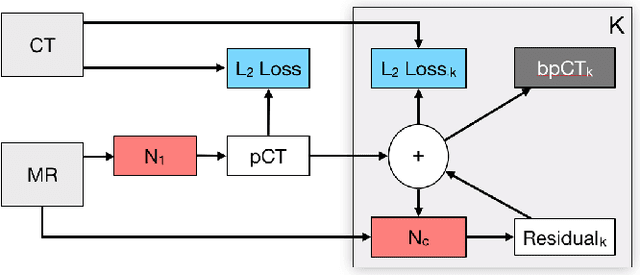

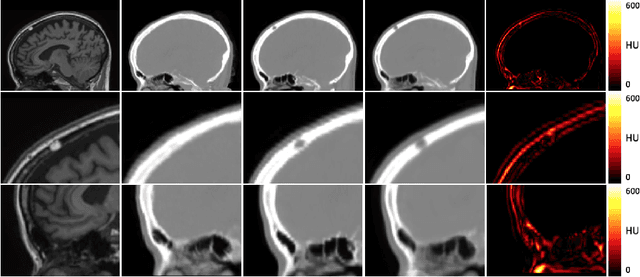
Attenuation correction is an essential requirement of positron emission tomography (PET) image reconstruction to allow for accurate quantification. However, attenuation correction is particularly challenging for PET-MRI as neither PET nor magnetic resonance imaging (MRI) can directly image tissue attenuation properties. MRI-based computed tomography (CT) synthesis has been proposed as an alternative to physics based and segmentation-based approaches that assign a population-based tissue density value in order to generate an attenuation map. We propose a novel deep fully convolutional neural network that generates synthetic CTs in a recursive manner by gradually reducing the residuals of the previous network, increasing the overall accuracy and generalisability, while keeping the number of trainable parameters within reasonable limits. The model is trained on a database of 20 pre-acquired MRI/CT pairs and a four-fold random bootstrapped validation with a 80:20 split is performed. Quantitative results show that the proposed framework outperforms a state-of-the-art atlas-based approach decreasing the Mean Absolute Error (MAE) from 131HU to 68HU for the synthetic CTs and reducing the PET reconstruction error from 14.3% to 7.2%.
Simultaneous synthesis of FLAIR and segmentation of white matter hypointensities from T1 MRIs
Aug 20, 2018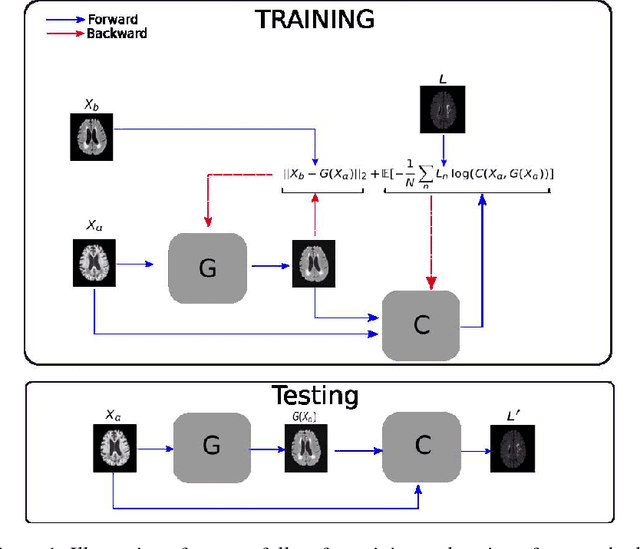
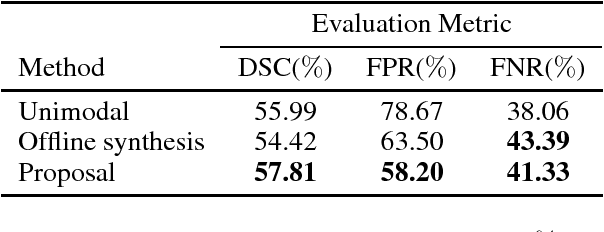
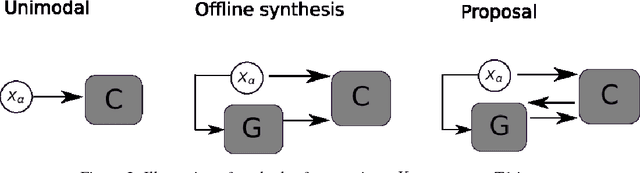
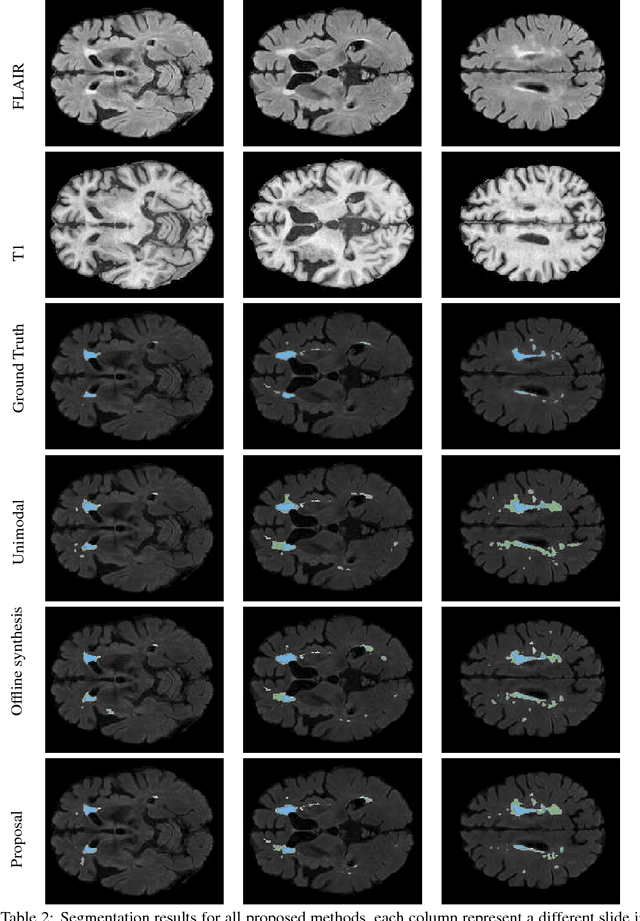
Segmenting vascular pathologies such as white matter lesions in Brain magnetic resonance images (MRIs) require acquisition of multiple sequences such as T1-weighted (T1-w) --on which lesions appear hypointense-- and fluid attenuated inversion recovery (FLAIR) sequence --where lesions appear hyperintense--. However, most of the existing retrospective datasets do not consist of FLAIR sequences. Existing missing modality imputation methods separate the process of imputation, and the process of segmentation. In this paper, we propose a method to link both modality imputation and segmentation using convolutional neural networks. We show that by jointly optimizing the imputation network and the segmentation network, the method not only produces more realistic synthetic FLAIR images from T1-w images, but also improves the segmentation of WMH from T1-w images only.
