 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated vision-based assistance tools in bronchoscopy: stenosis severity estimation
May 08, 2025Purpose: Subglottic stenosis refers to the narrowing of the subglottis, the airway between the vocal cords and the trachea. Its severity is typically evaluated by estimating the percentage of obstructed airway. This estimation can be obtained from CT data or through visual inspection by experts exploring the region. However, visual inspections are inherently subjective, leading to less consistent and robust diagnoses. No public methods or datasets are currently available for automated evaluation of this condition from bronchoscopy video. Methods: We propose a pipeline for automated subglottic stenosis severity estimation during the bronchoscopy exploration, without requiring the physician to traverse the stenosed region. Our approach exploits the physical effect of illumination decline in endoscopy to segment and track the lumen and obtain a 3D model of the airway. This 3D model is obtained from a single frame and is used to measure the airway narrowing. Results: Our pipeline is the first to enable automated and robust subglottic stenosis severity measurement using bronchoscopy images. The results show consistency with ground-truth estimations from CT scans and expert estimations, and reliable repeatability across multiple estimations on the same patient. Our evaluation is performed on our new Subglottic Stenosis Dataset of real bronchoscopy procedures data. Conclusion: We demonstrate how to automate evaluation of subglottic stenosis severity using only bronchoscopy. Our approach can assist with and shorten diagnosis and monitoring procedures, with automated and repeatable estimations and less exploration time, and save radiation exposure to patients as no CT is required. Additionally, we release the first public benchmark for subglottic stenosis severity assessment.
Sim2Real in endoscopy segmentation with a novel structure aware image translation
May 05, 2025Automatic segmentation of anatomical landmarks in endoscopic images can provide assistance to doctors and surgeons for diagnosis, treatments or medical training. However, obtaining the annotations required to train commonly used supervised learning methods is a tedious and difficult task, in particular for real images. While ground truth annotations are easier to obtain for synthetic data, models trained on such data often do not generalize well to real data. Generative approaches can add realistic texture to it, but face difficulties to maintain the structure of the original scene. The main contribution in this work is a novel image translation model that adds realistic texture to simulated endoscopic images while keeping the key scene layout information. Our approach produces realistic images in different endoscopy scenarios. We demonstrate these images can effectively be used to successfully train a model for a challenging end task without any real labeled data. In particular, we demonstrate our approach for the task of fold segmentation in colonoscopy images. Folds are key anatomical landmarks that can occlude parts of the colon mucosa and possible polyps. Our approach generates realistic images maintaining the shape and location of the original folds, after the image-style-translation, better than existing methods. We run experiments both on a novel simulated dataset for fold segmentation, and real data from the EndoMapper (EM) dataset. All our new generated data and new EM metadata is being released to facilitate further research, as no public benchmark is currently available for the task of fold segmentation.
EndoMapper dataset of complete calibrated endoscopy procedures
Apr 29, 2022
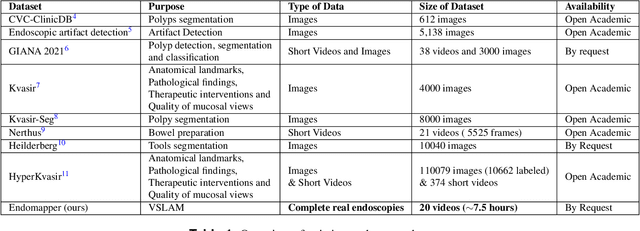


Computer-assisted systems are becoming broadly used in medicine. In endoscopy, most research focuses on automatic detection of polyps or other pathologies, but localization and navigation of the endoscope is completely performed manually by physicians. To broaden this research and bring spatial Artificial Intelligence to endoscopies, data from complete procedures are needed. This data will be used to build a 3D mapping and localization systems that can perform special task like, for example, detect blind zones during exploration, provide automatic polyp measurements, guide doctors to a polyp found in a previous exploration and retrieve previous images of the same area aligning them for easy comparison. These systems will provide an improvement in the quality and precision of the procedures while lowering the burden on the physicians. This paper introduces the Endomapper dataset, the first collection of complete endoscopy sequences acquired during regular medical practice, including slow and careful screening explorations, making secondary use of medical data. Its original purpose is to facilitate the development and evaluation of VSLAM (Visual Simultaneous Localization and Mapping) methods in real endoscopy data. The first release of the dataset is composed of 59 sequences with more than 15 hours of video. It is also the first endoscopic dataset that includes both the computed geometric and photometric endoscope calibration with the original calibration videos. Meta-data and annotations associated to the dataset varies from anatomical landmark and description of the procedure labeling, tools segmentation masks, COLMAP 3D reconstructions, simulated sequences with groundtruth and meta-data related to special cases, such as sequences from the same patient. This information will improve the research in endoscopic VSLAM, as well as other research lines, and create new research lines.