 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Discounting and Learning over Multiple Horizons
Feb 28, 2019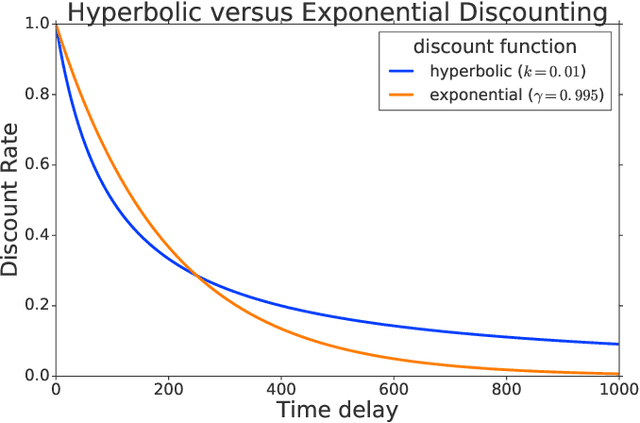

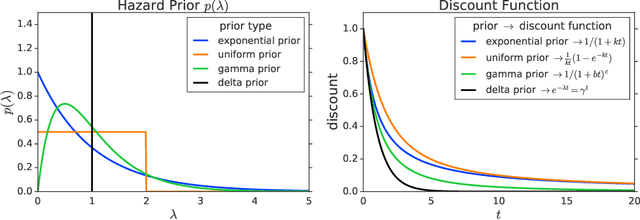
Reinforcement learning (RL) typically defines a discount factor as part of the Markov Decision Process. The discount factor values future rewards by an exponential scheme that leads to theoretical convergence guarantees of the Bellman equation. However, evidence from psychology, economics and neuroscience suggests that humans and animals instead have hyperbolic time-preferences. In this work we revisit the fundamentals of discounting in RL and bridge this disconnect by implementing an RL agent that acts via hyperbolic discounting. We demonstrate that a simple approach approximates hyperbolic discount functions while still using familiar temporal-difference learning techniques in RL. Additionally, and independent of hyperbolic discounting, we make a surprising discovery that simultaneously learning value functions over multiple time-horizons is an effective auxiliary task which often improves over a strong value-based RL agent, Rainbow.
Statistics and Samples in Distributional Reinforcement Learning
Feb 21, 2019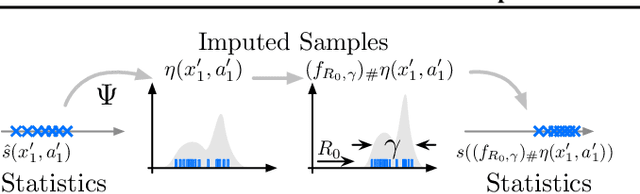
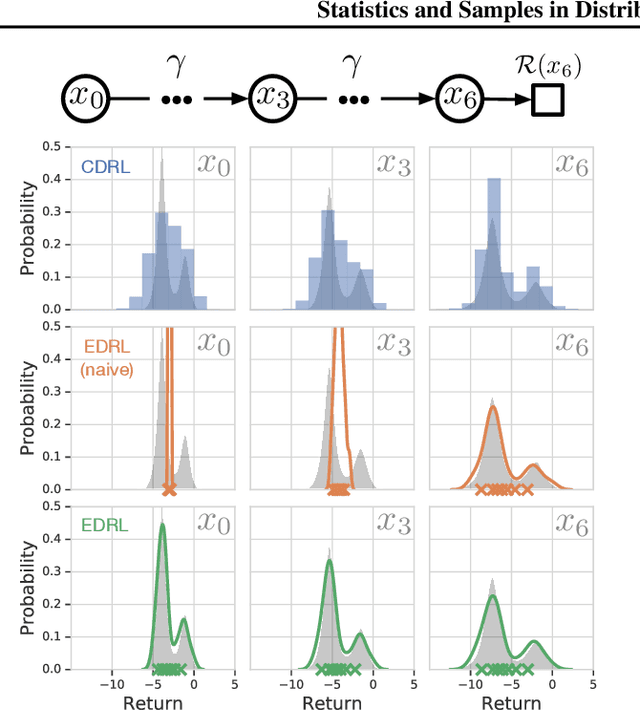
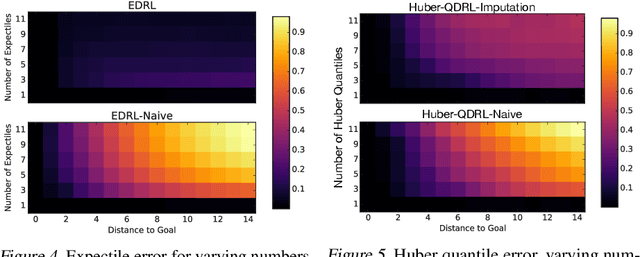
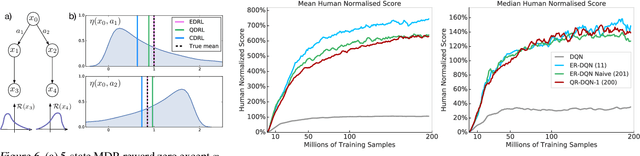
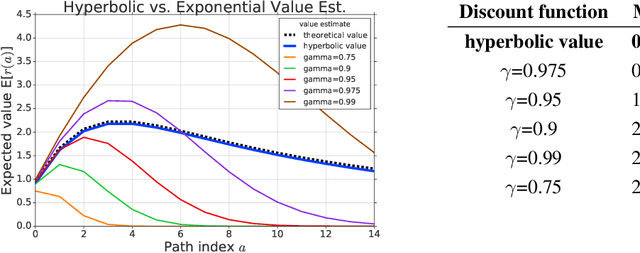
We present a unifying framework for designing and analysing distributional reinforcement learning (DRL) algorithms in terms of recursively estimating statistics of the return distribution. Our key insight is that DRL algorithms can be decomposed as the combination of some statistical estimator and a method for imputing a return distribution consistent