 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReproducing kernel Hilbert spaces on manifolds: Sobolev and Diffusion spaces
May 27, 2019We study reproducing kernel Hilbert spaces (RKHS) on a Riemannian manifold. In particular, we discuss under which condition Sobolev spaces are RKHS and characterize their reproducing kernels. Further, we introduce and discuss a class of smoother RKHS that we call diffusion spaces. We illustrate the general results with a number of detailed examples.
Theory III: Dynamics and Generalization in Deep Networks - a simple solution
Apr 11, 2019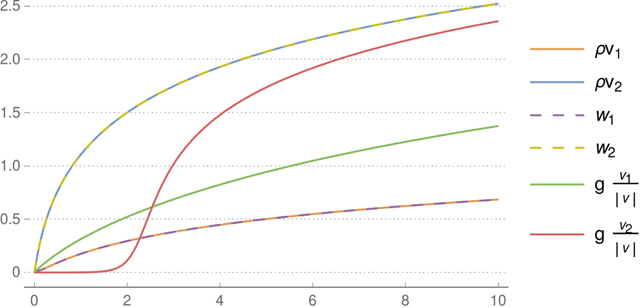
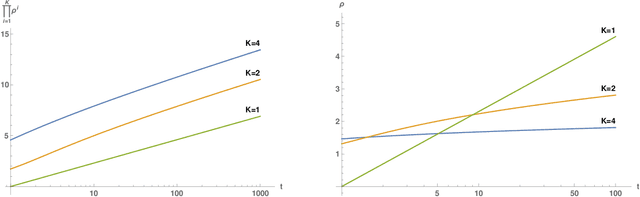

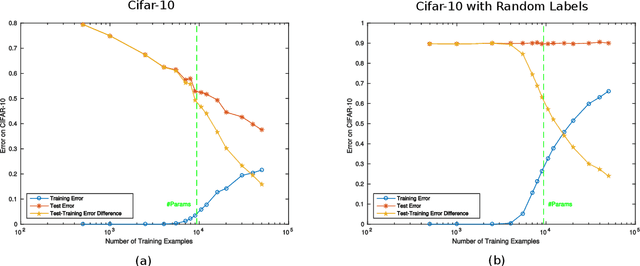
We review recent observations on the dynamical systems induced by gradient descent (GD) methods used for training deep networks and summarize properties of the solutions they converge to. Recent results illuminate the absence of overfitting in the special case of linear networks for binary classification. They prove that minimization of loss functions such as the logistic, the cross-entropy and the exponential loss yields asymptotic convergence to the maximum margin solution for linearly separable datasets, independently of the initial conditions. Here we discuss the case of nonlinear DNNs near zero minima of the empirical loss, under exponential-type and square losses, for several variations of the basic GD algorithm, including a new NMGD version that converges to the minimum norm fixed points. Our main results are: 1) GD algorithms with weight normalization constraint achieve generalization; 2) the fundamental reason for the effectiveness of existing weight and batch normalization techniques is that they are approximate implementations of maximizing the margin under unit norm constraint; 3) even without explicit unit norm constraints, generalization can still be obtained for not-too-deep networks because standard GD is intrinsically consistent with the dynamics of normalized weights. In addition, the balance of the weights across different layers, if present at initialization, is maintained by the gradient flow. In the perspective of these theoretical results, we discuss experimental evidence around the apparent absence of overfitting, that is the observation that the expected classification error does not get worse when increasing the number of parameters. Our explanation focuses on the implicit normalization enforced by algorithms such as batch normalization. In particular, the control of the norm of the weights is related to Halpern iterations for minimum norm solutions.
