 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Semi-Supervised Learning for 3D Objects
Oct 25, 2021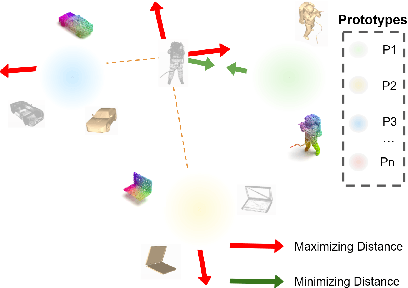
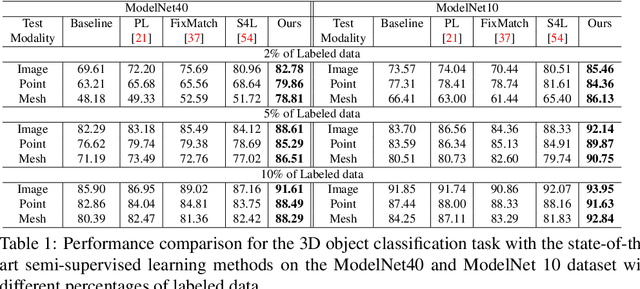
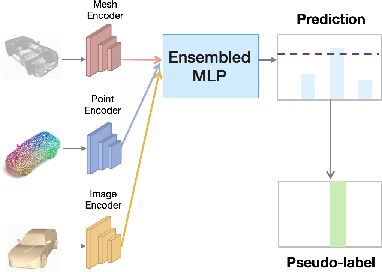
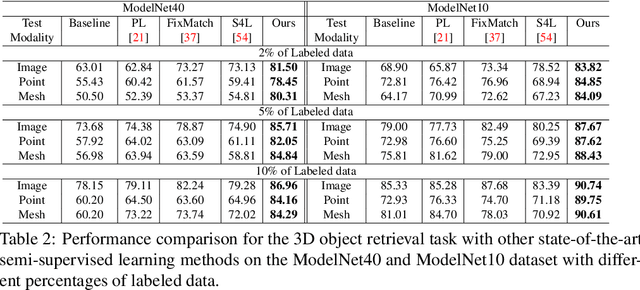
In recent years, semi-supervised learning has been widely explored and shows excellent data efficiency for 2D data. There is an emerging need to improve data efficiency for 3D tasks due to the scarcity of labeled 3D data. This paper explores how the coherence of different modelities of 3D data (e.g. point cloud, image, and mesh) can be used to improve data efficiency for both 3D classification and retrieval tasks. We propose a novel multimodal semi-supervised learning framework by introducing instance-level consistency constraint and a novel multimodal contrastive prototype (M2CP) loss. The instance-level consistency enforces the network to generate consistent representations for multimodal data of the same object regardless of its modality. The M2CP maintains a multimodal prototype for each class and learns features with small intra-class variations by minimizing the feature distance of each object to its prototype while maximizing the distance to the others. Our proposed framework significantly outperforms all the state-of-the-art counterparts for both classification and retrieval tasks by a large margin on the modelNet10 and ModelNet40 datasets.
Advancing Self-supervised Monocular Depth Learning with Sparse LiDAR
Sep 21, 2021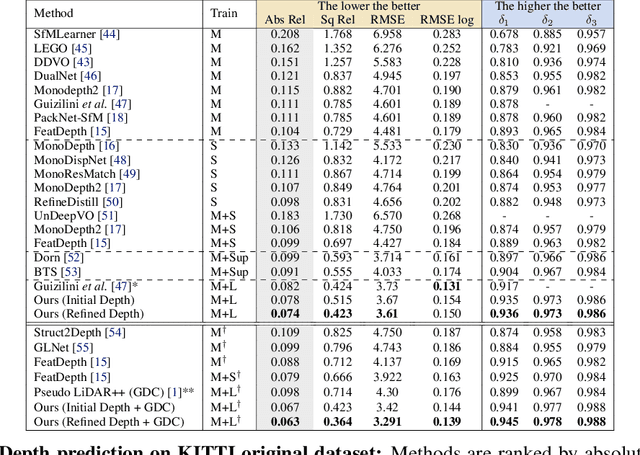
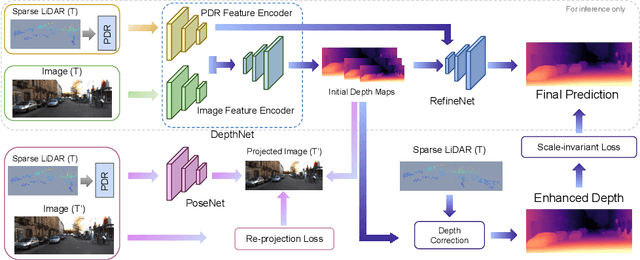
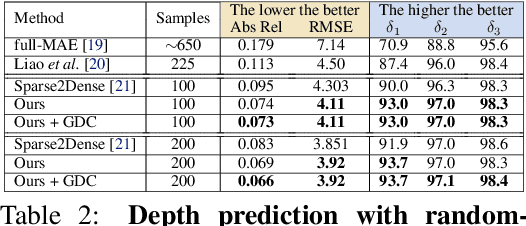
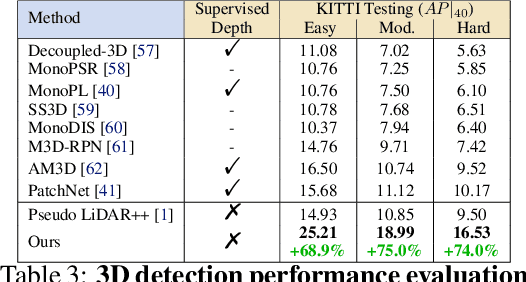
