 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPORTSQL: An Interactive System for Real-Time Sports Reasoning and Visualization
Aug 23, 2025We present a modular, interactive system, SPORTSQL, for natural language querying and visualization of dynamic sports data, with a focus on the English Premier League (EPL). The system translates user questions into executable SQL over a live, temporally indexed database constructed from real-time Fantasy Premier League (FPL) data. It supports both tabular and visual outputs, leveraging the symbolic reasoning capabilities of Large Language Models (LLMs) for query parsing, schema linking, and visualization selection. To evaluate system performance, we introduce the Dynamic Sport Question Answering benchmark (DSQABENCH), comprising 1,700+ queries annotated with SQL programs, gold answers, and database snapshots. Our demo highlights how non-expert users can seamlessly explore evolving sports statistics through a natural, conversational interface.
Map&Make: Schema Guided Text to Table Generation
May 29, 2025Transforming dense, detailed, unstructured text into an interpretable and summarised table, also colloquially known as Text-to-Table generation, is an essential task for information retrieval. Current methods, however, miss out on how and what complex information to extract; they also lack the ability to infer data from the text. In this paper, we introduce a versatile approach, Map&Make, which "dissects" text into propositional atomic statements. This facilitates granular decomposition to extract the latent schema. The schema is then used to populate the tables that capture the qualitative nuances and the quantitative facts in the original text. Our approach is tested against two challenging datasets, Rotowire, renowned for its complex and multi-table schema, and Livesum, which demands numerical aggregation. By carefully identifying and correcting hallucination errors in Rotowire, we aim to achieve a cleaner and more reliable benchmark. We evaluate our method rigorously on a comprehensive suite of comparative and referenceless metrics. Our findings demonstrate significant improvement results across both datasets with better interpretability in Text-to-Table generation. Moreover, through detailed ablation studies and analyses, we investigate the factors contributing to superior performance and validate the practicality of our framework in structured summarization tasks.
All You Need is "Leet": Evading Hate-speech Detection AI
May 22, 2025Social media and online forums are increasingly becoming popular. Unfortunately, these platforms are being used for spreading hate speech. In this paper, we design black-box techniques to protect users from hate-speech on online platforms by generating perturbations that can fool state of the art deep learning based hate speech detection models thereby decreasing their efficiency. We also ensure a minimal change in the original meaning of hate-speech. Our best perturbation attack is successfully able to evade hate-speech detection for 86.8 % of hateful text.
PreCogIIITH at HinglishEval : Leveraging Code-Mixing Metrics & Language Model Embeddings To Estimate Code-Mix Quality
Jun 16, 2022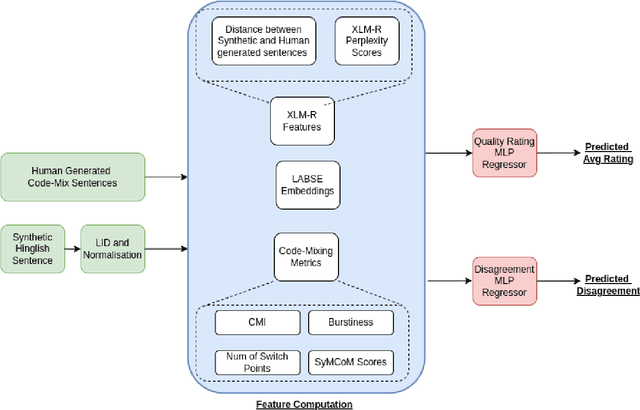

Code-Mixing is a phenomenon of mixing two or more languages in a speech event and is prevalent in multilingual societies. Given the low-resource nature of Code-Mixing, machine generation of code-mixed text is a prevalent approach for data augmentation. However, evaluating the quality of such machine generated code-mixed text is an open problem. In our submission to HinglishEval, a shared-task collocated with INLG2022, we attempt to build models factors that impact the quality of synthetically generated code-mix text by predicting ratings for code-mix quality.
HashSet -- A Dataset For Hashtag Segmentation
Jan 18, 2022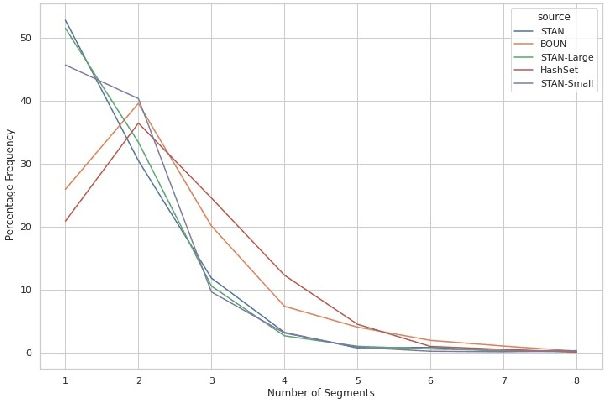
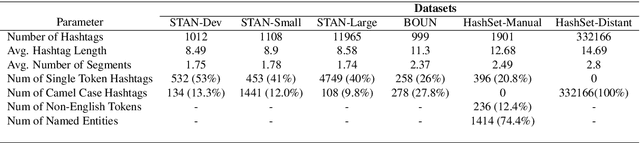
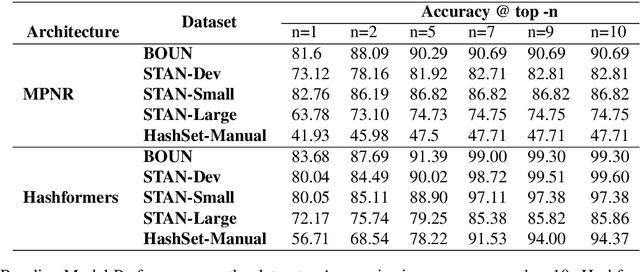

Hashtag segmentation is the task of breaking a hashtag into its constituent tokens. Hashtags often encode the essence of user-generated posts, along with information like topic and sentiment, which are useful in downstream tasks. Hashtags prioritize brevity and are written in unique ways -- transliterating and mixing languages, spelling variations, creative named entities. Benchmark datasets used for the hashtag segmentation task -- STAN, BOUN -- are small in size and extracted from a single set of tweets. However, datasets should reflect the variations in writing styles of hashtags and also account for domain and language specificity, failing which the results will misrepresent model performance. We argue that model performance should be assessed on a wider variety of hashtags, and datasets should be carefully curated. To this end, we propose HashSet, a dataset comprising of: a) 1.9k manually annotated dataset; b) 3.3M loosely supervised dataset. HashSet dataset is sampled from a different set of tweets when compared to existing datasets and provides an alternate distribution of hashtags to build and validate hashtag segmentation models. We show that the performance of SOTA models for Hashtag Segmentation drops substantially on proposed dataset, indicating that the proposed dataset provides an alternate set of hashtags to train and assess models.