Gaussian Process Optimization with Adaptive Sketching: Scalable and No Regret
Mar 13, 2019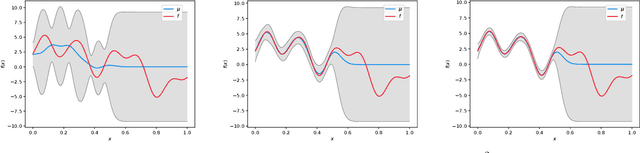
Gaussian processes (GP) are a popular Bayesian approach for the optimization of black-box functions. Despite their effectiveness in simple problems, GP-based algorithms hardly scale to complex high-dimensional functions, as their per-iteration time and space cost is at least quadratic in the number of dimensions $d$ and iterations $t$. Given a set of $A$ alternative to choose from, the overall runtime $O(t^3A)$ quickly becomes prohibitive. In this paper, we introduce BKB (budgeted kernelized bandit), a novel approximate GP algorithm for optimization under bandit feedback that achieves near-optimal regret (and hence near-optimal convergence rate) with near-constant per-iteration complexity and no assumption on the input space or covariance of the GP. Combining a kernelized linear bandit algorithm (GP-UCB) with randomized matrix sketching technique (i.e., leverage score sampling), we prove that selecting inducing points based on their posterior variance gives an accurate low-rank approximation of the GP, preserving variance estimates and confidence intervals. As a consequence, BKB does not suffer from variance starvation, an important problem faced by many previous sparse GP approximations. Moreover, we show that our procedure selects at most $\tilde{O}(d_{eff})$ points, where $d_{eff}$ is the effective dimension of the explored space, which is typically much smaller than both $d$ and $t$. This greatly reduces the dimensionality of the problem, thus leading to a $O(TAd_{eff}^2)$ runtime and $O(A d_{eff})$ space complexity.
Beating SGD Saturation with Tail-Averaging and Minibatching
Feb 22, 2019While stochastic gradient descent (SGD) is one of the major workhorses in machine learning, the learning properties of many practically used variants are poorly understood. In this paper, we consider least squares learning in a nonparametric setting and contribute to filling this gap by focusing on the effect and interplay of multiple passes, mini-batching and averaging, and in particular tail averaging. Our results show how these different variants of SGD can be combined to achieve optimal learning errors, hence providing practical insights. In particular, we show for the first time in the literature that tail averaging allows faster convergence rates than uniform averaging in the nonparametric setting. Finally, we show that a combination of tail-averaging and minibatching allows more aggressive step-size choices than using any one of said components.
A computational model for grid maps in neural populations
Feb 19, 2019
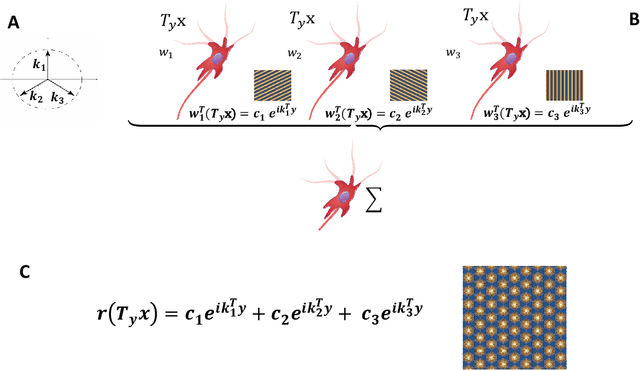
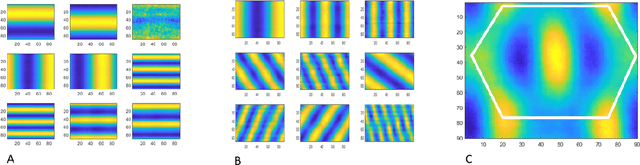
Grid cells in the entorhinal cortex, together with place, speed and border cells, are major contributors to the organization of spatial representations in the brain. In this contribution we introduce a novel theoretical and algorithmic framework able to explain the emergence of hexagonal grid-like response patterns from the statistics of the input stimuli. We show that this pattern is a result of minimal variance encoding of neurons. The novelty lies into the formulation of the encoding problem through the modern Frame Theory language, specifically that of equiangular Frames, providing new insights about the optimality of hexagonal grid receptive fields. The model proposed overcomes some crucial limitations of the current attractor and oscillatory models. It is based on the well-accepted and tested hypothesis of Hebbian learning, providing a simplified cortical-based framework that does not require the presence of theta velocity-driven oscillations (oscillatory model) or translational symmetries in the synaptic connections (attractor model). We moreover demonstrate that the proposed encoding mechanism naturally maps shifts, rotations and scaling of the stimuli onto the shape of grid cells' receptive fields, giving a straightforward explanation of the experimental evidence of grid cells remapping under transformations of environmental cues.