Self-supervised monocular depth prediction provides a cost-effective solution to obtain the 3D location of each pixel. However, the existing approaches usually lead to unsatisfactory accuracy, which is critical for autonomous robots. In this paper, we propose a novel two-stage network to advance the self-supervised monocular dense depth learning by leveraging low-cost sparse (e.g. 4-beam) LiDAR. Unlike the existing methods that use sparse LiDAR mainly in a manner of time-consuming iterative post-processing, our model fuses monocular image features and sparse LiDAR features to predict initial depth maps. Then, an efficient feed-forward refine network is further designed to correct the errors in these initial depth maps in pseudo-3D space with real-time performance. Extensive experiments show that our proposed model significantly outperforms all the state-of-the-art self-supervised methods, as well as the sparse-LiDAR-based methods on both self-supervised monocular depth prediction and completion tasks. With the accurate dense depth prediction, our model outperforms the state-of-the-art sparse-LiDAR-based method (Pseudo-LiDAR++) by more than 68% for the downstream task monocular 3D object detection on the KITTI Leaderboard.
Cross-modal Center Loss
Aug 08, 2020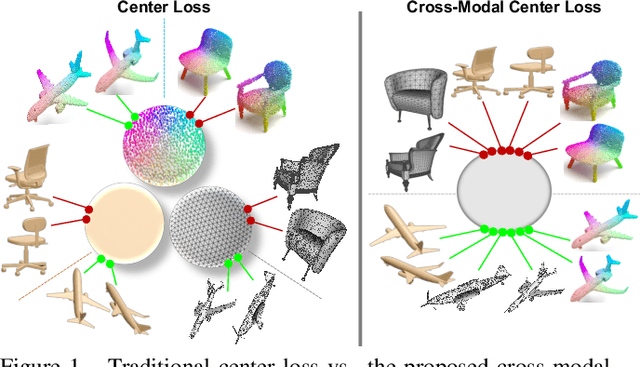
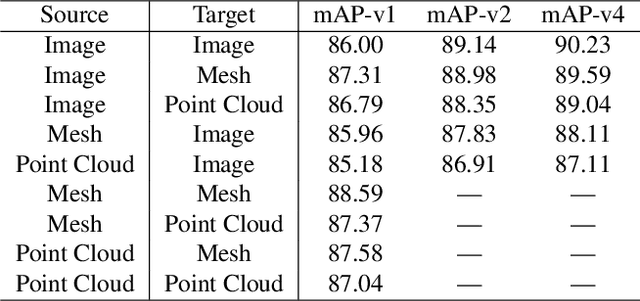
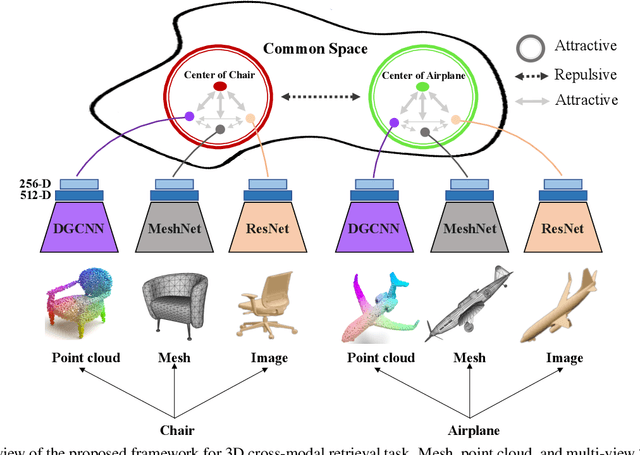
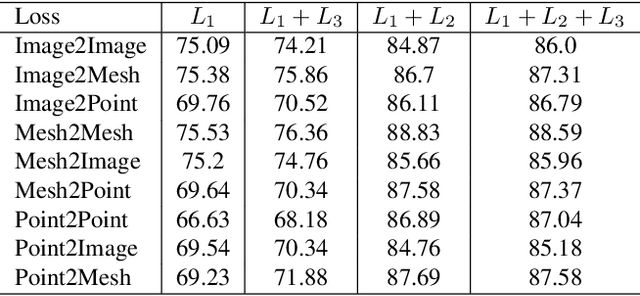
Cross-modal retrieval aims to learn discriminative and modal-invariant features for data from different modalities. Unlike the existing methods which usually learn from the features extracted by offline networks, in this paper, we propose an approach to jointly train the components of cross-modal retrieval framework with metadata, and enable the network to find optimal features. The proposed end-to-end framework is updated with three loss functions: 1) a novel cross-modal center loss to eliminate cross-modal discrepancy, 2) cross-entropy loss to maximize inter-class variations, and 