 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSlot Machines: Discovering Winning Combinations of Random Weights in Neural Networks
Jan 16, 2021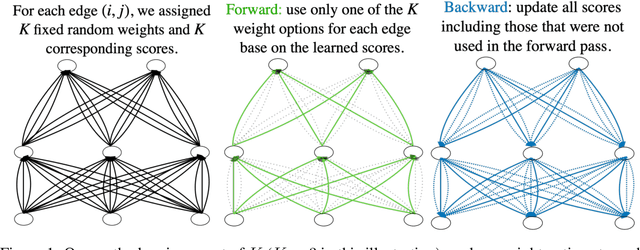
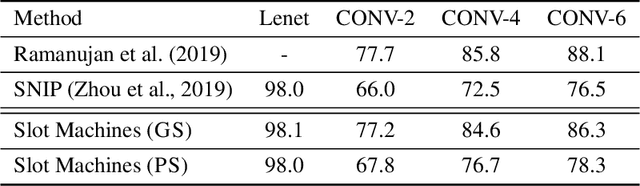

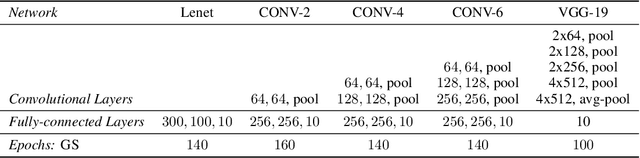
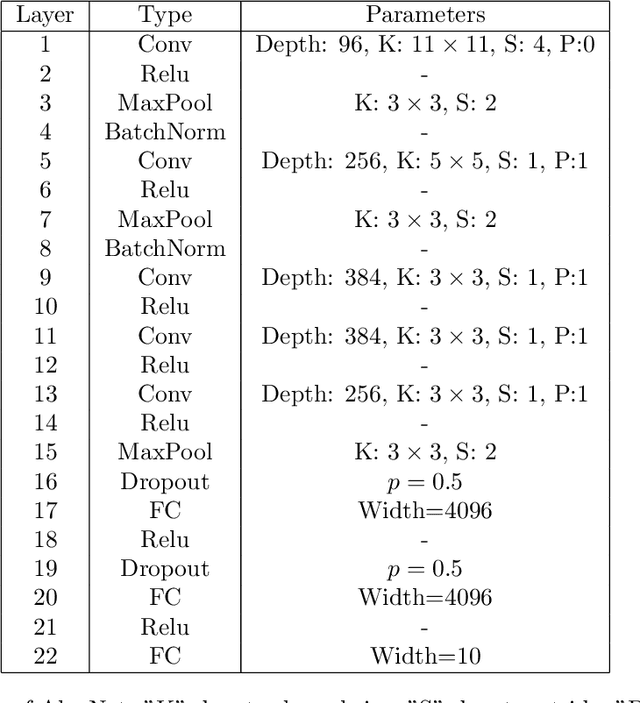
In contrast to traditional weight optimization in a continuous space, we demonstrate the existence of effective random networks whose weights are never updated. By selecting a weight among a fixed set of random values for each individual connection, our method uncovers combinations of random weights that match the performance of traditionally-trained networks of the same capacity. We refer to our networks as "slot machines" where each reel (connection) contains a fixed set of symbols (random values). Our backpropagation algorithm "spins" the reels to seek "winning" combinations, i.e., selections of random weight values that minimize the given loss. Quite surprisingly, we find that allocating just a few random values to each connection (e.g., 8 values per connection) yields highly competitive combinations despite being dramatically more constrained compared to traditionally learned weights. Moreover, finetuning these combinations often improves performance over the trained baselines. A randomly initialized VGG-19 with 8 values per connection contains a combination that achieves 90% test accuracy on CIFAR-10. Our method also achieves an impressive performance of 98.1% on MNIST for neural networks containing only random weights.
