 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025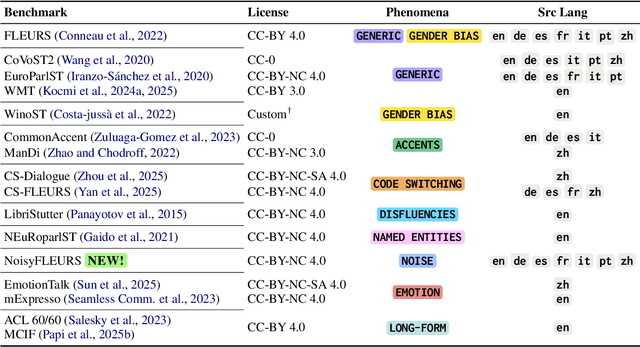
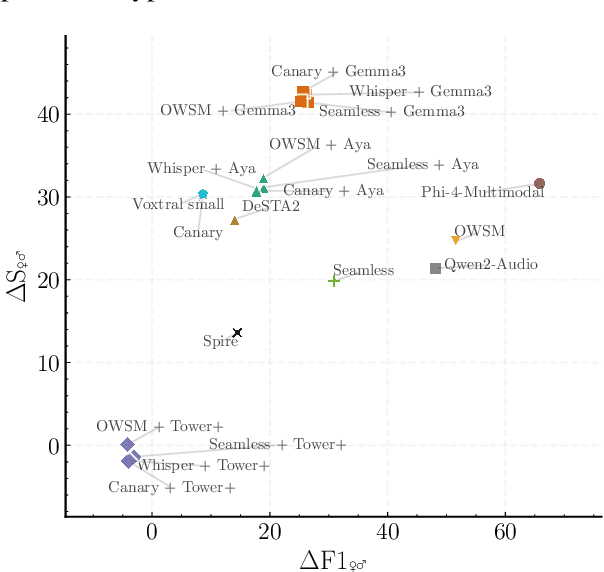
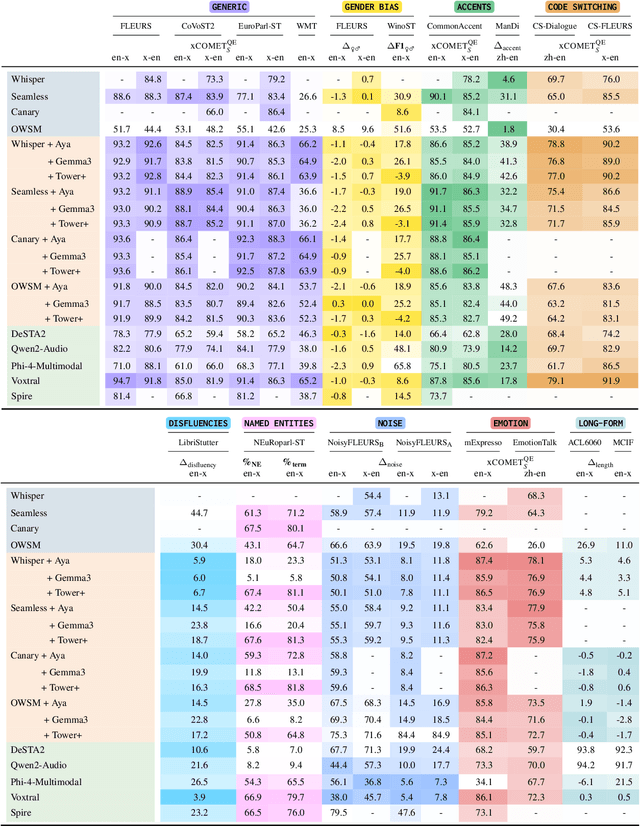
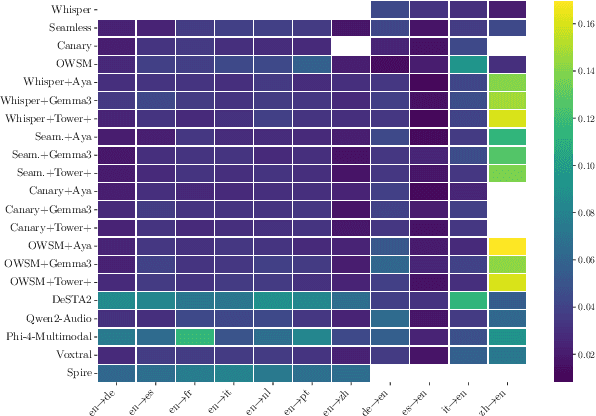
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
ACADATA: Parallel Dataset of Academic Data for Machine Translation
Oct 14, 2025



We present ACADATA, a high-quality parallel dataset for academic translation, that consists of two subsets: ACAD-TRAIN, which contains approximately 1.5 million author-generated paragraph pairs across 96 language directions and ACAD-BENCH, a curated evaluation set of almost 6,000 translations covering 12 directions. To validate its utility, we fine-tune two Large Language Models (LLMs) on ACAD-TRAIN and benchmark them on ACAD-BENCH against specialized machine-translation systems, general-purpose, open-weight LLMs, and several large-scale proprietary models. Experimental results demonstrate that fine-tuning on ACAD-TRAIN leads to improvements in academic translation quality by +6.1 and +12.4 d-BLEU points on average for 7B and 2B models respectively, while also improving long-context translation in a general domain by up to 24.9% when translating out of English. The fine-tuned top-performing model surpasses the best propietary and open-weight models on academic translation domain. By releasing ACAD-TRAIN, ACAD-BENCH and the fine-tuned models, we provide the community with a valuable resource to advance research in academic domain and long-context translation.