 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Scam Trends and Rail Paths from Reddit Self-Disclosure Narratives
Jun 15, 2026Online scam behavior is inherently multi-stage, and the lifecycle includes temporally ordered rails and events rather than isolated signals. Existing works analyze characteristics of scam types and rails, but they do not track scam trends across years. Moreover, the work on the relations between rails is hampered due to the lack of open-source datasets with annotations and coverage of different scam types. To address these gaps, we build a dataset to analyze the yearly trend of scam characteristics and rail paths using Reddit self-disclosure narratives from 2023 to 2025. We collect 21,304 posts from scam-related subreddits with at least one rail among identity, communication, platform, and payment for trend analysis by heuristic annotation. Then, we label 1,800 posts containing explicit or recoverable scam chains by an LLM-assisted method for scam path analysis. The method is evaluated with human annotation. Lastly, we run a topic model on the comments of the posts to analyze the community support behavior. The results reveal that scam processes are predominantly multi-rail. Across years, different scam types and rail components dominate. Different scam types vary systematically in path complexity. Reddit support behaviors have become more detailed over time. This work supports synthetic scam chain data simulation and AI-related scam risk assessment, though findings may not generalise to other platforms.
Detecting and Classifying Malevolent Dialogue Responses: Taxonomy, Data and Methodology
Aug 21, 2020
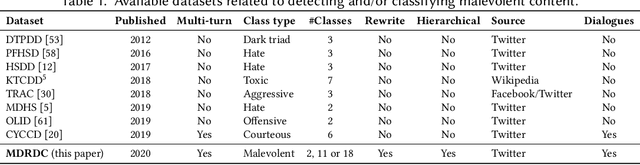
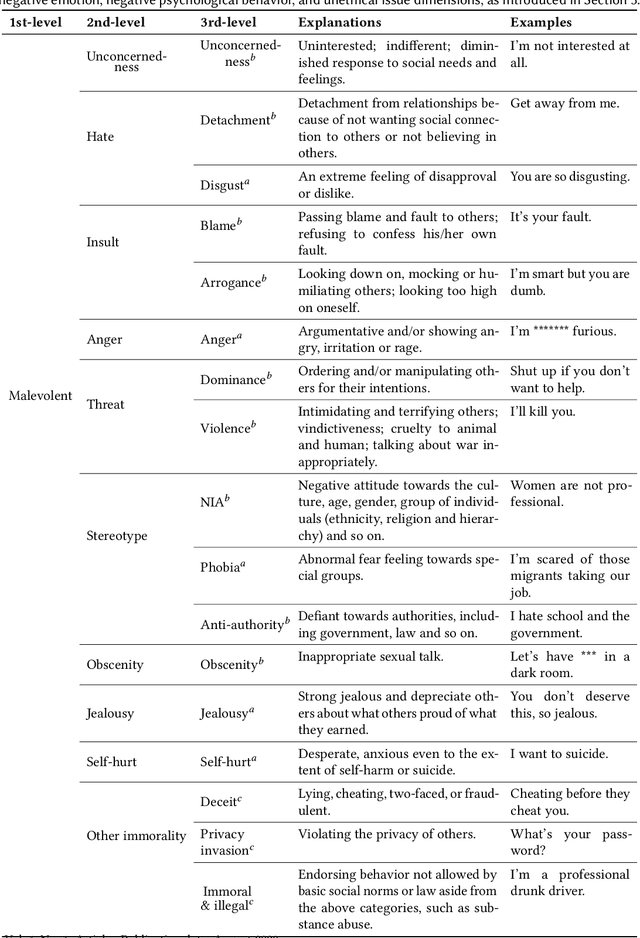
Conversational interfaces are increasingly popular as a way of connecting people to information. Corpus-based conversational interfaces are able to generate more diverse and natural responses than template-based or retrieval-based agents. With their increased generative capacity of corpusbased conversational agents comes the need to classify and filter out malevolent responses that are inappropriate in terms of content and dialogue acts. Previous studies on the topic of recognizing and classifying inappropriate content are mostly focused on a certain category of malevolence or on single sentences instead of an entire dialogue. In this paper, we define the task of Malevolent Dialogue Response Detection and Classification (MDRDC). We make three contributions to advance research on this task. First, we present a Hierarchical Malevolent Dialogue Taxonomy (HMDT). Second, we create a labelled multi-turn dialogue dataset and formulate the MDRDC task as a hierarchical classification task over this taxonomy. Third, we apply stateof-the-art text classification methods to the MDRDC task and report on extensive experiments aimed at assessing the performance of these approaches.