with that set of statistics. With this new understanding, we are able to provide improved analyses of existing DRL algorithms as well as construct a new algorithm (EDRL) based upon estimation of the expectiles of the return distribution. We compare EDRL with existing methods on a variety of MDPs to illustrate concrete aspects of our analysis, and develop a deep RL variant of the algorithm, ER-DQN, which we evaluate on the Atari-57 suite of games.
A Comparative Analysis of Expected and Distributional Reinforcement Learning
Feb 21, 2019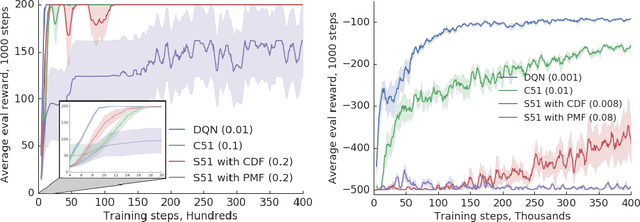
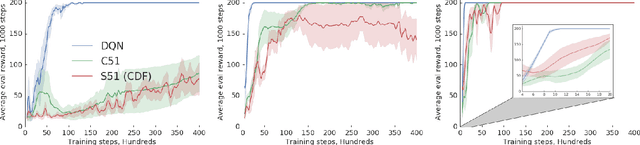
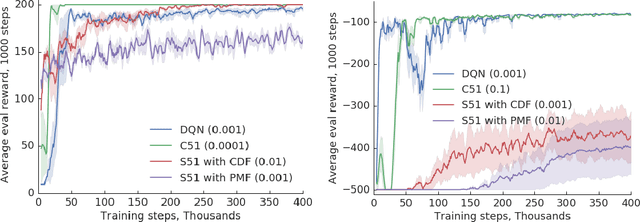
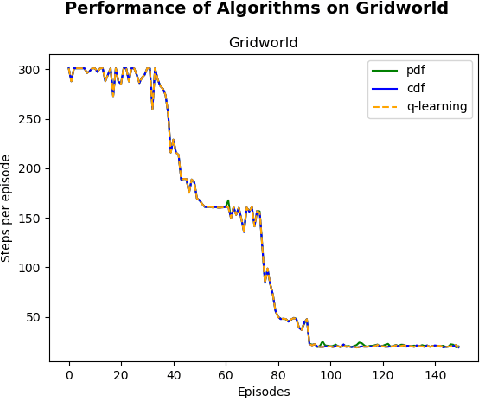
Since their introduction a year ago, distributional approaches to reinforcement learning (distributional RL) have produced strong results relative to the standard approach which models expected values (expected RL). However, aside from convergence guarantees, there have been few theoretical results investigating the reasons behind the improvements distributional RL provides. In this paper we begin the investigation into this fundamental question by analyzing the differences in the tabular, linear approximation, and non-linear approximation settings. We prove that in many realizations of the tabular and linear approximation settings, distributional RL behaves exactly the same as expected RL. In cases where the two methods behave differently, distributional RL can in fact hurt performance when it does not induce identical behaviour. We then continue with an empirical analysis comparing distributional and expected RL methods in control settings with non-linear approximators to tease apart where the improvements from distributional RL methods are coming from.
