 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Approach to Evaluate Sentence-Level Fluency: Do We Really Need Reference?
Dec 03, 2023



Fluency is a crucial goal of all Natural Language Generation (NLG) systems. Widely used automatic evaluation metrics fall short in capturing the fluency of machine-generated text. Assessing the fluency of NLG systems poses a challenge since these models are not limited to simply reusing words from the input but may also generate abstractions. Existing reference-based fluency evaluations, such as word overlap measures, often exhibit weak correlations with human judgments. This paper adapts an existing unsupervised technique for measuring text fluency without the need for any reference. Our approach leverages various word embeddings and trains language models using Recurrent Neural Network (RNN) architectures. We also experiment with other available multilingual Language Models (LMs). To assess the performance of the models, we conduct a comparative analysis across 10 Indic languages, correlating the obtained fluency scores with human judgments. Our code and human-annotated benchmark test-set for fluency is available at https://github.com/AnanyaCoder/TextFluencyForIndicLanaguges.
Mukhyansh: A Headline Generation Dataset for Indic Languages
Nov 29, 2023



The task of headline generation within the realm of Natural Language Processing (NLP) holds immense significance, as it strives to distill the true essence of textual content into concise and attention-grabbing summaries. While noteworthy progress has been made in headline generation for widely spoken languages like English, there persist numerous challenges when it comes to generating headlines in low-resource languages, such as the rich and diverse Indian languages. A prominent obstacle that specifically hinders headline generation in Indian languages is the scarcity of high-quality annotated data. To address this crucial gap, we proudly present Mukhyansh, an extensive multilingual dataset, tailored for Indian language headline generation. Comprising an impressive collection of over 3.39 million article-headline pairs, Mukhyansh spans across eight prominent Indian languages, namely Telugu, Tamil, Kannada, Malayalam, Hindi, Bengali, Marathi, and Gujarati. We present a comprehensive evaluation of several state-of-the-art baseline models. Additionally, through an empirical analysis of existing works, we demonstrate that Mukhyansh outperforms all other models, achieving an impressive average ROUGE-L score of 31.43 across all 8 languages.
X-RiSAWOZ: High-Quality End-to-End Multilingual Dialogue Datasets and Few-shot Agents
Jun 30, 2023



Task-oriented dialogue research has mainly focused on a few popular languages like English and Chinese, due to the high dataset creation cost for a new language. To reduce the cost, we apply manual editing to automatically translated data. We create a new multilingual benchmark, X-RiSAWOZ, by translating the Chinese RiSAWOZ to 4 languages: English, French, Hindi, Korean; and a code-mixed English-Hindi language. X-RiSAWOZ has more than 18,000 human-verified dialogue utterances for each language, and unlike most multilingual prior work, is an end-to-end dataset for building fully-functioning agents. The many difficulties we encountered in creating X-RiSAWOZ led us to develop a toolset to accelerate the post-editing of a new language dataset after translation. This toolset improves machine translation with a hybrid entity alignment technique that combines neural with dictionary-based methods, along with many automated and semi-automated validation checks. We establish strong baselines for X-RiSAWOZ by training dialogue agents in the zero- and few-shot settings where limited gold data is available in the target language. Our results suggest that our translation and post-editing methodology and toolset can be used to create new high-quality multilingual dialogue agents cost-effectively. Our dataset, code, and toolkit are released open-source.
PMIndiaSum: Multilingual and Cross-lingual Headline Summarization for Languages in India
May 15, 2023This paper introduces PMIndiaSum, a new multilingual and massively parallel headline summarization corpus focused on languages in India. Our corpus covers four language families, 14 languages, and the largest to date, 196 language pairs. It provides a testing ground for all cross-lingual pairs. We detail our workflow to construct the corpus, including data acquisition, processing, and quality assurance. Furthermore, we publish benchmarks for monolingual, cross-lingual, and multilingual summarization by fine-tuning, prompting, as well as translate-and-summarize. Experimental results confirm the crucial role of our data in aiding the summarization of Indian texts. Our dataset is publicly available and can be freely modified and re-distributed.
Attention at SemEval-2023 Task 10: Explainable Detection of Online Sexism
Apr 10, 2023



In this paper, we have worked on interpretability, trust, and understanding of the decisions made by models in the form of classification tasks. The task is divided into 3 subtasks. The first task consists of determining Binary Sexism Detection. The second task describes the Category of Sexism. The third task describes a more Fine-grained Category of Sexism. Our work explores solving these tasks as a classification problem by fine-tuning transformer-based architecture. We have performed several experiments with our architecture, including combining multiple transformers, using domain adaptive pretraining on the unlabelled dataset provided by Reddit and Gab, Joint learning, and taking different layers of transformers as input to a classification head. Our system (with team name Attention) was able to achieve a macro F1 score of 0.839 for task A, 0.5835 macro F1 score for task B and 0.3356 macro F1 score for task C at the Codalab SemEval Competition. Later we improved the accuracy of Task B to 0.6228 and Task C to 0.3693 in the test set.
Indian Language Summarization using Pretrained Sequence-to-Sequence Models
Mar 25, 2023