Resolution-Based Distillation for Efficient Histology Image Classification
Jan 11, 2021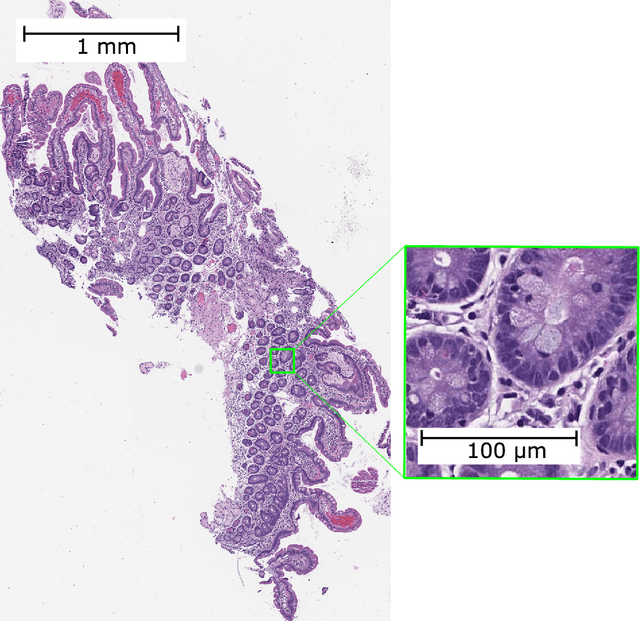
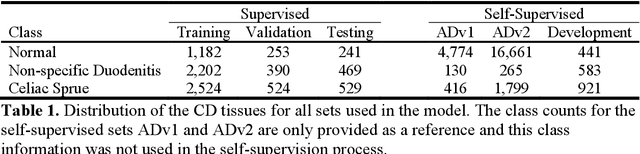
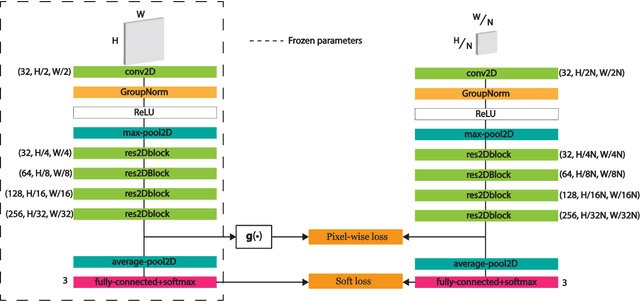
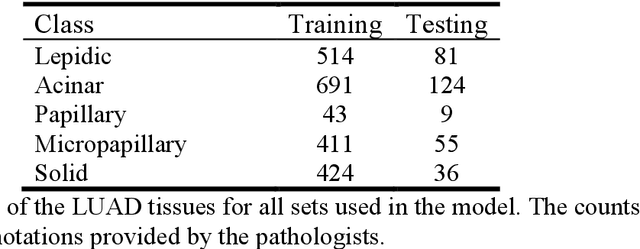
Developing deep learning models to analyze histology images has been computationally challenging, as the massive size of the images causes excessive strain on all parts of the computing pipeline. This paper proposes a novel deep learning-based methodology for improving the computational efficiency of histology image classification. The proposed approach is robust when used with images that have reduced input resolution and can be trained effectively with limited labeled data. Pre-trained on the original high-resolution (HR) images, our method uses knowledge distillation (KD) to transfer learned knowledge from a teacher model to a student model trained on the same images at a much lower resolution. To address the lack of large-scale labeled histology image datasets, we perform KD in a self-supervised manner. We evaluate our approach on two histology image datasets associated with celiac disease (CD) and lung adenocarcinoma (LUAD). Our results show that a combination of KD and self-supervision allows the student model to approach, and in some cases, surpass the classification accuracy of the teacher, while being much more efficient. Additionally, we observe an increase in student classification performance as the size of the unlabeled dataset increases, indicating that there is potential to scale further. For the CD data, our model outperforms the HR teacher model, while needing 4 times fewer computations. For the LUAD data, our student model results at 1.25x magnification are within 3% of the teacher model at 10x magnification, with a 64 times computational cost reduction. Moreover, our CD outcomes benefit from performance scaling with the use of more unlabeled data. For 0.625x magnification, using unlabeled data improves accuracy by 4% over the baseline. Thus, our method can improve the feasibility of deep learning solutions for digital pathology with standard computational hardware.