The Value Function Polytope in Reinforcement Learning
Feb 15, 2019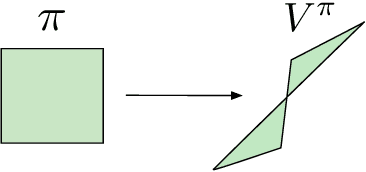
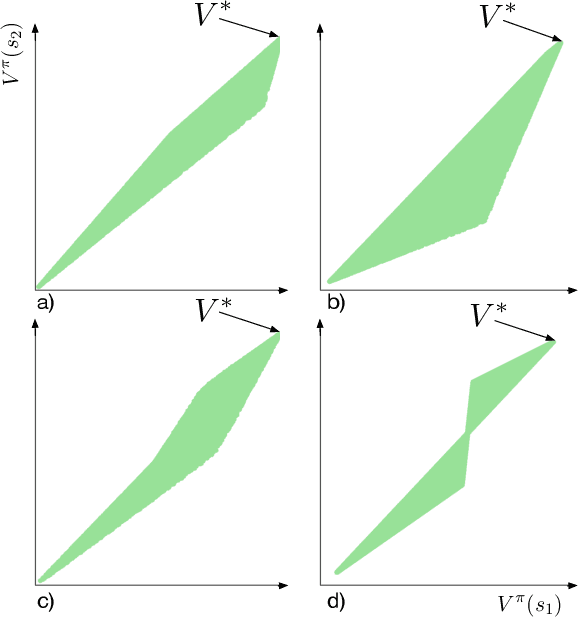
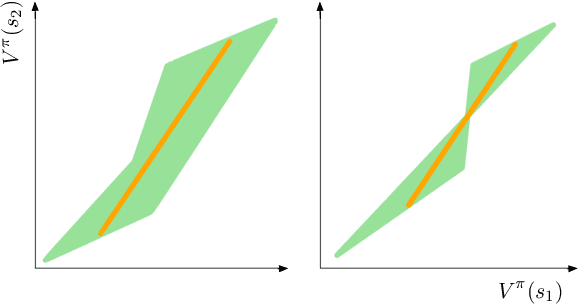
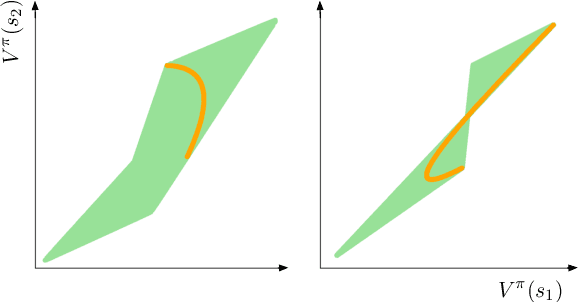
We establish geometric and topological properties of the space of value functions in finite state-action Markov decision processes. Our main contribution is the characterization of the nature of its shape: a general polytope (Aigner et al., 2010). To demonstrate this result, we exhibit several properties of the structural relationship between policies and value functions including the line theorem, which shows that the value functions of policies constrained on all but one state describe a line segment. Finally, we use this novel perspective to introduce visualizations to enhance the understanding of the dynamics of reinforcement learning algorithms.