3) mean-square-error loss to reduce modality variations. In particular, our proposed cross-modal center loss minimizes the distances of features from objects belonging to the same class across all modalities. Extensive experiments have been conducted on the retrieval tasks across multi-modalities, including 2D image, 3D point cloud, and mesh data. The proposed framework significantly outperforms the state-of-the-art methods on the ModelNet40 dataset.
Self-supervised Modal and View Invariant Feature Learning
May 28, 2020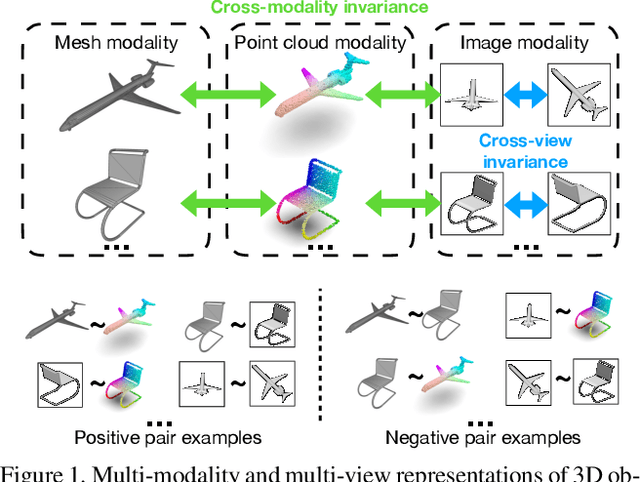
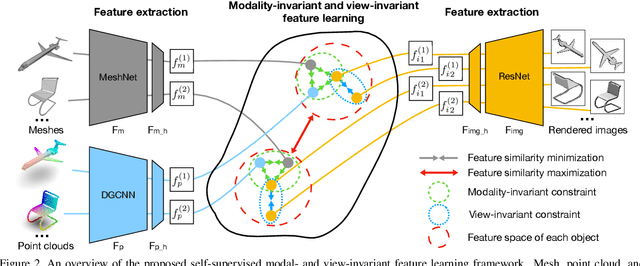
Most of the existing self-supervised feature learning methods for 3D data either learn 3D features from point cloud data or from multi-view images. By exploring the inherent multi-modality attributes of 3D objects, in this paper, we propose to jointly learn modal-invariant and view-invariant features from different modalities including image, point cloud, and mesh with heterogeneous networks for 3D data. In order to learn modal- and view-invariant features, we propose two types of constraints: cross-modal invariance constraint and cross-view invariant constraint. Cross-modal invariance constraint forces the network to maximum the agreement of features from different modalities for same objects, while the cross-view invariance constraint forces the network to maximum agreement of features from different views of images for same objects. The quality of learned features has been tested on different downstream tasks with three modalities of data including point cloud, multi-view images, and mesh. Furthermore, the invariance cross different modalities and views are evaluated with the cross-modal retrieval task. Extensive evaluation results demonstrate that the learned features are robust and have strong generalizability across different tasks.
