 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Supervised Learning and Reinforcement Learning in Task-Oriented Dialogue Systems
Paper and Code
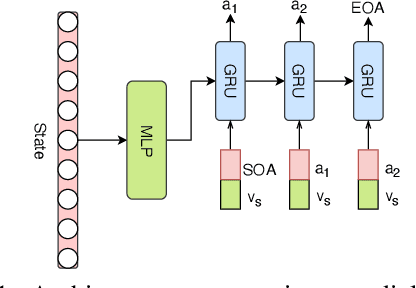
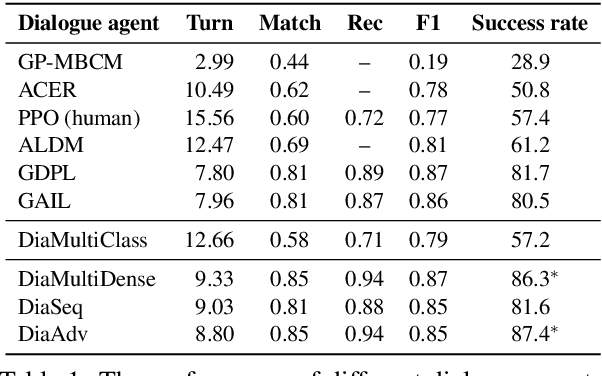
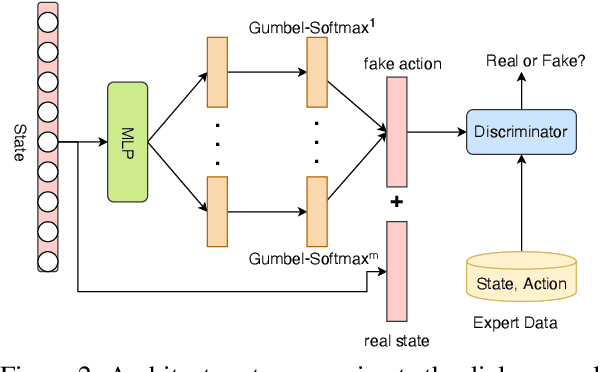

Dialogue policy learning for task-oriented dialogue systems has enjoyed great progress recently mostly through employing reinforcement learning methods. However, these approaches have become very sophisticated. It is time to re-evaluate it. Are we really making progress developing dialogue agents only based on reinforcement learning? We demonstrate how (1)~traditional supervised learning together with (2)~a simulator-free adversarial learning method can be used to achieve performance comparable to state-of-the-art RL-based methods. First, we introduce a simple dialogue action decoder to predict the appropriate actions. Then, the traditional multi-label classification solution for dialogue policy learning is extended by adding dense layers to improve the dialogue agent performance. Finally, we employ the Gumbel-Softmax estimator to alternatively train the dialogue agent and the dialogue reward model without using reinforcement learning. Based on our extensive experimentation, we can conclude the proposed methods can achieve more stable and higher performance with fewer efforts, such as the domain knowledge required to design a user simulator and the intractable parameter tuning in reinforcement learning. Our main goal is not to beat reinforcement learning with supervised learning, but to demonstrate the value of rethinking the role of reinforcement learning and supervised learning in optimizing task-oriented dialogue systems.