Distributional reinforcement learning with linear function approximation
Feb 08, 2019
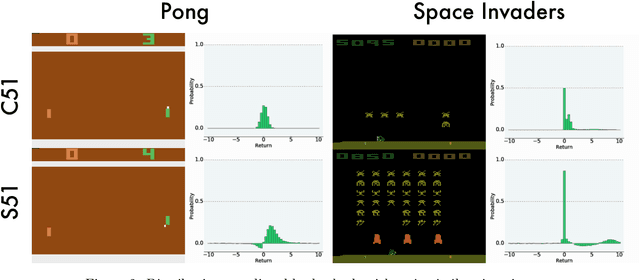
Despite many algorithmic advances, our theoretical understanding of practical distributional reinforcement learning methods remains limited. One exception is Rowland et al. (2018)'s analysis of the C51 algorithm in terms of the Cram\'er distance, but their results only apply to the tabular setting and ignore C51's use of a softmax to produce normalized distributions. In this paper we adapt the Cram\'er distance to deal with arbitrary vectors. From it we derive a new distributional algorithm which is fully Cram\'er-based and can be combined to linear function approximation, with formal guarantees in the context of policy evaluation. In allowing the model's prediction to be any real vector, we lose the probabilistic interpretation behind the method, but otherwise maintain the appealing properties of distributional approaches. To the best of our knowledge, ours is the first proof of convergence of a distributional algorithm combined with function approximation. Perhaps surprisingly, our results provide evidence that Cram\'er-based distributional methods may perform worse than directly approximating the value function.
* To appear
The Hanabi Challenge: A New Frontier for AI Research
Feb 01, 2019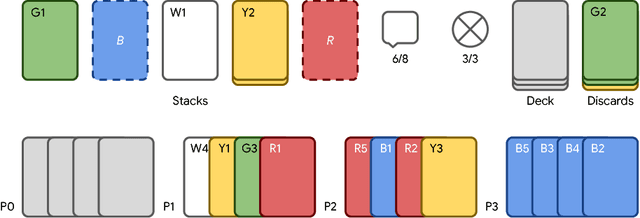
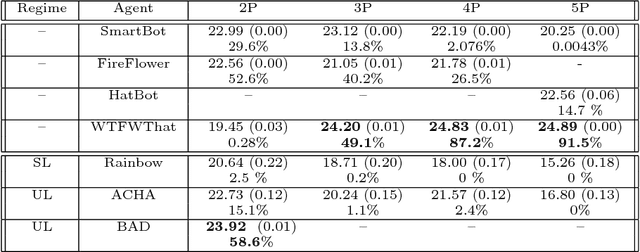
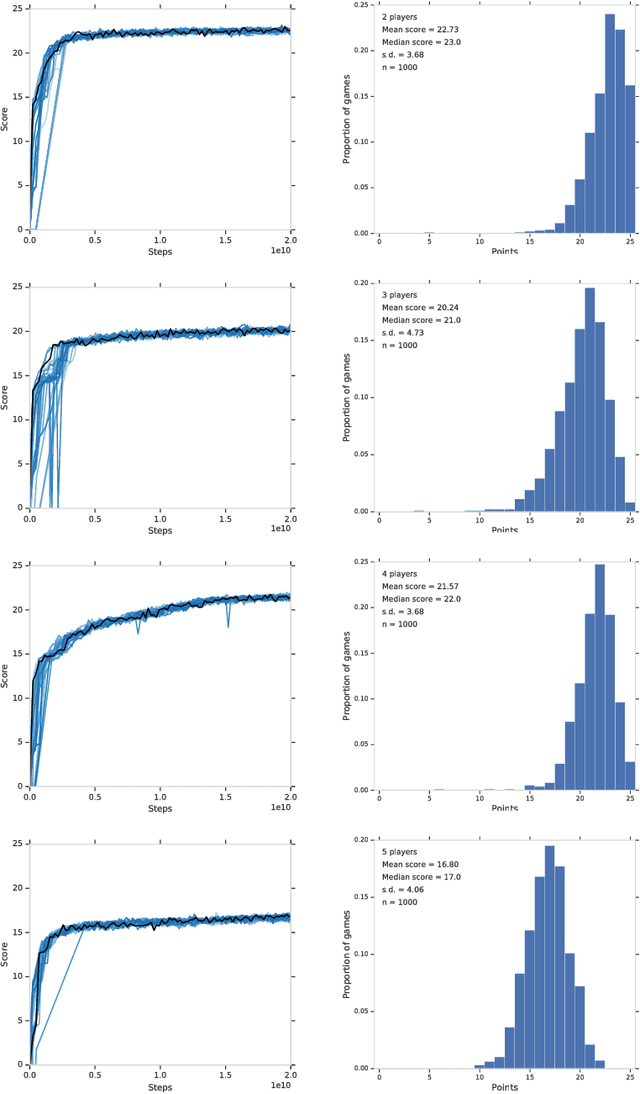
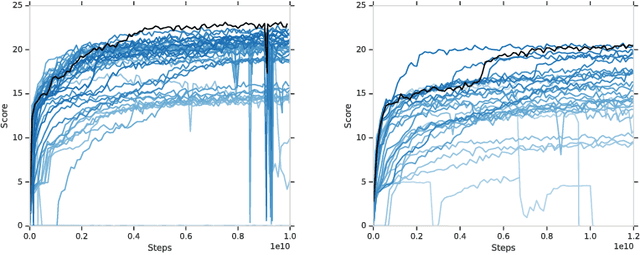
From the early days of computing, games have been important testbeds for studying how well machines can do sophisticated decision making. In recent years, machine learning has made dramatic advances with artificial agents reaching superhuman performance in challenge domains like Go, Atari, and some variants of poker. As with their predecessors of chess, checkers, and backgammon, these game domains have driven research by providing sophisticated yet well-defined challenges for artificial intelligence