Recognizing American Sign Language Nonmanual Signal Grammar Errors in Continuous Videos
May 01, 2020
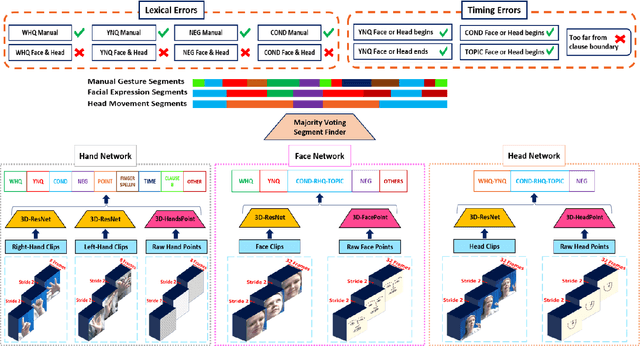
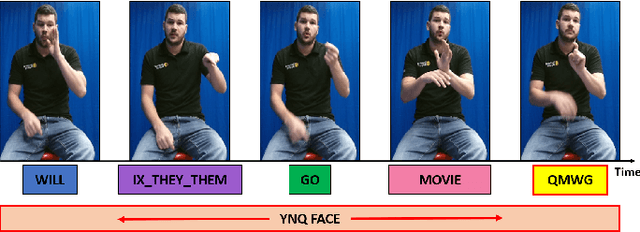
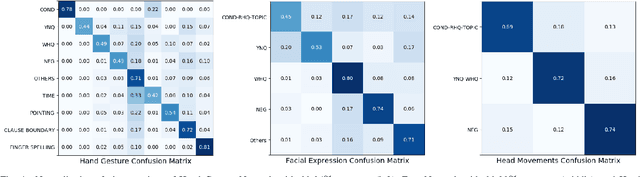
As part of the development of an educational tool that can help students achieve fluency in American Sign Language (ASL) through independent and interactive practice with immediate feedback, this paper introduces a near real-time system to recognize grammatical errors in continuous signing videos without necessarily identifying the entire sequence of signs. Our system automatically recognizes if performance of ASL sentences contains grammatical errors made by ASL students. We first recognize the ASL grammatical elements including both manual gestures and nonmanual signals independently from multiple modalities (i.e. hand gestures, facial expressions, and head movements) by 3D-ResNet networks. Then the temporal boundaries of grammatical elements from different modalities are examined to detect ASL grammatical mistakes by using a sliding window-based approach. We have collected a dataset of continuous sign language, ASL-HW-RGBD, covering different aspects of ASL grammars for training and testing. Our system is able to recognize grammatical elements on ASL-HW-RGBD from manual gestures, facial expressions, and head movements and successfully detect 8 ASL grammatical mistakes.
Self-supervised Feature Learning by Cross-modality and Cross-view Correspondences
Apr 13, 2020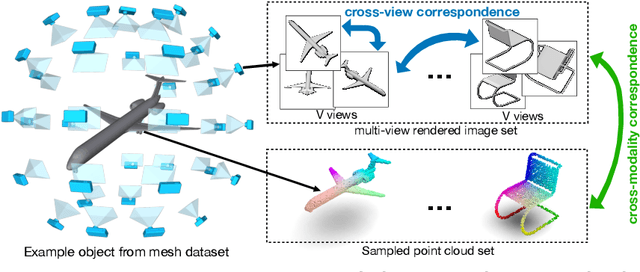

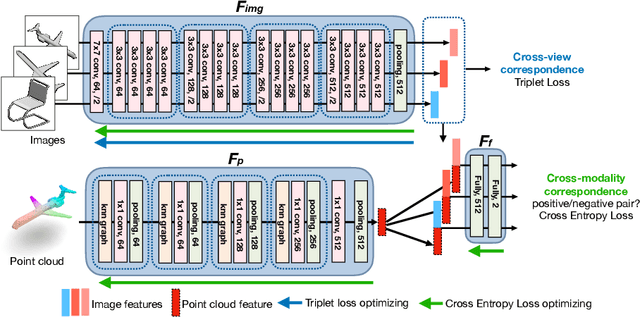

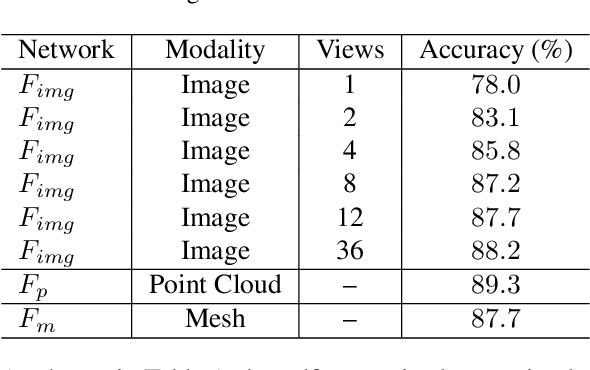
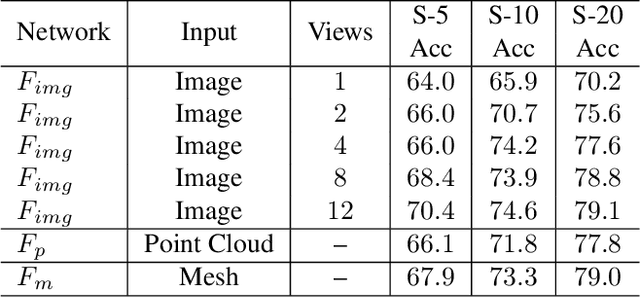
The success of supervised learning requires large-scale ground truth labels which are very expensive, time-consuming, or may need special skills to annotate. To address this issue, many self- or un-supervised methods are developed. Unlike most existing self-supervised methods to learn only 2D image features or only 3D point cloud features, this paper presents a novel and effective self-supervised learning approach to jointly learn both 2D image features and 3D point cloud features by exploiting cross-modality and cross-view correspondences without using any human annotated labels. Specifically, 2D image features of rendered images