 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHEMM: Holistic Evaluation of Multimodal Foundation Models
Jul 03, 2024



Multimodal foundation models that can holistically process text alongside images, video, audio, and other sensory modalities are increasingly used in a variety of real-world applications. However, it is challenging to characterize and study progress in multimodal foundation models, given the range of possible modeling decisions, tasks, and domains. In this paper, we introduce Holistic Evaluation of Multimodal Models (HEMM) to systematically evaluate the capabilities of multimodal foundation models across a set of 3 dimensions: basic skills, information flow, and real-world use cases. Basic multimodal skills are internal abilities required to solve problems, such as learning interactions across modalities, fine-grained alignment, multi-step reasoning, and the ability to handle external knowledge. Information flow studies how multimodal content changes during a task through querying, translation, editing, and fusion. Use cases span domain-specific challenges introduced in real-world multimedia, affective computing, natural sciences, healthcare, and human-computer interaction applications. Through comprehensive experiments across the 30 tasks in HEMM, we (1) identify key dataset dimensions (e.g., basic skills, information flows, and use cases) that pose challenges to today's models, and (2) distill performance trends regarding how different modeling dimensions (e.g., scale, pre-training data, multimodal alignment, pre-training, and instruction tuning objectives) influence performance. Our conclusions regarding challenging multimodal interactions, use cases, and tasks requiring reasoning and external knowledge, the benefits of data and model scale, and the impacts of instruction tuning yield actionable insights for future work in multimodal foundation models.
PreCogIIITH at HinglishEval : Leveraging Code-Mixing Metrics & Language Model Embeddings To Estimate Code-Mix Quality
Jun 16, 2022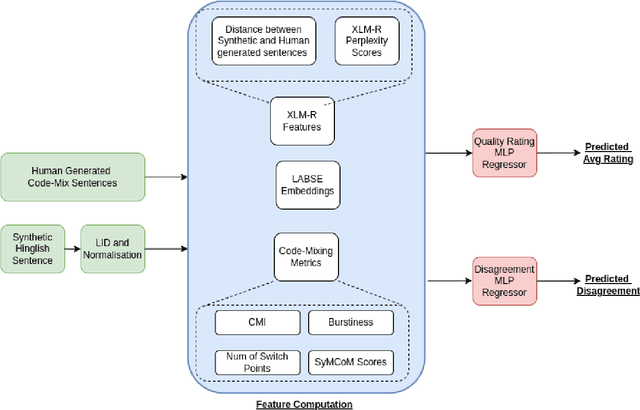

Code-Mixing is a phenomenon of mixing two or more languages in a speech event and is prevalent in multilingual societies. Given the low-resource nature of Code-Mixing, machine generation of code-mixed text is a prevalent approach for data augmentation. However, evaluating the quality of such machine generated code-mixed text is an open problem. In our submission to HinglishEval, a shared-task collocated with INLG2022, we attempt to build models factors that impact the quality of synthetically generated code-mix text by predicting ratings for code-mix quality.
Reappraising Domain Generalization in Neural Networks
Oct 15, 2021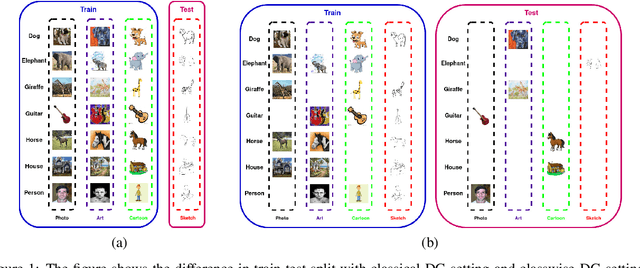


