 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning by Cross-Modal Audio-Video Clustering
Paper and Code
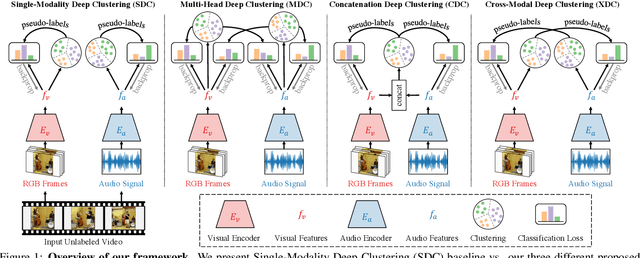
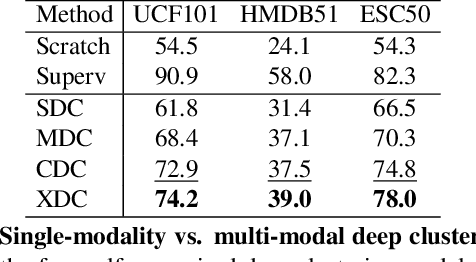
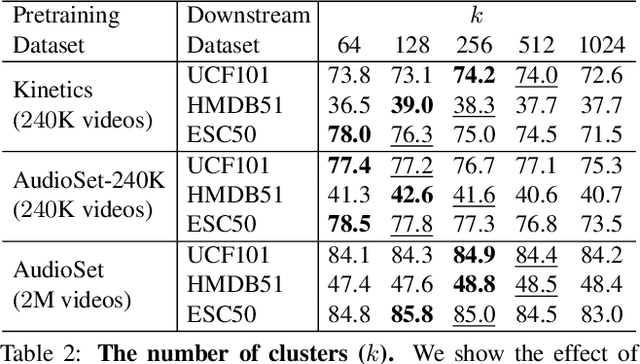
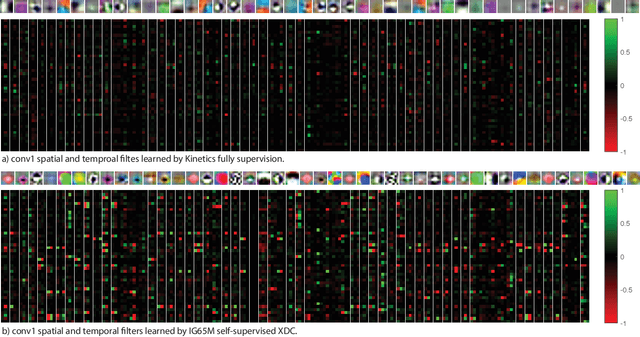
The visual and audio modalities are highly correlated yet they contain different information. Their strong correlation makes it possible to predict the semantics of one from the other with good accuracy. Their intrinsic differences make cross-modal prediction a potentially more rewarding pretext task for self-supervised learning of video and audio representations compared to within-modality learning. Based on this intuition, we propose Cross-Modal Deep Clustering (XDC), a novel self-supervised method that leverages unsupervised clustering in one modality (e.g. audio) as a supervisory signal for the other modality (e.g. video). This cross-modal supervision helps XDC utilize the semantic correlation and the differences between the two modalities. Our experiments show that XDC significantly outperforms single-modality clustering and other multi-modal variants. Our XDC achieves state-of-the-art accuracy among self-supervised methods on several video and audio benchmarks including HMDB51, UCF101, ESC50, and DCASE. Most importantly, the video model pretrained with XDC significantly outperforms the same model pretrained with full-supervision on both ImageNet and Kinetics in action recognition on HMDB51 and UCF101. To the best of our knowledge, XDC is the first method to demonstrate that self-supervision outperforms large-scale full-supervision in representation learning for action recognition.