from different views are extracted by a 2D convolutional neural network, and 3D point cloud features are extracted by a graph convolution neural network. Two types of features are fed into a two-layer fully connected neural network to estimate the cross-modality correspondence. The three networks are jointly trained (i.e. cross-modality) by verifying whether two sampled data of different modalities belong to the same object, meanwhile, the 2D convolutional neural network is additionally optimized through minimizing intra-object distance while maximizing inter-object distance of rendered images in different views (i.e. cross-view). The effectiveness of the learned 2D and 3D features is evaluated by transferring them on five different tasks including multi-view 2D shape recognition, 3D shape recognition, multi-view 2D shape retrieval, 3D shape retrieval, and 3D part-segmentation. Extensive evaluations on all the five different tasks across different datasets demonstrate strong generalization and effectiveness of the learned 2D and 3D features by the proposed self-supervised method.
VideoSSL: Semi-Supervised Learning for Video Classification
Feb 29, 2020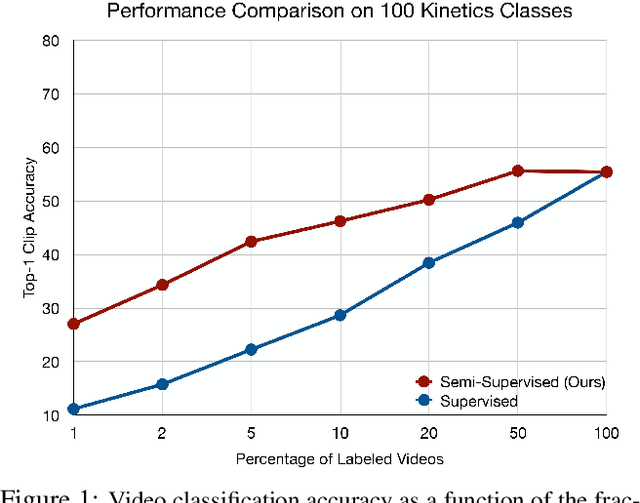



We propose a semi-supervised learning approach for video classification, VideoSSL, using convolutional neural networks (CNN). Like other computer vision tasks, existing supervised video classification methods demand a large amount of labeled data to attain good performance. However, annotation of a large dataset is expensive and time consuming. To minimize the dependence on a large annotated dataset, our proposed semi-supervised method trains from a small number of labeled examples and exploits two regulatory signals from unlabeled data. The first signal is the pseudo-labels of unlabeled examples computed from the confidences of the CNN being trained. The other is the normalized probabilities, as predicted by an image classifier CNN, that captures the information about appearances of the interesting objects in the video. We show that, under the supervision of these guiding signals from unlabeled examples, a video classification CNN can achieve impressive performances utilizing a small fraction of annotated examples on three publicly available datasets: UCF101, HMDB51 and Kinetics.
