 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenization and Morphological Fidelity in Uralic NLP: A Cross-Lingual Evaluation
Feb 04, 2026Subword tokenization critically affects Natural Language Processing (NLP) performance, yet its behavior in morphologically rich and low-resource language families remains under-explored. This study systematically compares three subword paradigms -- Byte Pair Encoding (BPE), Overlap BPE (OBPE), and Unigram Language Model -- across six Uralic languages with varying resource availability and typological diversity. Using part-of-speech (POS) tagging as a controlled downstream task, we show that OBPE consistently achieves stronger morphological alignment and higher tagging accuracy than conventional methods, particularly within the Latin-script group. These gains arise from reduced fragmentation in open-class categories and a better balance across the frequency spectrum. Transfer efficacy further depends on the downstream tagging architecture, interacting with both training volume and genealogical proximity. Taken together, these findings highlight that morphology-sensitive tokenization is not merely a preprocessing choice but a decisive factor in enabling effective cross-lingual transfer for agglutinative, low-resource languages.
Do LLMs Truly Benefit from Longer Context in Automatic Post-Editing?
Jan 27, 2026Automatic post-editing (APE) aims to refine machine translations by correcting residual errors. Although recent large language models (LLMs) demonstrate strong translation capabilities, their effectiveness for APE--especially under document-level context--remains insufficiently understood. We present a systematic comparison of proprietary and open-weight LLMs under a naive document-level prompting setup, analyzing APE quality, contextual behavior, robustness, and efficiency. Our results show that proprietary LLMs achieve near human-level APE quality even with simple one-shot prompting, regardless of whether document context is provided. While these models exhibit higher robustness to data poisoning attacks than open-weight counterparts, this robustness also reveals a limitation: they largely fail to exploit document-level context for contextual error correction. Furthermore, standard automatic metrics do not reliably reflect these qualitative improvements, highlighting the continued necessity of human evaluation. Despite their strong performance, the substantial cost and latency overheads of proprietary LLMs render them impractical for real-world APE deployment. Overall, our findings elucidate both the promise and current limitations of LLM-based document-aware APE, and point toward the need for more efficient long-context modeling approaches for translation refinement.
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025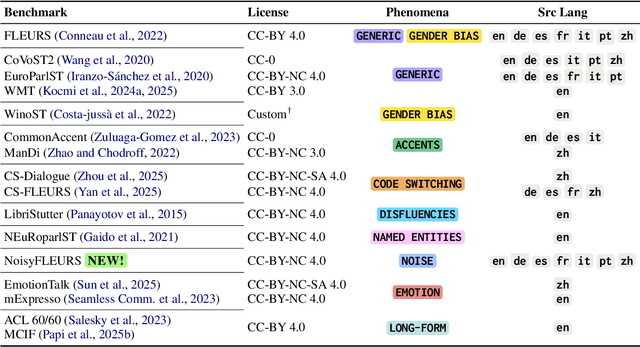
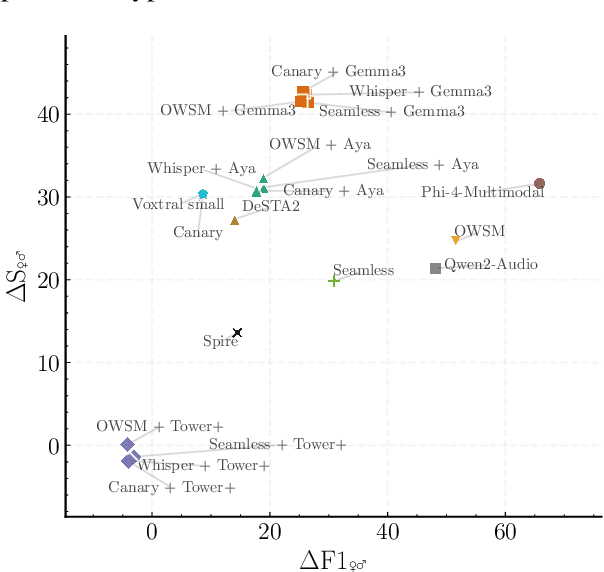
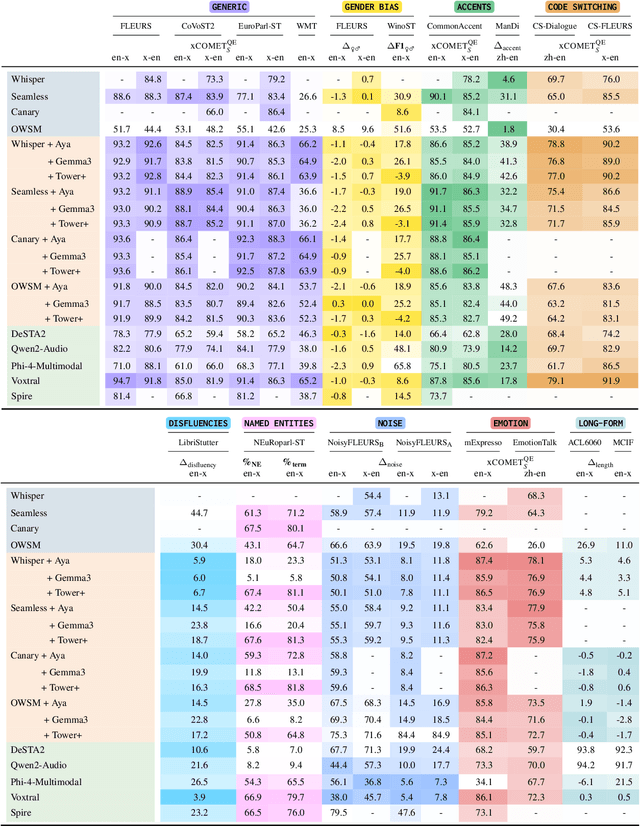
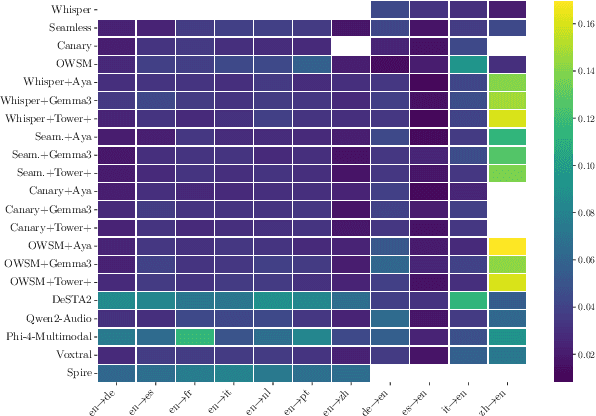
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.