practitioners. We continue this tradition by proposing the game of Hanabi as a new challenge domain with novel problems that arise from its combination of purely cooperative gameplay and imperfect information in a two to five player setting. In particular, we argue that Hanabi elevates reasoning about the beliefs and intentions of other agents to the foreground. We believe developing novel techniques capable of imbuing artificial agents with such theory of mind will not only be crucial for their success in Hanabi, but also in broader collaborative efforts, and especially those with human partners. To facilitate future research, we introduce the open-source Hanabi Learning Environment, propose an experimental framework for the research community to evaluate algorithmic advances, and assess the performance of current state-of-the-art techniques.
A Geometric Perspective on Optimal Representations for Reinforcement Learning
Jan 31, 2019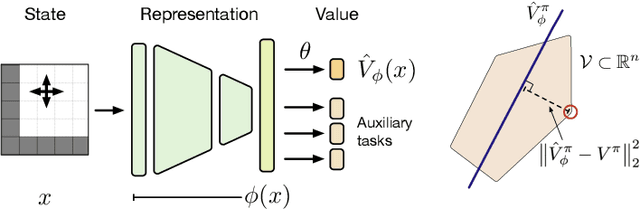
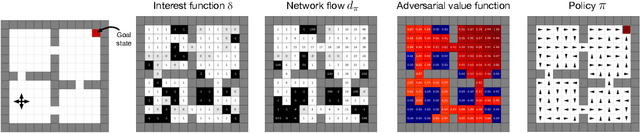
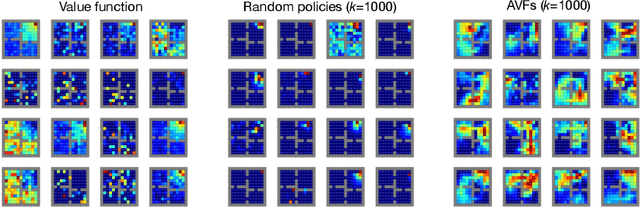
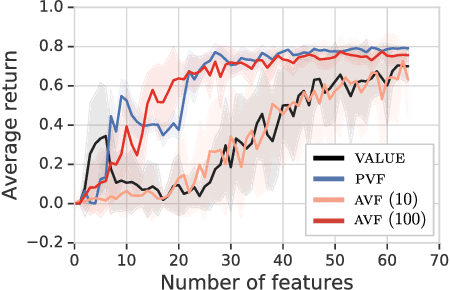
This paper proposes a new approach to representation learning based on geometric properties of the space of value functions. We study a two-part approximation of the value function: a nonlinear map from states to vectors, or representation, followed by a linear map from vectors to values. Our formulation considers adapting the representation to minimize the (linear) approximation of the value function of all stationary policies for a given environment. We show that this optimization reduces to making accurate predictions regarding a special class of value functions which we call adversarial value functions (AVFs). We argue that these AVFs make excellent auxiliary tasks, and use them to construct a loss which can be efficiently minimized to find a near-optimal representation for reinforcement learning. We highlight characteristics of the method in a series of experiments on the four-room domain.