Learn like a Pathologist: Curriculum Learning by Annotator Agreement for Histopathology Image Classification
Sep 29, 2020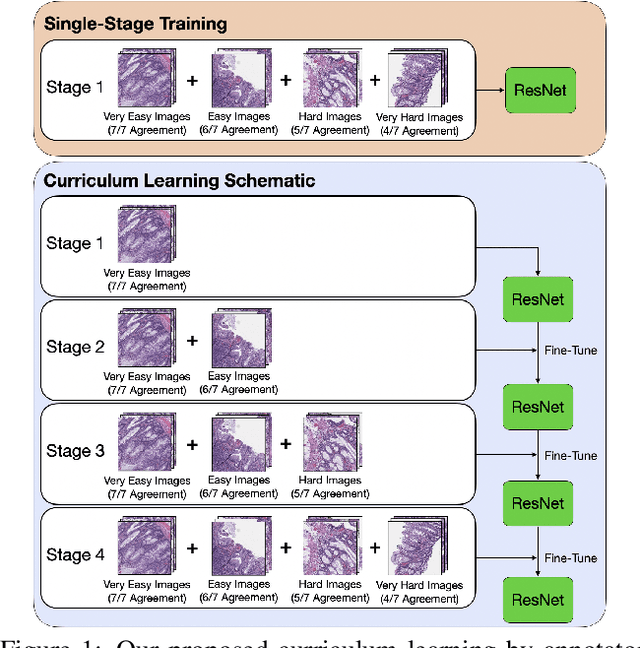
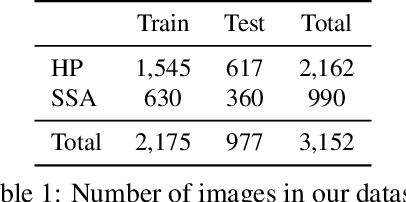
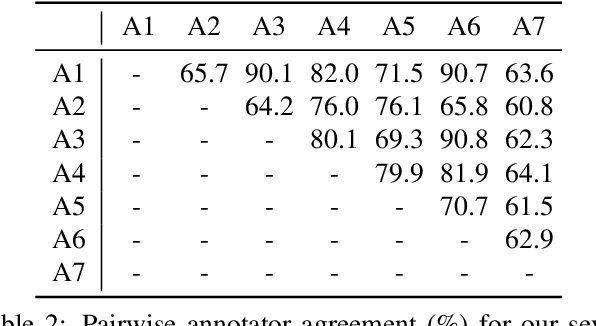
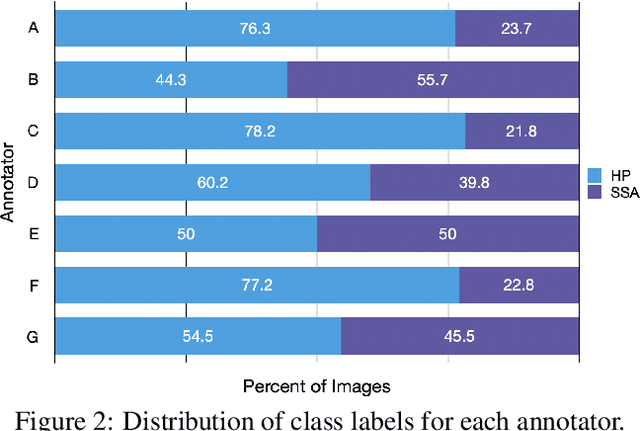
Applying curriculum learning requires both a range of difficulty in data and a method for determining the difficulty of examples. In many tasks, however, satisfying these requirements can be a formidable challenge. In this paper, we contend that histopathology image classification is a compelling use case for curriculum learning. Based on the nature of histopathology images, a range of difficulty inherently exists among examples, and, since medical datasets are often labeled by multiple annotators, annotator agreement can be used as a natural proxy for the difficulty of a given example. Hence, we propose a simple curriculum learning method that trains on progressively-harder images as determined by annotator agreement. We evaluate our hypothesis on the challenging and clinically-important task of colorectal polyp classification. Whereas vanilla training achieves an AUC of 83.7% for this task, a model trained with our proposed curriculum learning approach achieves an AUC of 88.2%, an improvement of 4.5%. Our work aims to inspire researchers to think more creatively and rigorously when choosing contexts for applying curriculum learning.
