 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Guiding Language Model Reasoning with Planning Tokens
Oct 09, 2023



Large language models (LLMs) have recently attracted considerable interest for their ability to perform complex reasoning tasks, such as chain-of-thought reasoning. However, most of the existing approaches to enhance this ability rely heavily on data-driven methods, while neglecting the structural aspects of the model's reasoning capacity. We find that while LLMs can manage individual reasoning steps well, they struggle with maintaining consistency across an entire reasoning chain. To solve this, we introduce 'planning tokens' at the start of each reasoning step, serving as a guide for the model. These token embeddings are then fine-tuned along with the rest of the model parameters. Our approach requires a negligible increase in trainable parameters (just 0.001%) and can be applied through either full fine-tuning or a more parameter-efficient scheme. We demonstrate our method's effectiveness by applying it to three different LLMs, showing notable accuracy improvements across three math word problem datasets w.r.t. plain chain-of-thought fine-tuning baselines.
Guiding The Last Layer in Federated Learning with Pre-Trained Models
Jun 06, 2023



Federated Learning (FL) is an emerging paradigm that allows a model to be trained across a number of participants without sharing data. Recent works have begun to consider the effects of using pre-trained models as an initialization point for existing FL algorithms; however, these approaches ignore the vast body of efficient transfer learning literature from the centralized learning setting. Here we revisit the problem of FL from a pre-trained model considered in prior work and expand it to a set of computer vision transfer learning problems. We first observe that simply fitting a linear classification head can be efficient and effective in many cases. We then show that in the FL setting, fitting a classifier using the Nearest Class Means (NCM) can be done exactly and orders of magnitude more efficiently than existing proposals, while obtaining strong performance. Finally, we demonstrate that using a two-phase approach of obtaining the classifier and then fine-tuning the model can yield rapid convergence and improved generalization in the federated setting. We demonstrate the potential our method has to reduce communication and compute costs while achieving better model performance.
Re-Weighted Softmax Cross-Entropy to Control Forgetting in Federated Learning
Apr 11, 2023In Federated Learning, a global model is learned by aggregating model updates computed at a set of independent client nodes, to reduce communication costs multiple gradient steps are performed at each node prior to aggregation. A key challenge in this setting is data heterogeneity across clients resulting in differing local objectives which can lead clients to overly minimize their own local objective, diverging from the global solution. We demonstrate that individual client models experience a catastrophic forgetting with respect to data from other clients and propose an efficient approach that modifies the cross-entropy objective on a per-client basis by re-weighting the softmax logits prior to computing the loss. This approach shields classes outside a client's label set from abrupt representation change and we empirically demonstrate it can alleviate client forgetting and provide consistent improvements to standard federated learning algorithms. Our method is particularly beneficial under the most challenging federated learning settings where data heterogeneity is high and client participation in each round is low.
Building a Subspace of Policies for Scalable Continual Learning
Nov 18, 2022The ability to continuously acquire new knowledge and skills is crucial for autonomous agents. Existing methods are typically based on either fixed-size models that struggle to learn a large number of diverse behaviors, or growing-size models that scale poorly with the number of tasks. In this work, we aim to strike a better balance between an agent's size and performance by designing a method that grows adaptively depending on the task sequence. We introduce Continual Subspace of Policies (CSP), a new approach that incrementally builds a subspace of policies for training a reinforcement learning agent on a sequence of tasks. The subspace's high expressivity allows CSP to perform well for many different tasks while growing sublinearly with the number of tasks. Our method does not suffer from forgetting and displays positive transfer to new tasks. CSP outperforms a number of popular baselines on a wide range of scenarios from two challenging domains, Brax (locomotion) and Continual World (manipulation).
