 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnswering Ambiguous Questions via Iterative Prompting
Jul 08, 2023

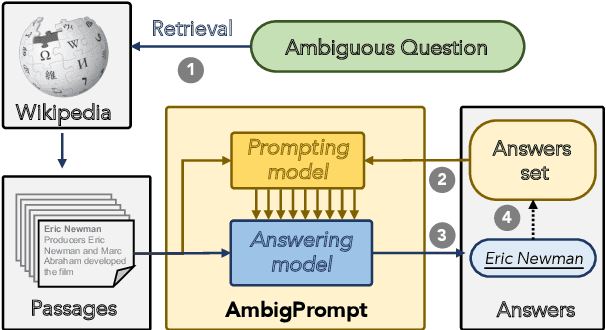

In open-domain question answering, due to the ambiguity of questions, multiple plausible answers may exist. To provide feasible answers to an ambiguous question, one approach is to directly predict all valid answers, but this can struggle with balancing relevance and diversity. An alternative is to gather candidate answers and aggregate them, but this method can be computationally costly and may neglect dependencies among answers. In this paper, we present AmbigPrompt to address the imperfections of existing approaches to answering ambiguous questions. Specifically, we integrate an answering model with a prompting model in an iterative manner. The prompting model adaptively tracks the reading process and progressively triggers the answering model to compose distinct and relevant answers. Additionally, we develop a task-specific post-pretraining approach for both the answering model and the prompting model, which greatly improves the performance of our framework. Empirical studies on two commonly-used open benchmarks show that AmbigPrompt achieves state-of-the-art or competitive results while using less memory and having a lower inference latency than competing approaches. Additionally, AmbigPrompt also performs well in low-resource settings. The code are available at: https://github.com/sunnweiwei/AmbigPrompt.
RecFusion: A Binomial Diffusion Process for 1D Data for Recommendation
Jun 19, 2023



In this paper we propose RecFusion, which comprise a set of diffusion models for recommendation. Unlike image data which contain spatial correlations, a user-item interaction matrix, commonly utilized in recommendation, lacks spatial relationships between users and items. We formulate diffusion on a 1D vector and propose binomial diffusion, which explicitly models binary user-item interactions with a Bernoulli process. We show that RecFusion approaches the performance of complex VAE baselines on the core recommendation setting (top-n recommendation for binary non-sequential feedback) and the most common datasets (MovieLens and Netflix). Our proposed diffusion models that are specialized for 1D and/or binary setups have implications beyond recommendation systems, such as in the medical domain with MRI and CT scans.
Distributional Reinforcement Learning with Dual Expectile-Quantile Regression
May 26, 2023



Successful applications of distributional reinforcement learning with quantile regression prompt a natural question: can we use other statistics to represent the distribution of returns? In particular, expectile regression is known to be more efficient than quantile regression for approximating distributions, especially on extreme values, and by providing a straightforward estimator of the mean it is a natural candidate for reinforcement learning. Prior work has answered this question positively in the case of expectiles, with the major caveat that expensive computations must be performed to ensure convergence. In this work, we propose a dual expectile-quantile approach which solves the shortcomings of previous work while leveraging the complementary properties of expectiles and quantiles. Our method outperforms both quantile-based and expectile-based baselines on the MuJoCo continuous control benchmark.
MultiTabQA: Generating Tabular Answers for Multi-Table Question Answering
May 24, 2023



