 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRankGraph-2: Lifecycle Co-Design for Billion-Node Graph Learning in Recommendation
Jun 16, 2026Graph-based retrieval at billion-node scale requires jointly solving three tightly coupled problems -- graph construction, representation learning, and real-time serving -- yet existing work addresses each in isolation. We present RankGraph-2, a framework deployed at Meta that co-designs all three lifecycle stages for similarity-based retrieval (U2U2I and U2I2I), where each stage's requirements shape the others. Serving requires a co-learned cluster index to avoid expensive online KNN -- this pushes index co-training into the training objective. Training benefits from the observation that similarity-based retrieval tolerates pre-computed neighborhoods, eliminating online graph infrastructure -- this requires construction to produce self-contained data. Construction must also support hour-level refresh for item coverage. Acting on these cascading requirements, RankGraph-2 reduces hundreds of trillions of edges to hundreds of billions via subsampling with popularity bias correction, pre-computes multi-hop neighborhoods via personalized PageRank, and co-learns a residual-quantization cluster index that reduces serving computational cost by 83%. This lifecycle co-design enables a simple architecture to achieve 3.8 x higher recall than a GAT + Deep Graph Infomax model on a bipartite graph and 2.1 x higher than PyTorch-BigGraph on item retrieval. RankGraph-2 delivers up to +0.96% CTR and +2.75% CVR, and has powered 20+ retrieval launches across major surfaces.
Code as Agent Harness
May 18, 2026Recent large language models (LLMs) have demonstrated strong capabilities in understanding and generating code, from competitive programming to repository-level software engineering. In emerging agentic systems, code is no longer only a target output. It increasingly serves as an operational substrate for agent reasoning, acting, environment modeling, and execution-based verification. We frame this shift through the lens of agent harnesses and introduce code as agent harness: a unified view that centers code as the basis for agent infrastructure. To systematically study this perspective, we organize the survey around three connected layers. First, we study the harness interface, where code connects agents to reasoning, action, and environment modeling. Second, we examine harness mechanisms: planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive. Third, we discuss scaling the harness from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification. Across these layers, we summarize representative methods and practical applications of code as agent harness, spanning coding assistants, GUI/OS automation, embodied agents, scientific discovery, personalization and recommendation, DevOps, and enterprise workflows. We further outline open challenges for harness engineering, including evaluation beyond final task success, verification under incomplete feedback, regression-free harness improvement, consistent shared state across multiple agents, human oversight for safety-critical actions, and extensions to multimodal environments. By centering code as the harness of agentic AI, this survey provides a unified roadmap toward executable, verifiable, and stateful AI agent systems.
Contextualized Word Embeddings Encode Aspects of Human-Like Word Sense Knowledge
Oct 25, 2020
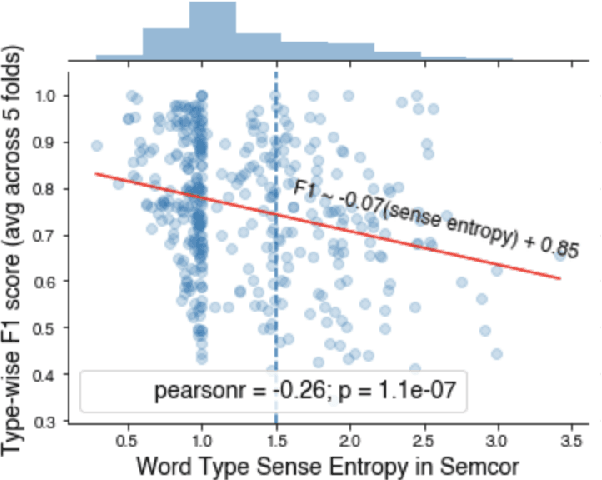
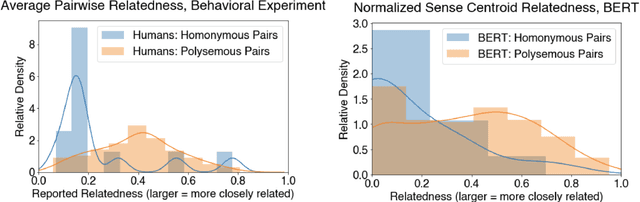

Understanding context-dependent variation in word meanings is a key aspect of human language comprehension supported by the lexicon. Lexicographic resources (e.g., WordNet) capture only some of this context-dependent variation; for example, they often do not encode how closely senses, or discretized word meanings, are related to one another. Our work investigates whether recent advances in NLP, specifically contextualized word embeddings, capture human-like distinctions between English word senses, such as polysemy and homonymy. We collect data from a behavioral, web-based experiment, in which participants provide judgments of the relatedness of multiple WordNet senses of a word in a two-dimensional spatial arrangement task. We find that participants' judgments of the relatedness between senses are correlated with distances between senses in the BERT embedding space. Homonymous senses (e.g., bat as mammal vs. bat as sports equipment) are reliably more distant from one another in the embedding space than polysemous ones (e.g., chicken as animal vs. chicken as meat). Our findings point towards the potential utility of continuous-space representations of sense meanings.