Recognizing American Sign Language Manual Signs from RGB-D Videos
Jun 07, 2019


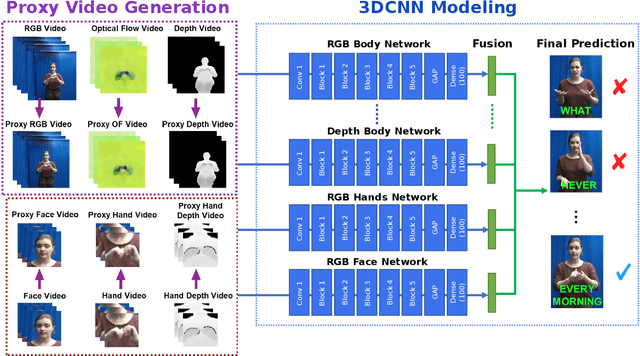
In this paper, we propose a 3D Convolutional Neural Network (3DCNN) based multi-stream framework to recognize American Sign Language (ASL) manual signs (consisting of movements of the hands, as well as non-manual face movements in some cases) in real-time from RGB-D videos, by fusing multimodality features including hand gestures, facial expressions, and body poses from multi-channels (RGB, depth, motion, and skeleton joints). To learn the overall temporal dynamics in a video, a proxy video is generated by selecting a subset of frames for each video which are then used to train the proposed 3DCNN model. We collect a new ASL dataset, ASL-100-RGBD, which contains 42 RGB-D videos captured by a Microsoft Kinect V2 camera, each of 100 ASL manual signs, including RGB channel, depth maps, skeleton joints, face features, and HDface. The dataset is fully annotated for each semantic region (i.e. the time duration of each word that the human signer performs). Our proposed method achieves 92.88 accuracy for recognizing 100 ASL words in our newly collected ASL-100-RGBD dataset. The effectiveness of our framework for recognizing hand gestures from RGB-D videos is further demonstrated on the Chalearn IsoGD dataset and achieves 76 accuracy which is 5.51 higher than the state-of-the-art work in terms of average fusion by using only 5 channels instead of 12 channels in the previous work.
Self-supervised Visual Feature Learning with Deep Neural Networks: A Survey
Feb 16, 2019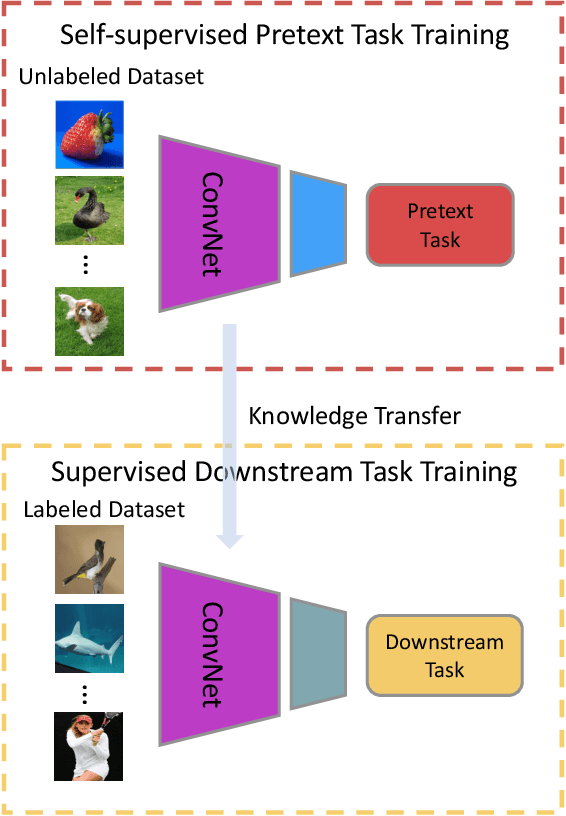