Recent advances in tabular question answering (QA) with large language models are constrained in their coverage and only answer questions over a single table. However, real-world queries are complex in nature, often over multiple tables in a relational database or web page. Single table questions do not involve common table operations such as set operations, Cartesian products (joins), or nested queries. Furthermore, multi-table operations often result in a tabular output, which necessitates table generation capabilities of tabular QA models. To fill this gap, we propose a new task of answering questions over multiple tables. Our model, MultiTabQA, not only answers questions over multiple tables, but also generalizes to generate tabular answers. To enable effective training, we build a pre-training dataset comprising of 132,645 SQL queries and tabular answers. Further, we evaluate the generated tables by introducing table-specific metrics of varying strictness assessing various levels of granularity of the table structure. MultiTabQA outperforms state-of-the-art single table QA models adapted to a multi-table QA setting by finetuning on three datasets: Spider, Atis and GeoQuery.
Query Performance Prediction: From Ad-hoc to Conversational Search
May 18, 2023Query performance prediction (QPP) is a core task in information retrieval. The QPP task is to predict the retrieval quality of a search system for a query without relevance judgments. Research has shown the effectiveness and usefulness of QPP for ad-hoc search. Recent years have witnessed considerable progress in conversational search (CS). Effective QPP could help a CS system to decide an appropriate action to be taken at the next turn. Despite its potential, QPP for CS has been little studied. We address this research gap by reproducing and studying the effectiveness of existing QPP methods in the context of CS. While the task of passage retrieval remains the same in the two settings, a user query in CS depends on the conversational history, introducing novel QPP challenges. In particular, we seek to explore to what extent findings from QPP methods for ad-hoc search generalize to three CS settings: (i) estimating the retrieval quality of different query rewriting-based retrieval methods, (ii) estimating the retrieval quality of a conversational dense retrieval method, and (iii) estimating the retrieval quality for top ranks vs. deeper-ranked lists. Our findings can be summarized as follows: (i) supervised QPP methods distinctly outperform unsupervised counterparts only when a large-scale training set is available; (ii) point-wise supervised QPP methods outperform their list-wise counterparts in most cases; and (iii) retrieval score-based unsupervised QPP methods show high effectiveness in assessing the conversational dense retrieval method, ConvDR.
Iteratively Learning Representations for Unseen Entities with Inter-Rule Correlations
May 17, 2023Recent work on knowledge graph completion (KGC) focused on learning embeddings of entities and relations in knowledge graphs. These embedding methods require that all test entities are observed at training time, resulting in a time-consuming retraining process for out-of-knowledge-graph (OOKG) entities. To address this issue, current inductive knowledge embedding methods employ graph neural networks (GNNs) to represent unseen entities by aggregating information of known neighbors. They face three important challenges: (i) data sparsity, (ii) the presence of complex patterns in knowledge graphs (e.g., inter-rule correlations), and (iii) the presence of interactions among rule mining, rule inference, and embedding. In this paper, we propose a virtual neighbor network with inter-rule correlations (VNC) that consists of three stages: (i) rule mining, (ii) rule inference, and (iii) embedding. In the rule mining process, to identify complex patterns in knowledge graphs, both logic rules and inter-rule correlations are extracted from knowledge graphs based on operations over relation embeddings. To reduce data sparsity, virtual neighbors for OOKG entities are predicted and assigned soft labels by optimizing a rule-constrained problem. We also devise an iterative framework to capture the underlying relations between rule learning and embedding learning. In our experiments, results on both link prediction and triple classification tasks show that the proposed VNC framework achieves state-of-the-art performance on four widely-used knowledge graphs. Further analysis reveals that VNC is robust to the proportion of unseen entities and effectively mitigates data sparsity.
Improving Implicit Feedback-Based Recommendation through Multi-Behavior Alignment
May 09, 2023