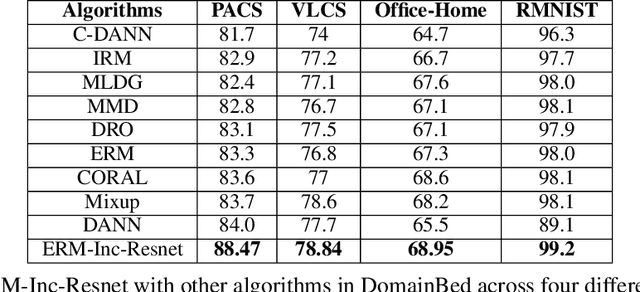
Domain generalization (DG) of machine learning algorithms is defined as their ability to learn a domain agnostic hypothesis from multiple training distributions, which generalizes onto data from an unseen domain. DG is vital in scenarios where the target domain with distinct characteristics has sparse data for training. Aligning with recent work~\cite{gulrajani2020search}, we find that a straightforward Empirical Risk Minimization (ERM) baseline consistently outperforms existing DG methods. We present ablation studies indicating that the choice of backbone, data augmentation, and optimization algorithms overshadows the many tricks and trades explored in the prior art. Our work leads to a new state of the art on the four popular DG datasets, surpassing previous methods by large margins. Furthermore, as a key contribution, we propose a classwise-DG formulation, where for each class, we randomly select one of the domains and keep it aside for testing. We argue that this benchmarking is closer to human learning and relevant in real-world scenarios. We comprehensively benchmark classwise-DG on the DomainBed and propose a method combining ERM and reverse gradients to achieve the state-of-the-art results. To our surprise, despite being exposed to all domains during training, the classwise DG is more challenging than traditional DG evaluation and motivates more fundamental rethinking on the problem of DG.
A Dynamic Head Importance Computation Mechanism for Neural Machine Translation
Aug 03, 2021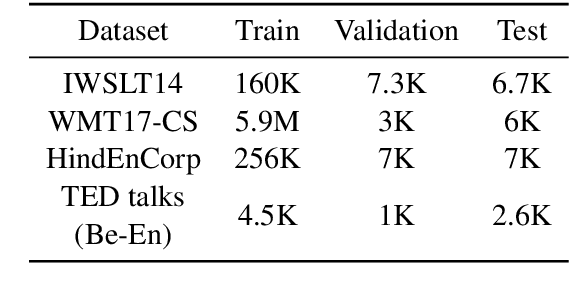
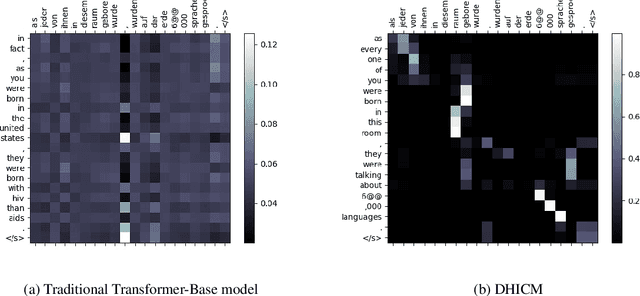
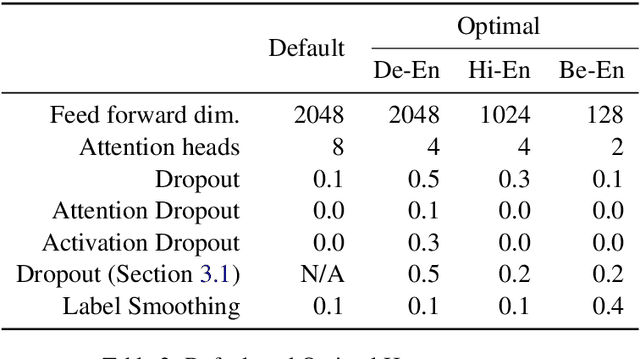
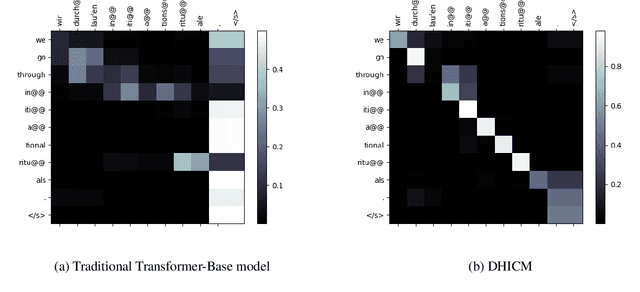
Multiple parallel attention mechanisms that use multiple attention heads facilitate greater performance of the Transformer model for various applications e.g., Neural Machine Translation (NMT), text classification. In multi-head attention mechanism, different heads attend to different parts of the input. However, the limitation is that multiple heads might attend to the same part of the input, resulting in multiple heads being redundant. Thus, the model resources are under-utilized. One approach to avoid this is to prune least important heads based on certain importance score. In this work, we focus on designing a Dynamic Head Importance Computation Mechanism (DHICM) to dynamically calculate the importance of a head with respect to the input. Our insight is to design an additional attention layer together with multi-head attention, and utilize the outputs of the multi-head attention along with the input, to compute the importance for each head. Additionally, we add an extra loss function to prevent the model from assigning same score to all heads, to identify more important heads and improvise performance. We analyzed performance of DHICM for NMT with different languages. Experiments on different datasets show that DHICM outperforms traditional Transformer-based approach by large margin, especially, when less training data is available.