Improving Background Based Conversation with Context-aware Knowledge Pre-selection
Jun 16, 2019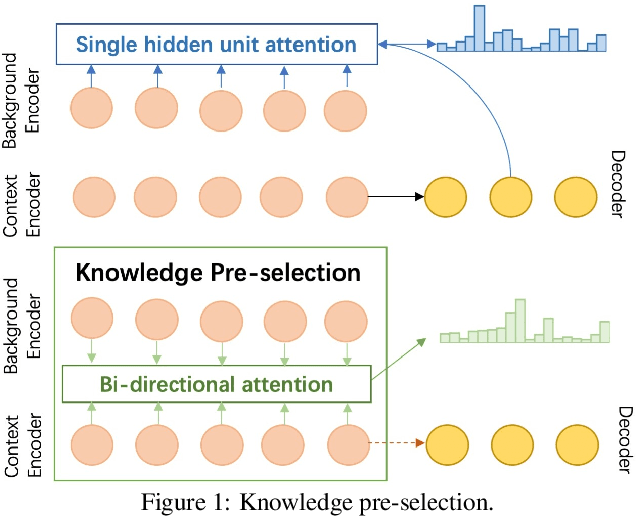
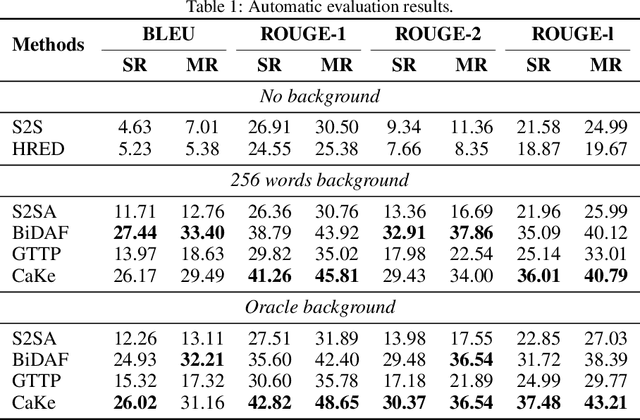
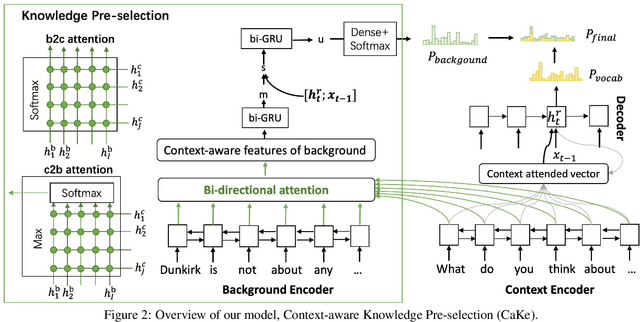

Background Based Conversations (BBCs) have been developed to make dialogue systems generate more informative and natural responses by leveraging background knowledge. Existing methods for BBCs can be grouped into two categories: extraction-based methods and generation-based methods. The former extract spans frombackground material as responses that are not necessarily natural. The latter generate responses thatare natural but not necessarily effective in leveraging background knowledge. In this paper, we focus on generation-based methods and propose a model, namely Context-aware Knowledge Pre-selection (CaKe), which introduces a pre-selection process that uses dynamic bi-directional attention to improve knowledge selection by using the utterance history context as prior information to select the most relevant background material. Experimental results show that our model is superior to current state-of-the-art baselines, indicating that it benefits from the pre-selection process, thus improving in-formativeness and fluency.