Recommender systems that learn from implicit feedback often use large volumes of a single type of implicit user feedback, such as clicks, to enhance the prediction of sparse target behavior such as purchases. Using multiple types of implicit user feedback for such target behavior prediction purposes is still an open question. Existing studies that attempted to learn from multiple types of user behavior often fail to: (i) learn universal and accurate user preferences from different behavioral data distributions, and (ii) overcome the noise and bias in observed implicit user feedback. To address the above problems, we propose multi-behavior alignment (MBA), a novel recommendation framework that learns from implicit feedback by using multiple types of behavioral data. We conjecture that multiple types of behavior from the same user (e.g., clicks and purchases) should reflect similar preferences of that user. To this end, we regard the underlying universal user preferences as a latent variable. The variable is inferred by maximizing the likelihood of multiple observed behavioral data distributions and, at the same time, minimizing the Kullback-Leibler divergence (KL-divergence) between user models learned from auxiliary behavior (such as clicks or views) and the target behavior separately. MBA infers universal user preferences from multi-behavior data and performs data denoising to enable effective knowledge transfer. We conduct experiments on three datasets, including a dataset collected from an operational e-commerce platform. Empirical results demonstrate the effectiveness of our proposed method in utilizing multiple types of behavioral data to enhance the prediction of the target behavior.
On the Impact of Outlier Bias on User Clicks
May 01, 2023User interaction data is an important source of supervision in counterfactual learning to rank (CLTR). Such data suffers from presentation bias. Much work in unbiased learning to rank (ULTR) focuses on position bias, i.e., items at higher ranks are more likely to be examined and clicked. Inter-item dependencies also influence examination probabilities, with outlier items in a ranking as an important example. Outliers are defined as items that observably deviate from the rest and therefore stand out in the ranking. In this paper, we identify and introduce the bias brought about by outlier items: users tend to click more on outlier items and their close neighbors. To this end, we first conduct a controlled experiment to study the effect of outliers on user clicks. Next, to examine whether the findings from our controlled experiment generalize to naturalistic situations, we explore real-world click logs from an e-commerce platform. We show that, in both scenarios, users tend to click significantly more on outlier items than on non-outlier items in the same rankings. We show that this tendency holds for all positions, i.e., for any specific position, an item receives more interactions when presented as an outlier as opposed to a non-outlier item. We conclude from our analysis that the effect of outliers on clicks is a type of bias that should be addressed in ULTR. We therefore propose an outlier-aware click model that accounts for both outlier and position bias, called outlier-aware position-based model ( OPBM). We estimate click propensities based on OPBM ; through extensive experiments performed on both real-world e-commerce data and semi-synthetic data, we verify the effectiveness of our outlier-aware click model. Our results show the superiority of OPBM against baselines in terms of ranking performance and true relevance estimation.
Topic-oriented Adversarial Attacks against Black-box Neural Ranking Models
Apr 28, 2023Neural ranking models (NRMs) have attracted considerable attention in information retrieval. Unfortunately, NRMs may inherit the adversarial vulnerabilities of general neural networks, which might be leveraged by black-hat search engine optimization practitioners. Recently, adversarial attacks against NRMs have been explored in the paired attack setting, generating an adversarial perturbation to a target document for a specific query. In this paper, we focus on a more general type of perturbation and introduce the topic-oriented adversarial ranking attack task against NRMs, which aims to find an imperceptible perturbation that can promote a target document in ranking for a group of queries with the same topic. We define both static and dynamic settings for the task and focus on decision-based black-box attacks. We propose a novel framework to improve topic-oriented attack performance based on a surrogate ranking model. The attack problem is formalized as a Markov decision process (MDP) and addressed using reinforcement learning. Specifically, a topic-oriented reward function guides the policy to find a successful adversarial example that can be promoted in rankings to as many queries as possible in a group. Experimental results demonstrate that the proposed framework can significantly outperform existing attack strategies, and we conclude by re-iterating that there exist potential risks for applying NRMs in the real world.
A Unified Generative Retriever for Knowledge-Intensive Language Tasks via Prompt Learning
Apr 28, 2023



Knowledge-intensive language tasks (KILTs) benefit from retrieving high-quality relevant contexts from large external knowledge corpora. Learning task-specific retrievers that return relevant contexts at an appropriate level of semantic granularity, such as a document retriever, passage retriever, sentence retriever, and entity retriever, may help to achieve better performance on the end-to-end task. But a task-specific retriever usually has poor generalization ability to new domains and tasks, and it may be costly to deploy a variety of specialised retrievers in practice. We propose a unified generative retriever (UGR) that combines task-specific effectiveness with robust performance over different retrieval tasks in KILTs. To achieve this goal, we make two major contributions: (i) To unify different retrieval tasks into a single generative form, we introduce an n-gram-based identifier for relevant contexts at different levels of granularity in KILTs. And (ii) to address different retrieval tasks with a single model, we employ a prompt learning strategy and investigate three methods to design prompt tokens for each task. In this way, the proposed UGR model can not only share common knowledge across tasks for better generalization, but also perform different retrieval tasks effectively by distinguishing task-specific characteristics. We train UGR on a heterogeneous set of retrieval corpora with well-designed prompts in a supervised and multi-task fashion. Experimental results on the KILT benchmark demonstrate the effectiveness of UGR on in-domain datasets, out-of-domain datasets, and unseen tasks.