Multi-Head Adapter Routing for Data-Efficient Fine-Tuning
Nov 07, 2022Parameter-efficient fine-tuning (PEFT) methods can adapt large language models to downstream tasks by training a small amount of newly added parameters. In multi-task settings, PEFT adapters typically train on each task independently, inhibiting transfer across tasks, or on the concatenation of all tasks, which can lead to negative interference. To address this, Polytropon (Ponti et al.) jointly learns an inventory of PEFT adapters and a routing function to share variable-size sets of adapters across tasks. Subsequently, adapters can be re-combined and fine-tuned on novel tasks even with limited data. In this paper, we investigate to what extent the ability to control which adapters are active for each task leads to sample-efficient generalization. Thus, we propose less expressive variants where we perform weighted averaging of the adapters before few-shot adaptation (Poly-mu) instead of learning a routing function. Moreover, we introduce more expressive variants where finer-grained task-adapter allocation is learned through a multi-head routing function (Poly-S). We test these variants on three separate benchmarks for multi-task learning. We find that Poly-S achieves gains on all three (up to 5.3 points on average) over strong baselines, while incurring a negligible additional cost in parameter count. In particular, we find that instruction tuning, where models are fully fine-tuned on natural language instructions for each task, is inferior to modular methods such as Polytropon and our proposed variants.
New Insights on Reducing Abrupt Representation Change in Online Continual Learning
Mar 08, 2022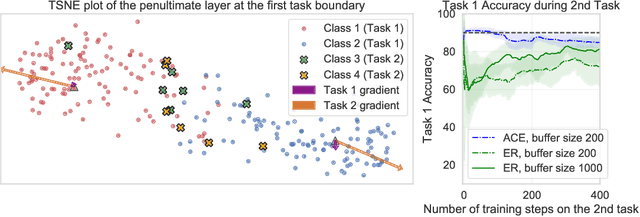
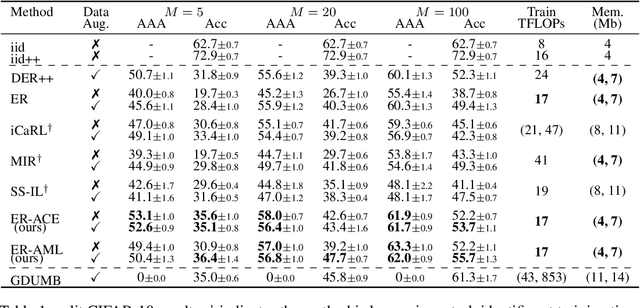
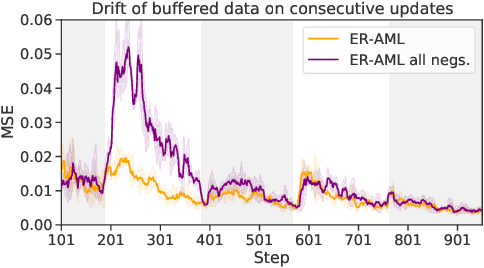
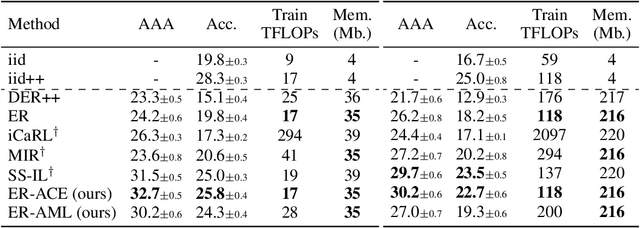
In the online continual learning paradigm, agents must learn from a changing distribution while respecting memory and compute constraints. Experience Replay (ER), where a small subset of past data is stored and replayed alongside new data, has emerged as a simple and effective learning strategy. In this work, we focus on the change in representations of observed data that arises when previously unobserved classes appear in the incoming data stream, and new classes must be distinguished from previous ones. We shed new light on this question