Shaping the Narrative Arc: An Information-Theoretic Approach to Collaborative Dialogue
Jan 31, 2019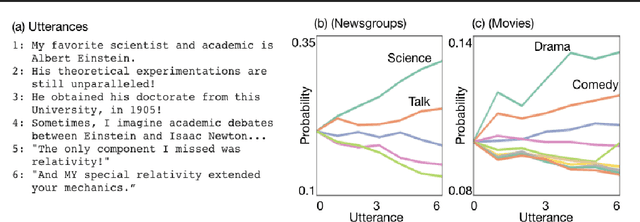
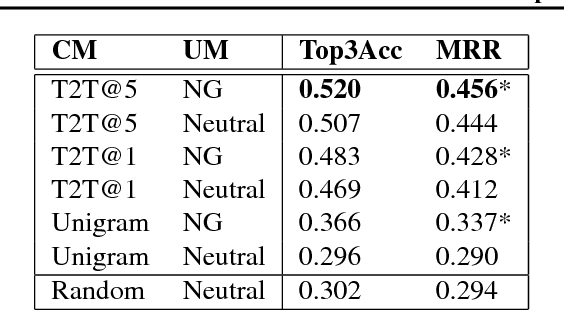
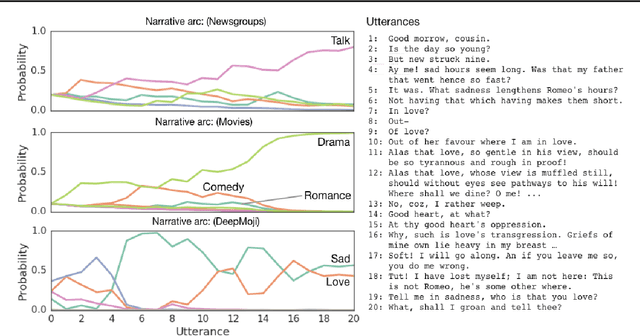
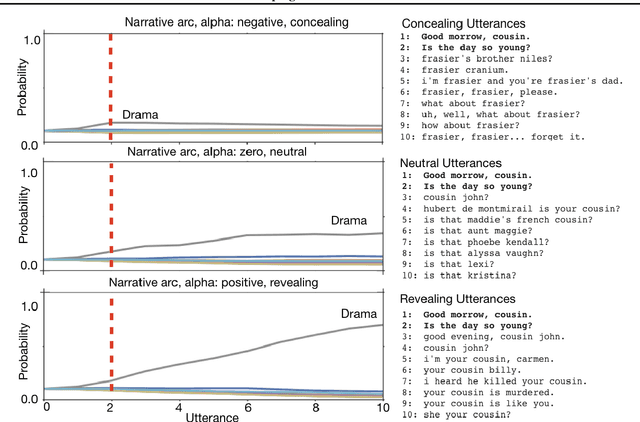
We consider the problem of designing an artificial agent capable of interacting with humans in collaborative dialogue to produce creative, engaging narratives. In this task, the goal is to establish universe details, and to collaborate on an interesting story in that universe, through a series of natural dialogue exchanges. Our model can augment any probabilistic conversational agent by allowing it to reason about universe information established and what potential next utterances might reveal. Ideally, with each utterance, agents would reveal just enough information to add specificity and reduce ambiguity without limiting the conversation. We empirically show that our model allows control over the rate at which the agent reveals information and that doing so significantly improves accuracy in predicting the next line of dialogues from movies. We close with a case-study with four professional theatre performers, who preferred interactions with our model-augmented agent over an unaugmented agent.