Robust training of recurrent neural networks to handle missing data for disease progression modeling
Aug 16, 2018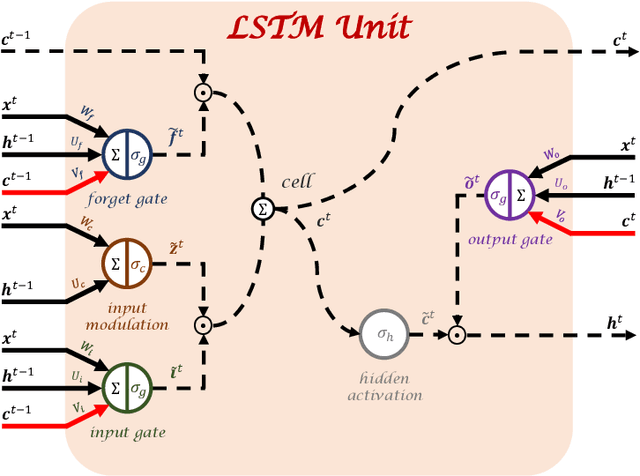



Disease progression modeling (DPM) using longitudinal data is a challenging task in machine learning for healthcare that can provide clinicians with better tools for diagnosis and monitoring of disease. Existing DPM algorithms neglect temporal dependencies among measurements and make parametric assumptions about biomarker trajectories. In addition, they do not model multiple biomarkers jointly and need to align subjects' trajectories. In this paper, recurrent neural networks (RNNs) are utilized to address these issues. However, in many cases, longitudinal cohorts contain incomplete data, which hinders the application of standard RNNs and requires a pre-processing step such as imputation of the missing values. We, therefore, propose a generalized training rule for the most widely used RNN architecture, long short-term memory (LSTM) networks, that can handle missing values in both target and predictor variables. This algorithm is applied for modeling the progression of Alzheimer's disease (AD) using magnetic resonance imaging (MRI) biomarkers. The results show that the proposed LSTM algorithm achieves a lower mean absolute error for prediction of measurements across all considered MRI biomarkers compared to using standard LSTM networks with data imputation or using a regression-based DPM method. Moreover, applying linear discriminant analysis to the biomarkers' values predicted by the proposed algorithm results in a larger area under the receiver operating characteristic curve (AUC) for clinical diagnosis of AD compared to the same alternatives, and the AUC is comparable to state-of-the-art AUCs from a recent cross-sectional medical image classification challenge. This paper shows that built-in handling of missing values in LSTM network training paves the way for application of RNNs in disease progression modeling.