by showing that applying ER causes the newly added classes' representations to overlap significantly with the previous classes, leading to highly disruptive parameter updates. Based on this empirical analysis, we propose a new method which mitigates this issue by shielding the learned representations from drastic adaptation to accommodate new classes. We show that using an asymmetric update rule pushes new classes to adapt to the older ones (rather than the reverse), which is more effective especially at task boundaries, where much of the forgetting typically occurs. Empirical results show significant gains over strong baselines on standard continual learning benchmarks
On Anytime Learning at Macroscale
Jun 17, 2021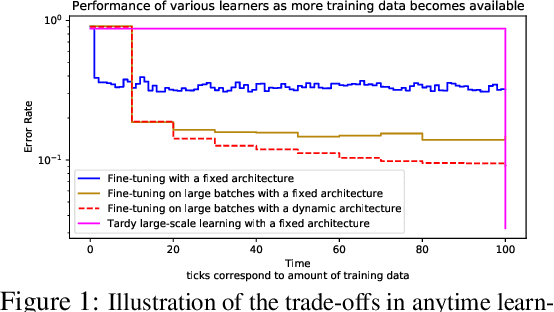
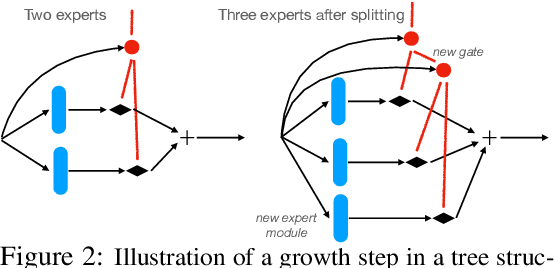
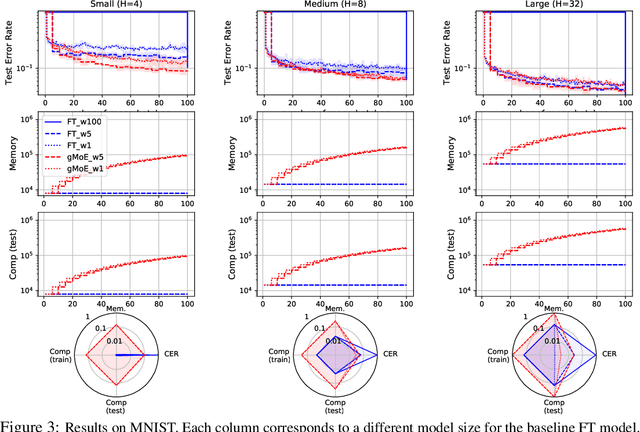
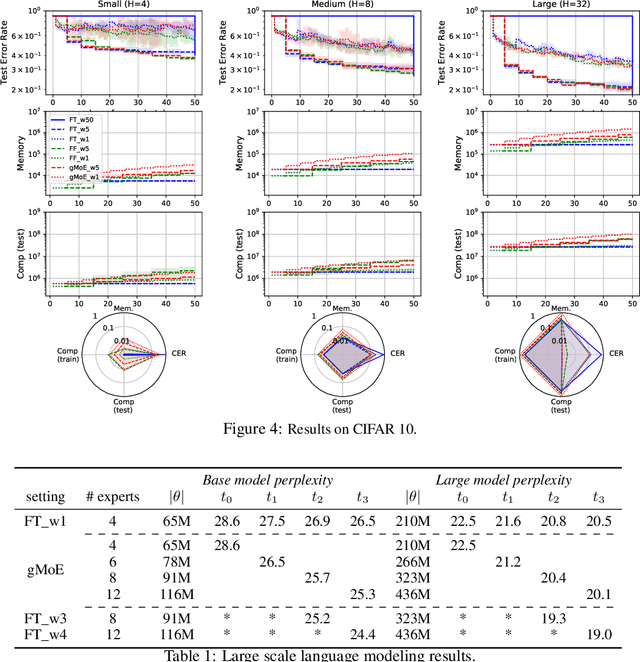
Classical machine learning frameworks assume access to a possibly large dataset in order to train a predictive model. In many practical applications however, data does not arrive all at once, but in batches over time. This creates a natural trade-off between accuracy of a model and time to obtain such a model. A greedy predictor could produce non-trivial predictions by immediately training on batches as soon as these become available but, it may also make sub-optimal use of future data. On the other hand, a tardy predictor could wait for a long time to aggregate several batches into a larger dataset, but ultimately deliver a much better performance. In this work, we consider such a streaming learning setting, which we dub {\em anytime learning at macroscale} (ALMA). It is an instance of anytime learning applied not at the level of a single chunk of data, but at the level of the entire sequence of large batches. We first formalize this learning setting, we then introduce metrics to assess how well learners perform on the given task for a given memory and compute budget, and finally we test several baseline approaches on standard benchmarks repurposed for anytime learning at macroscale. The general finding is that bigger models always generalize better. In particular, it is important to grow model capacity over time if the initial model is relatively small. Moreover, updating the model at an intermediate rate strikes the best trade off between accuracy and time to obtain a useful predictor.