Off-Policy Deep Reinforcement Learning by Bootstrapping the Covariate Shift
Jan 27, 2019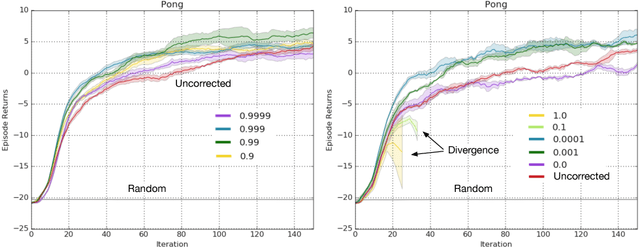


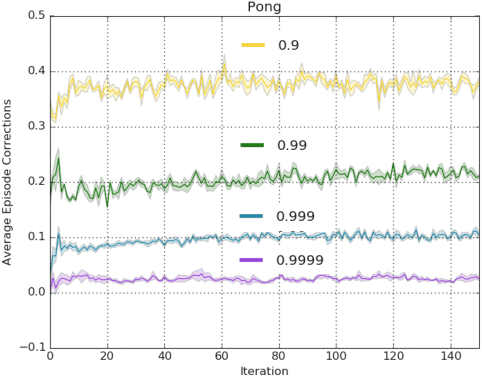
In this paper we revisit the method of off-policy corrections for reinforcement learning (COP-TD) pioneered by Hallak et al. (2017). Under this method, online updates to the value function are reweighted to avoid divergence issues typical of off-policy learning. While Hallak et al.'s solution is appealing, it cannot easily be transferred to nonlinear function approximation. First, it requires a projection step onto the probability simplex; second, even though the operator describing the expected behavior of the off-policy learning algorithm is convergent, it is not known to be a contraction mapping, and hence, may be more unstable in practice. We address these two issues by introducing a discount factor into COP-TD. We analyze the behavior of discounted COP-TD and find it better behaved from a theoretical perspective. We also propose an alternative soft normalization penalty that can be minimized online and obviates the need for an explicit projection step. We complement our analysis with an empirical evaluation of the two techniques in an off-policy setting on the game Pong from the Atari domain where we find discounted COP-TD to be better behaved in practice than the soft normalization penalty. Finally, we perform a more extensive evaluation of discounted COP-TD in 5 games of the Atari domain, where we find performance gains for our approach.
Dopamine: A Research Framework for Deep Reinforcement Learning
Dec 14, 2018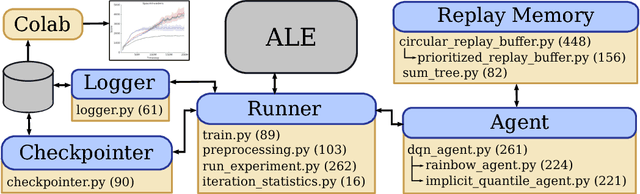
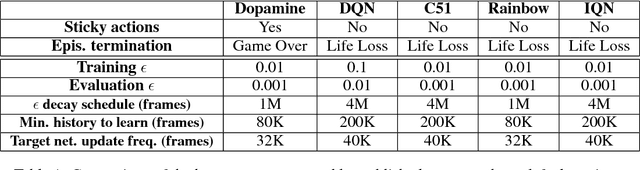

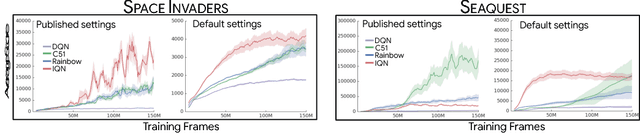
Deep reinforcement learning (deep RL) research has grown significantly in recent years. A number of software offerings now exist that provide stable, comprehensive implementations for benchmarking. At the same time, recent deep RL research has become more diverse in its goals. In this paper we introduce Dopamine, a new research framework for deep RL that aims to support some of that diversity. Dopamine is open-source, TensorFlow-based, and provides compact and reliable implementations of some state-of-the-art deep RL agents. We complement this offering with a taxonomy of the different research objectives in deep RL research. While by no means exhaustive, our analysis highlights the heterogeneity of research in the field, and the value of frameworks such as ours.