COBE: Contextualized Object Embeddings from Narrated Instructional Video
Jul 14, 2020

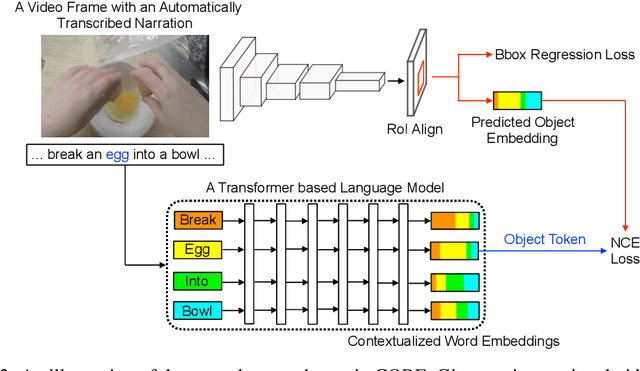

Many objects in the real world undergo dramatic variations in visual appearance. For example, a tomato may be red or green, sliced or chopped, fresh or fried, liquid or solid. Training a single detector to accurately recognize tomatoes in all these different states is challenging. On the other hand, contextual cues (e.g., the presence of a knife, a cutting board, a strainer or a pan) are often strongly indicative of how the object appears in the scene. Recognizing such contextual cues is useful not only to improve the accuracy of object detection or to determine the state of the object, but also to understand its functional properties and to infer ongoing or upcoming human-object interactions. A fully-supervised approach to recognizing object states and their contexts in the real-world is unfortunately marred by the long-tailed, open-ended distribution of the data, which would effectively require massive amounts of annotations to capture the appearance of objects in all their different forms. Instead of relying on manually-labeled data for this task, we propose a new framework for learning Contextualized OBject Embeddings (COBE) from automatically-transcribed narrations of instructional videos. We leverage the semantic and compositional structure of language by training a visual detector to predict a contextualized word embedding of the object and its associated narration. This enables the learning of an object representation where concepts relate according to a semantic language metric. Our experiments show that our detector learns to predict a rich variety of contextual object information, and that it is highly effective in the settings of few-shot and zero-shot learning.
Generalized Many-Way Few-Shot Video Classification
Jul 09, 2020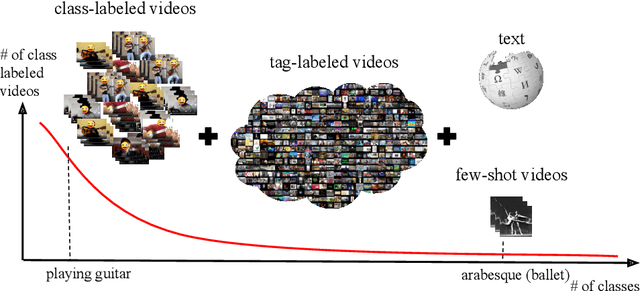
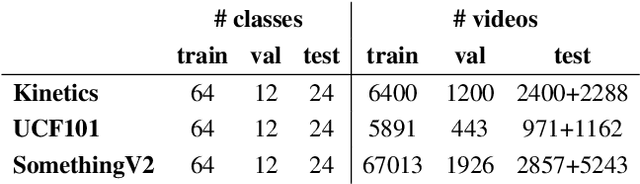
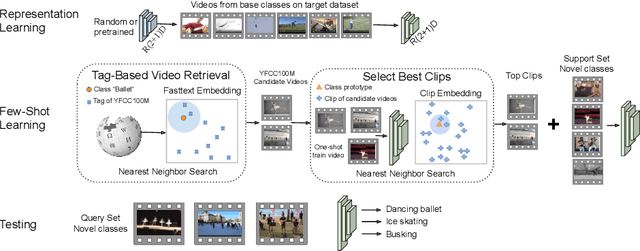
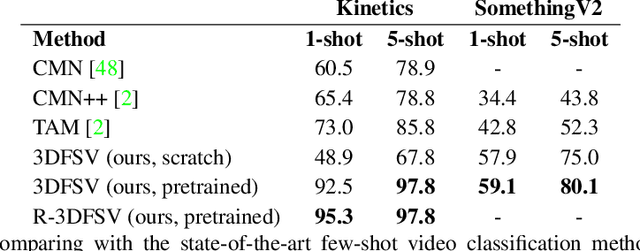
Few-shot learning methods operate in low data regimes. The aim is to learn with few training examples per class. Although significant progress has been made in few-shot image classification, few-shot video recognition is relatively unexplored and methods based on 2D CNNs are unable to learn temporal information. In this work we thus develop a simple 3D CNN baseline, surpassing existing methods by a large margin. To circumvent the need of labeled examples, we propose to leverage weakly-labeled videos from a large dataset using tag retrieval followed by selecting the best clips with visual similarities, yielding further improvement. Our results saturate current 5-way benchmarks for few-shot video classification and therefore we propose a new challenging benchmark involving more classes and a mixture of classes with varying supervision.