SPeCiaL: Self-Supervised Pretraining for Continual Learning
Jun 16, 2021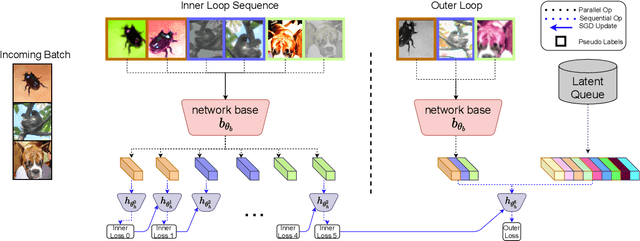
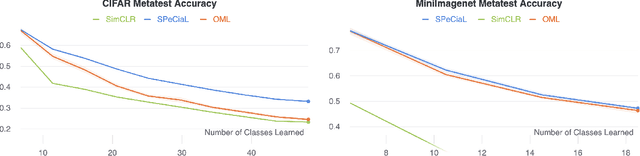
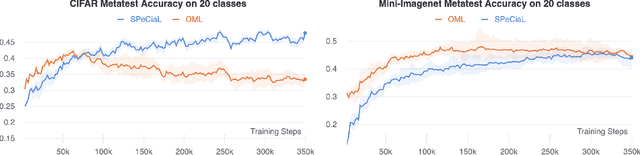
This paper presents SPeCiaL: a method for unsupervised pretraining of representations tailored for continual learning. Our approach devises a meta-learning objective that differentiates through a sequential learning process. Specifically, we train a linear model over the representations to match different augmented views of the same image together, each view presented sequentially. The linear model is then evaluated on both its ability to classify images it just saw, and also on images from previous iterations. This gives rise to representations that favor quick knowledge retention with minimal forgetting. We evaluate SPeCiaL in the Continual Few-Shot Learning setting, and show that it can match or outperform other supervised pretraining approaches.
Decoupled Greedy Learning of CNNs for Synchronous and Asynchronous Distributed Learning
Jun 11, 2021



A commonly cited inefficiency of neural network training using back-propagation is the update locking problem: each layer must wait for the signal to propagate through the full network before updating. Several alternatives that can alleviate this issue have been proposed. In this context, we consider a simple alternative based on minimal feedback, which we call Decoupled Greedy Learning (DGL). It is based on a classic greedy relaxation of the joint training objective, recently shown to be effective in the context of Convolutional Neural Networks (CNNs) on large-scale image classification. We consider an optimization of this objective that permits us to decouple the layer training, allowing for layers or modules in networks to be trained with a potentially linear parallelization. With the use of a replay buffer we show that this approach can be extended to asynchronous settings, where modules can operate and continue to update with possibly large communication delays. To address bandwidth and memory issues we propose an approach based on online vector quantization. This allows to drastically reduce the communication bandwidth between modules and required memory for replay buffers. We show theoretically and empirically that this approach converges and compare it to the sequential solvers. We demonstrate the effectiveness of DGL against alternative approaches on the CIFAR-10 dataset and on the large-scale ImageNet dataset.