Are we done with object recognition? The iCub robot's perspective
Jan 03, 2019
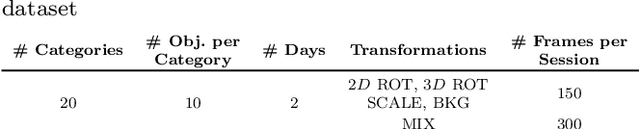


We report on an extensive study of the benefits and limitations of current deep learning approaches to object recognition in robot vision scenarios, introducing a novel dataset used for our investigation. To avoid the biases in currently available datasets, we consider a natural human-robot interaction setting to design a data-acquisition protocol for visual object recognition on the iCub humanoid robot. Analyzing the performance of off-the-shelf models trained off-line on large-scale image retrieval datasets, we show the necessity for knowledge transfer. We evaluate different ways in which this last step can be done, and identify the major bottlenecks affecting robotic scenarios. By studying both object categorization and identification problems, we highlight key differences between object recognition in robotics applications and in image retrieval tasks, for which the considered deep learning approaches have been originally designed. In a nutshell, our results confirm the remarkable improvements yield by deep learning in this setting, while pointing to specific open challenges that need be addressed for seamless deployment in robotics.
* 21 pages + supplementary material
Optimal Rates for Spectral Algorithms with Least-Squares Regression over Hilbert Spaces
Nov 05, 2018In this paper, we study regression problems over a separable Hilbert space with the square loss, covering non-parametric regression over a reproducing kernel Hilbert space. We investigate a class of spectral-regularized algorithms, including ridge regression, principal component analysis, and gradient methods. We prove optimal, high-probability convergence results in terms of variants of norms for the studied algorithms, considering a capacity assumption on the hypothesis space and a general source condition on the target function. Consequently, we obtain almost sure convergence results with optimal rates. Our results improve and generalize previous results, filling a theoretical gap for the non-attainable cases.
Learning with SGD and Random Features
Nov 01, 2018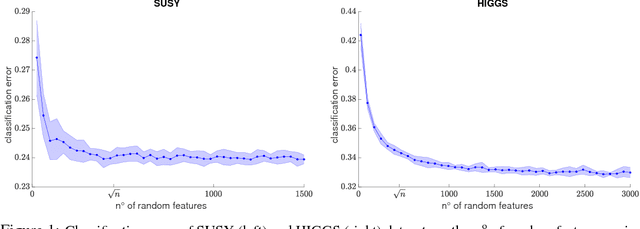
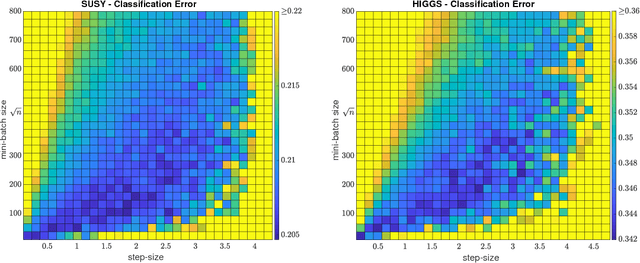
Sketching and stochastic gradient methods are arguably the most common techniques to derive efficient large scale learning algorithms. In this paper, we investigate their application in the context of nonparametric statistical learning. More precisely, we study the estimator defined by stochastic gradient with mini batches and random features. The latter can be seen as form of nonlinear sketching and used to define approximate kernel methods. The considered estimator is not explicitly penalized/constrained and regularization is implicit. Indeed, our study highlights how different parameters, such as number of features, iterations, step-size and mini-batch size control the learning properties of the solutions. We do this by deriving optimal finite sample bounds, under standard assumptions. The obtained results are corroborated and illustrated by numerical experiments.