Video Understanding as Machine Translation
Jun 12, 2020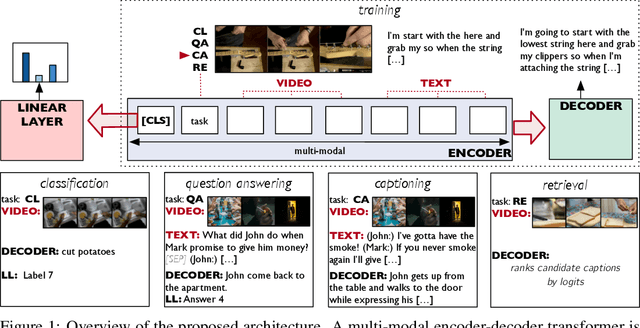
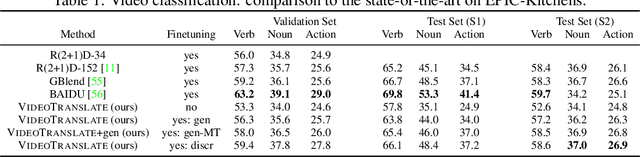
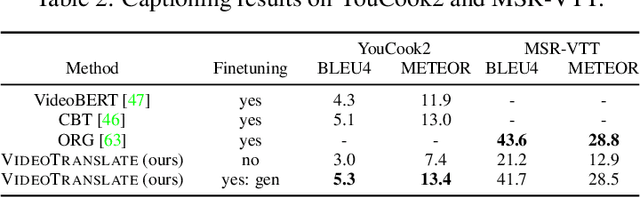

With the advent of large-scale multimodal video datasets, especially sequences with audio or transcribed speech, there has been a growing interest in self-supervised learning of video representations. Most prior work formulates the objective as a contrastive metric learning problem between the modalities. To enable effective learning, however, these strategies require a careful selection of positive and negative samples often combined with hand-designed curriculum policies. In this work we remove the need for negative sampling by taking a generative modeling approach that poses the objective as a translation problem between modalities. Such a formulation allows us to tackle a wide variety of downstream video understanding tasks by means of a single unified framework, without the need for large batches of negative samples common in contrastive metric learning. We experiment with the large-scale HowTo100M dataset for training, and report performance gains over the state-of-the-art on several downstream tasks including video classification (EPIC-Kitchens), question answering (TVQA), captioning (TVC, YouCook2, and MSR-VTT), and text-based clip retrieval (YouCook2 and MSR-VTT).
