 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Execution of Action Chunking Flow Policies
Jun 09, 2025Modern AI systems, especially those interacting with the physical world, increasingly require real-time performance. However, the high latency of state-of-the-art generalist models, including recent vision-language action models (VLAs), poses a significant challenge. While action chunking has enabled temporal consistency in high-frequency control tasks, it does not fully address the latency problem, leading to pauses or out-of-distribution jerky movements at chunk boundaries. This paper presents a novel inference-time algorithm that enables smooth asynchronous execution of action chunking policies. Our method, real-time chunking (RTC), is applicable to any diffusion- or flow-based VLA out of the box with no re-training. It generates the next action chunk while executing the current one, "freezing" actions guaranteed to execute and "inpainting" the rest. To test RTC, we introduce a new benchmark of 12 highly dynamic tasks in the Kinetix simulator, as well as evaluate 6 challenging real-world bimanual manipulation tasks. Results demonstrate that RTC is fast, performant, and uniquely robust to inference delay, significantly improving task throughput and enabling high success rates in precise tasks $\unicode{x2013}$ such as lighting a match $\unicode{x2013}$ even in the presence of significant latency. See https://pi.website/research/real_time_chunking for videos.
$π_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Apr 22, 2025



In order for robots to be useful, they must perform practically relevant tasks in the real world, outside of the lab. While vision-language-action (VLA) models have demonstrated impressive results for end-to-end robot control, it remains an open question how far such models can generalize in the wild. We describe $\pi_{0.5}$, a new model based on $\pi_{0}$ that uses co-training on heterogeneous tasks to enable broad generalization. $\pi_{0.5}$\ uses data from multiple robots, high-level semantic prediction, web data, and other sources to enable broadly generalizable real-world robotic manipulation. Our system uses a combination of co-training and hybrid multi-modal examples that combine image observations, language commands, object detections, semantic subtask prediction, and low-level actions. Our experiments show that this kind of knowledge transfer is essential for effective generalization, and we demonstrate for the first time that an end-to-end learning-enabled robotic system can perform long-horizon and dexterous manipulation skills, such as cleaning a kitchen or bedroom, in entirely new homes.
Bipedal Locomotion with Nonlinear Model Predictive Control: Online Gait Generation using Whole-Body Dynamics
Mar 14, 2022
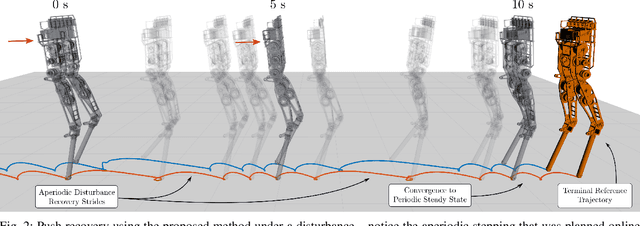
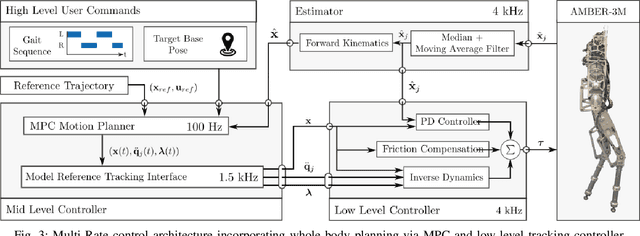
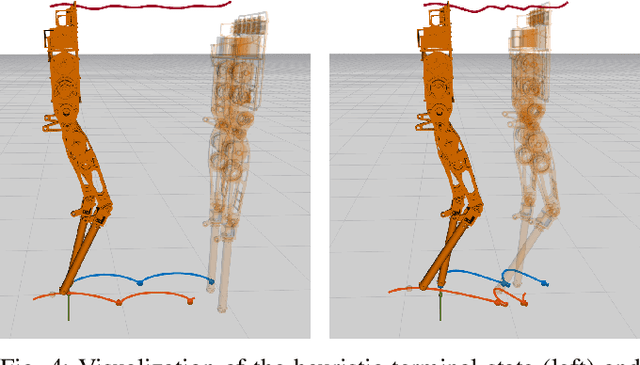
The ability to generate dynamic walking in real-time for bipedal robots with compliance and underactuation has the potential to enable locomotion in complex and unstructured environments. Yet, the high-dimensional nature of bipedal robots has limited the use of full-order rigid body dynamics to gaits which are synthesized offline and then tracked online, e.g., via whole-body controllers. In this work we develop an online nonlinear model predictive control approach that leverages the full-order dynamics to realize diverse walking behaviors. Additionally, this approach can be coupled with gaits synthesized offline via a terminal cost that enables a shorter prediction horizon; this makes rapid online re-planning feasible and bridges the gap between online reactive control and offline gait planning. We demonstrate the proposed method on the planar robot AMBER-3M, both in simulation and on hardware.