On Fast Leverage Score Sampling and Optimal Learning
Oct 31, 2018
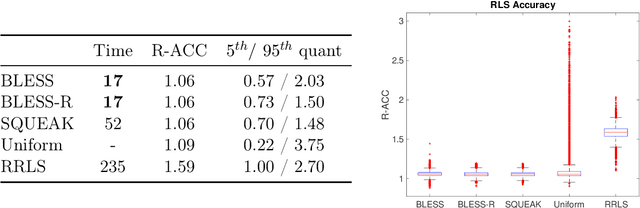
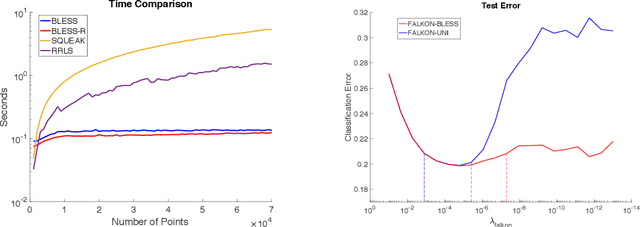
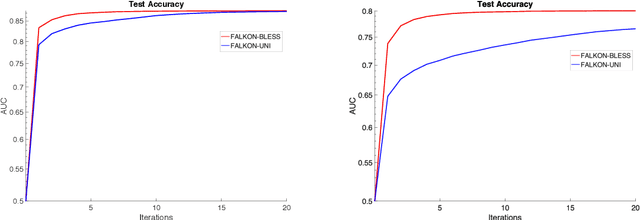
Leverage score sampling provides an appealing way to perform approximate computations for large matrices. Indeed, it allows to derive faithful approximations with a complexity adapted to the problem at hand. Yet, performing leverage scores sampling is a challenge in its own right requiring further approximations. In this paper, we study the problem of leverage score sampling for positive definite matrices defined by a kernel. Our contribution is twofold. First we provide a novel algorithm for leverage score sampling and second, we exploit the proposed method in statistical learning by deriving a novel solver for kernel ridge regression. Our main technical contribution is showing that the proposed algorithms are currently the most efficient and accurate for these problems.
Speeding-up Object Detection Training for Robotics with FALKON
Aug 27, 2018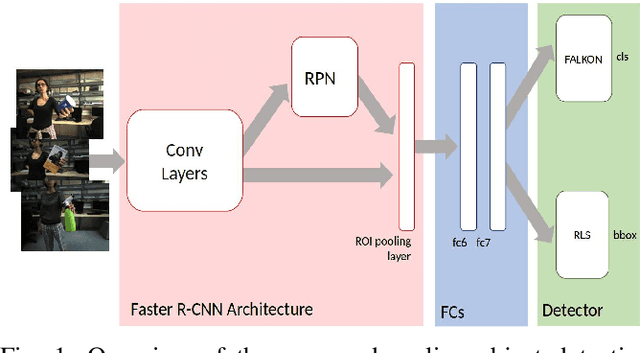
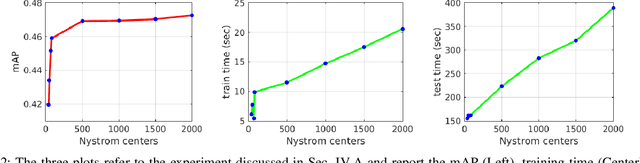


Latest deep learning methods for object detection provide remarkable performance, but have limits when used in robotic applications. One of the most relevant issues is the long training time, which is due to the large size and imbalance of the associated training sets, characterized by few positive and a large number of negative examples (i.e. background). Proposed approaches are based on end-to-end learning by back-propagation [22] or kernel methods trained with Hard Negatives Mining on top of deep features [8]. These solutions are effective, but prohibitively slow for on-line applications. In this paper we propose a novel pipeline for object detection that overcomes this problem and provides comparable performance, with a 60x training speedup. Our pipeline combines (i) the Region Proposal Network and the deep feature extractor from [22] to efficiently select candidate RoIs and encode them into powerful representations, with (ii) the FALKON [23] algorithm, a novel kernel-based method that allows fast training on large scale problems (millions of points). We address the size and imbalance of training data by exploiting the stochastic subsampling intrinsic into the method and a novel, fast, bootstrapping approach. We assess the effectiveness of the approach on a standard Computer Vision dataset (PASCAL VOC 2007 [5]) and demonstrate its applicability to a real robotic scenario with the iCubWorld Transformations [18] dataset.