Stein Variational Inference for Discrete Distributions
Mar 01, 2020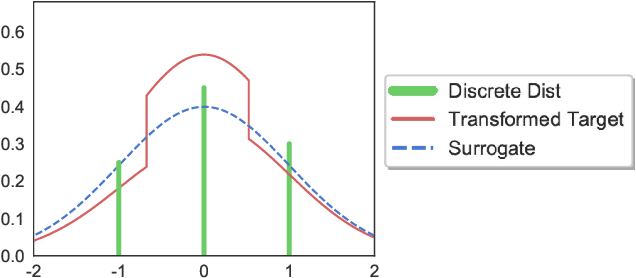
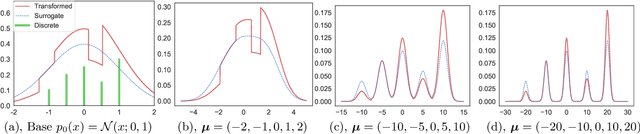
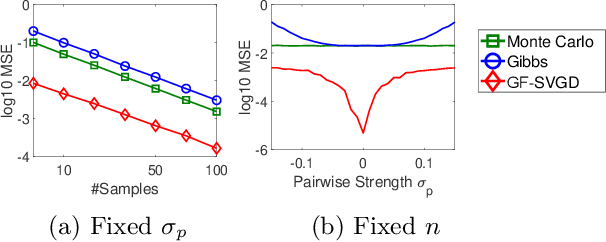
Gradient-based approximate inference methods, such as Stein variational gradient descent (SVGD), provide simple and general-purpose inference engines for differentiable continuous distributions. However, existing forms of SVGD cannot be directly applied to discrete distributions. In this work, we fill this gap by proposing a simple yet general framework that transforms discrete distributions to equivalent piecewise continuous distributions, on which the gradient-free SVGD is applied to perform efficient approximate inference. The empirical results show that our method outperforms traditional algorithms such as Gibbs sampling and discontinuous Hamiltonian Monte Carlo on various challenging benchmarks of discrete graphical models. We demonstrate that our method provides a promising tool for learning ensembles of binarized neural network (BNN), outperforming other widely used ensemble methods on learning binarized AlexNet on CIFAR-10 dataset. In addition, such transform can be straightforwardly employed in gradient-free kernelized Stein discrepancy to perform goodness-of-fit (GOF) test on discrete distributions. Our proposed method outperforms existing GOF test methods for intractable discrete distributions.
Listen to Look: Action Recognition by Previewing Audio
Dec 12, 2019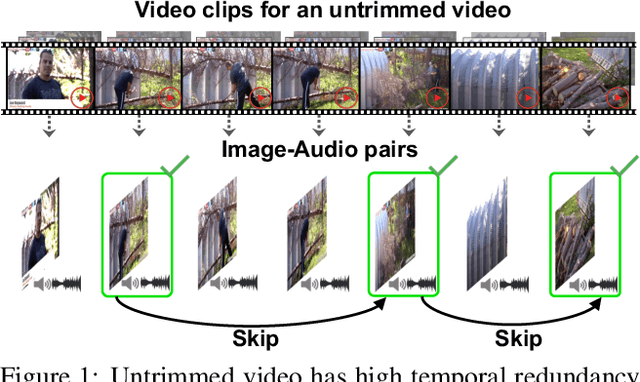

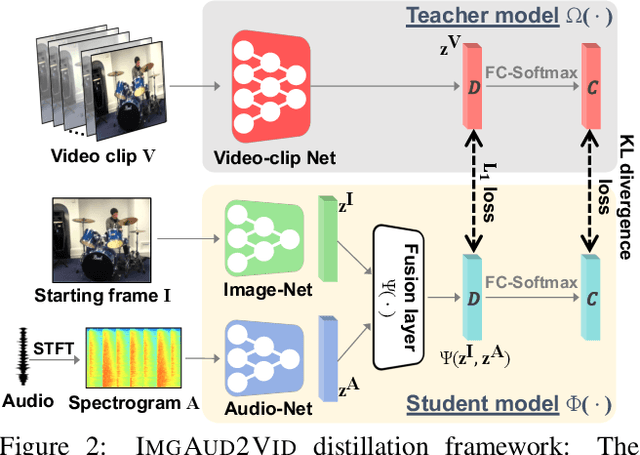

In the face of the video data deluge, today's expensive clip-level classifiers are increasingly impractical. We propose a framework for efficient action recognition in untrimmed video that uses audio as a preview mechanism to eliminate both short-term and long-term visual redundancies. First, we devise an ImgAud2Vid framework that hallucinates clip-level features by distilling from lighter modalities---a single frame and its accompanying audio---reducing short-term temporal redundancy for efficient clip-level recognition. Second, building on ImgAud2Vid, we further propose ImgAud-Skimming, an attention-based long short-term memory network that iteratively selects useful moments in untrimmed videos, reducing long-term temporal redundancy for efficient video-level recognition. Extensive experiments on four action recognition datasets demonstrate that our method achieves the state-of-the-art in terms of both recognition accuracy and speed.
