 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multiagent Reinforcement Learning with Collective Influence Estimation
Jan 13, 2026Multiagent reinforcement learning (MARL) has attracted considerable attention due to its potential in addressing complex cooperative tasks. However, existing MARL approaches often rely on frequent exchanges of action or state information among agents to achieve effective coordination, which is difficult to satisfy in practical robotic systems. A common solution is to introduce estimator networks to model the behaviors of other agents and predict their actions; nevertheless, such designs cause the size and computational cost of the estimator networks to grow rapidly with the number of agents, thereby limiting scalability in large-scale systems. To address these challenges, this paper proposes a multiagent learning framework augmented with a Collective Influence Estimation Network (CIEN). By explicitly modeling the collective influence of other agents on the task object, each agent can infer critical interaction information solely from its local observations and the task object's states, enabling efficient collaboration without explicit action information exchange. The proposed framework effectively avoids network expansion as the team size increases; moreover, new agents can be incorporated without modifying the network structures of existing agents, demonstrating strong scalability. Experimental results on multiagent cooperative tasks based on the Soft Actor-Critic (SAC) algorithm show that the proposed method achieves stable and efficient coordination under communication-limited environments. Furthermore, policies trained with collective influence modeling are deployed on a real robotic platform, where experimental results indicate significantly improved robustness and deployment feasibility, along with reduced dependence on communication infrastructure.
Multi-Party Dual Learning
Apr 14, 2021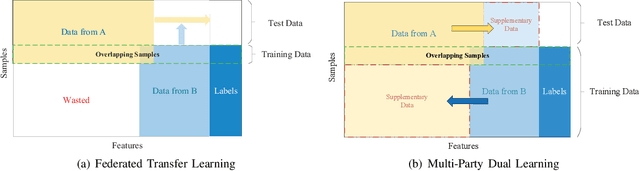
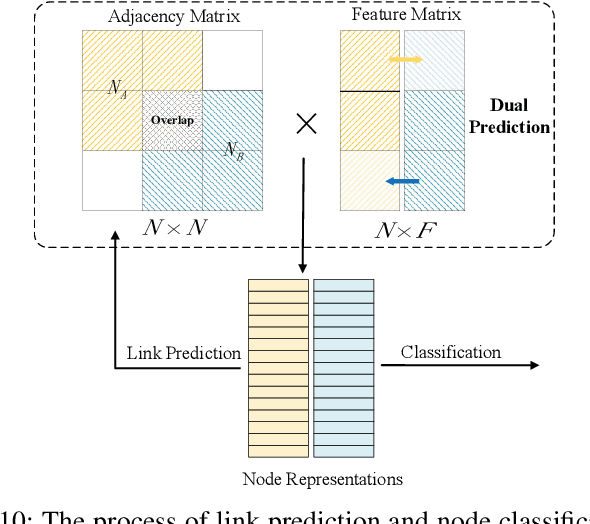
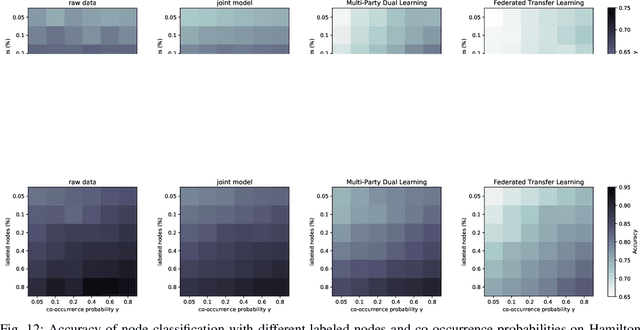
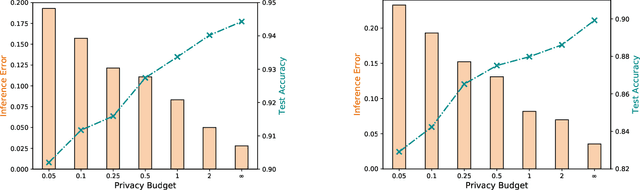
The performance of machine learning algorithms heavily relies on the availability of a large amount of training data. However, in reality, data usually reside in distributed parties such as different institutions and may not be directly gathered and integrated due to various data policy constraints. As a result, some parties may suffer from insufficient data available for training machine learning models. In this paper, we propose a multi-party dual learning (MPDL) framework to alleviate the problem of limited data with poor quality in an isolated party. Since the knowledge sharing processes for multiple parties always emerge in dual forms, we show that dual learning is naturally suitable to handle the challenge of missing data, and explicitly exploits the probabilistic correlation and structural relationship between dual tasks to regularize the training process. We introduce a feature-oriented differential privacy with mathematical proof, in order to avoid possible privacy leakage of raw features in the dual inference process. The approach requires minimal modifications to the existing multi-party learning structure, and each party can build flexible and powerful models separately, whose accuracy is no less than non-distributed self-learning approaches. The MPDL framework achieves significant improvement compared with state-of-the-art multi-party learning methods, as we demonstrated through simulations on real-world datasets.