The ILSUM shared task focuses on text summarization for two major Indian languages- Hindi and Gujarati, along with English. In this task, we experiment with various pretrained sequence-to-sequence models to find out the best model for each of the languages. We present a detailed overview of the models and our approaches in this paper. We secure the first rank across all three sub-tasks (English, Hindi and Gujarati). This paper also extensively analyzes the impact of k-fold cross-validation while experimenting with limited data size, and we also perform various experiments with a combination of the original and a filtered version of the data to determine the efficacy of the pretrained models.
Generalised Spherical Text Embedding
Nov 30, 2022This paper aims to provide an unsupervised modelling approach that allows for a more flexible representation of text embeddings. It jointly encodes the words and the paragraphs as individual matrices of arbitrary column dimension with unit Frobenius norm. The representation is also linguistically motivated with the introduction of a novel similarity metric. The proposed modelling and the novel similarity metric exploits the matrix structure of embeddings. We then go on to show that the same matrices can be reshaped into vectors of unit norm and transform our problem into an optimization problem over the spherical manifold. We exploit manifold optimization to efficiently train the matrix embeddings. We also quantitatively verify the quality of our text embeddings by showing that they demonstrate improved results in document classification, document clustering, and semantic textual similarity benchmark tests.
Diverse Multi-Answer Retrieval with Determinantal Point Processes
Nov 29, 2022

Often questions provided to open-domain question answering systems are ambiguous. Traditional QA systems that provide a single answer are incapable of answering ambiguous questions since the question may be interpreted in several ways and may have multiple distinct answers. In this paper, we address multi-answer retrieval which entails retrieving passages that can capture majority of the diverse answers to the question. We propose a re-ranking based approach using Determinantal point processes utilizing BERT as kernels. Our method jointly considers query-passage relevance and passage-passage correlation to retrieve passages that are both query-relevant and diverse. Results demonstrate that our re-ranking technique outperforms state-of-the-art method on the AmbigQA dataset.
Leveraging Data Recasting to Enhance Tabular Reasoning
Nov 23, 2022



Creating challenging tabular inference data is essential for learning complex reasoning. Prior work has mostly relied on two data generation strategies. The first is human annotation, which yields linguistically diverse data but is difficult to scale. The second category for creation is synthetic generation, which is scalable and cost effective but lacks inventiveness. In this research, we present a framework for semi-automatically recasting existing tabular data to make use of the benefits of both approaches. We utilize our framework to build tabular NLI instances from five datasets that were initially intended for tasks like table2text creation, tabular Q/A, and semantic parsing. We demonstrate that recasted data could be used as evaluation benchmarks as well as augmentation data to enhance performance on tabular NLI tasks. Furthermore, we investigate the effectiveness of models trained on recasted data in the zero-shot scenario, and analyse trends in performance across different recasted datasets types.
PreCogIIITH at HinglishEval : Leveraging Code-Mixing Metrics & Language Model Embeddings To Estimate Code-Mix Quality
Jun 16, 2022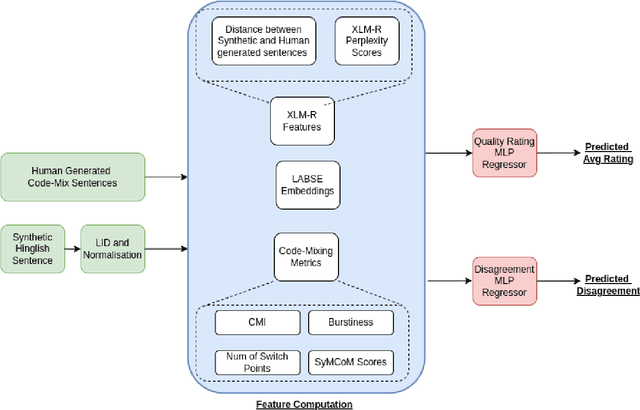

Code-Mixing is a phenomenon of mixing two or more languages in a speech event and is prevalent in multilingual societies. Given the low-resource nature of Code-Mixing, machine generation of code-mixed text is a prevalent approach for data augmentation. However, evaluating the quality of such machine generated code-mixed text is an open problem. In our submission to HinglishEval, a shared-task collocated with INLG2022, we attempt to build models factors that impact the quality of synthetically generated code-mix text by predicting ratings for code-mix quality.