Classifying, Segmenting, and Tracking Object Instances in Video with Mask Propagation
Dec 10, 2019

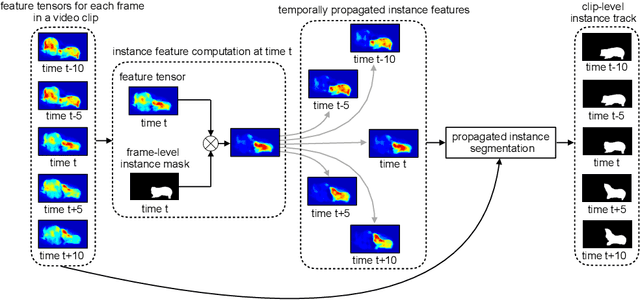

We introduce a method for simultaneously classifying, segmenting and tracking object instances in a video sequence. Our method, named MaskProp, adapts the popular Mask R-CNN to video by adding a mask propagation branch that propagates frame-level object instance masks from each video frame to all the other frames in a video clip. This allows our system to predict clip-level instance tracks with respect to the object instances segmented in the middle frame of the clip. Clip-level instance tracks generated densely for each frame in the sequence are finally aggregated to produce video-level object instance segmentation and classification. Our experiments demonstrate that our clip-level instance segmentation makes our approach robust to motion blur and object occlusions in video. MaskProp achieves the best reported accuracy on the YouTube-VIS dataset, outperforming the ICCV 2019 video instance segmentation challenge winner despite being much simpler and using orders of magnitude less labeled data (1.3M vs 1B images and 860K vs 14M bounding boxes)
Self-Supervised Learning by Cross-Modal Audio-Video Clustering
Nov 28, 2019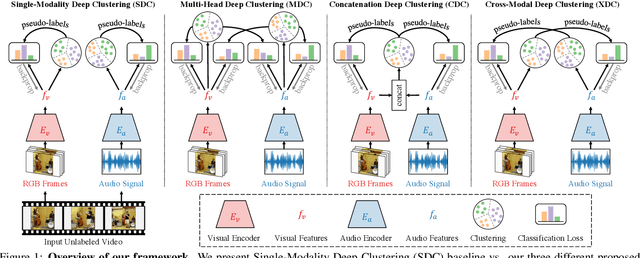
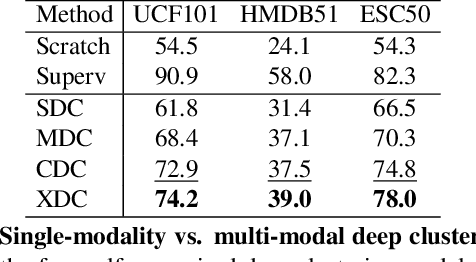
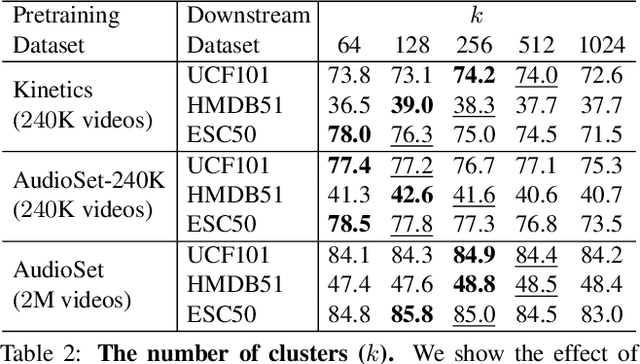
The visual and audio modalities are highly correlated yet they contain different information. Their strong correlation makes it possible to predict the semantics of one from the other with good accuracy. Their intrinsic differences make cross-modal prediction a potentially more rewarding pretext task for self-supervised learning of video and audio representations compared to within-modality learning. Based on this intuition, we propose Cross-Modal Deep Clustering (XDC), a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). This cross-modal supervision helps XDC utilize the semantic correlation and the differences between the two modalities. Our experiments show that XDC significantly outperforms single-modality clustering and other multi-modal variants. Our XDC achieves state-of-the-art accuracy among self-supervised methods on several video and audio benchmarks including HMDB51, UCF101, ESC50, and DCASE. Most importantly, the video model pretrained with XDC significantly outperforms the same model pretrained with full-supervision on both ImageNet and Kinetics in action recognition on HMDB51 and UCF101. To the best of our knowledge, XDC is the first method to demonstrate that self-supervision outperforms large-scale full-supervision in representation learning for action recognition.