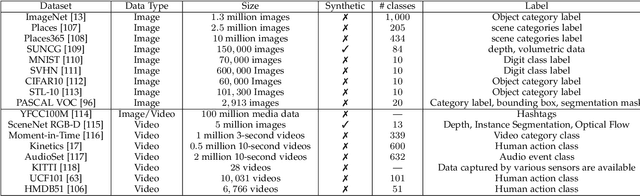
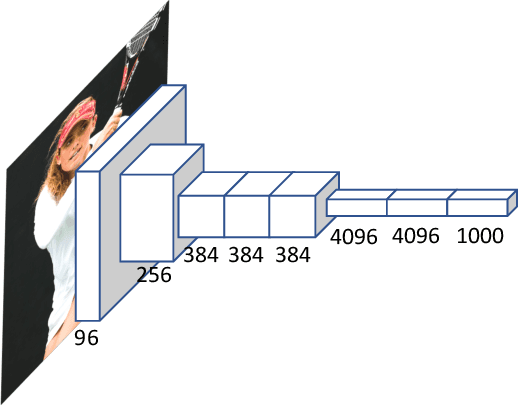
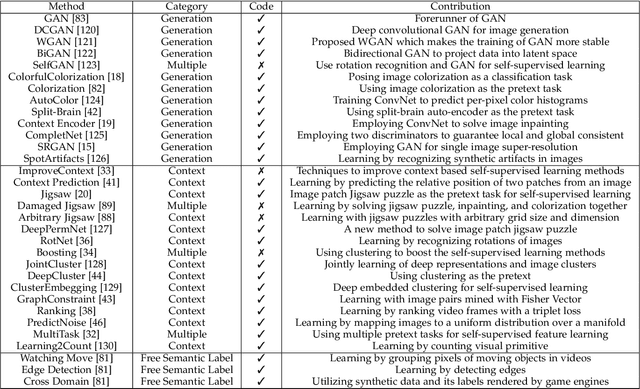
Large-scale labeled data are generally required to train deep neural networks in order to obtain better performance in visual feature learning from images or videos for computer vision applications. To avoid extensive cost of collecting and annotating large-scale datasets, as a subset of unsupervised learning methods, self-supervised learning methods are proposed to learn general image and video features from large-scale unlabeled data without using any human-annotated labels. This paper provides an extensive review of deep learning-based self-supervised general visual feature learning methods from images or videos. First, the motivation, general pipeline, and terminologies of this field are described. Then the common deep neural network architectures that used for self-supervised learning are summarized. Next, the main components and evaluation metrics of self-supervised learning methods are reviewed followed by the commonly used image and video datasets and the existing self-supervised visual feature learning methods. Finally, quantitative performance comparisons of the reviewed methods on benchmark datasets are summarized and discussed for both image and video feature learning. At last, this paper is concluded and lists a set of promising future directions for self-supervised visual feature learning.
LGAN: Lung Segmentation in CT Scans Using Generative Adversarial Network
Jan 11, 2019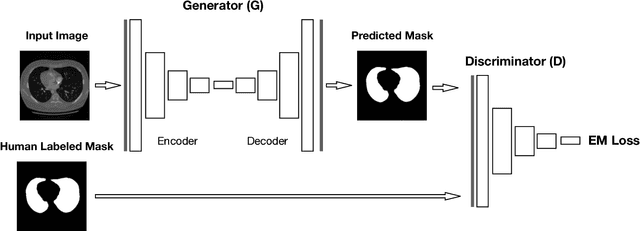
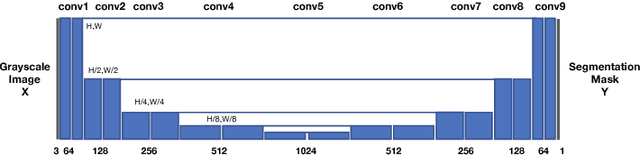
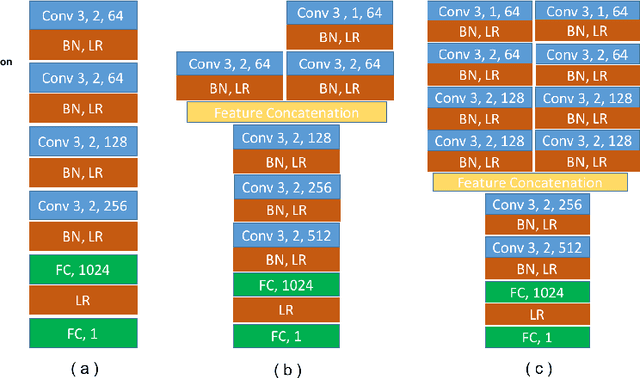
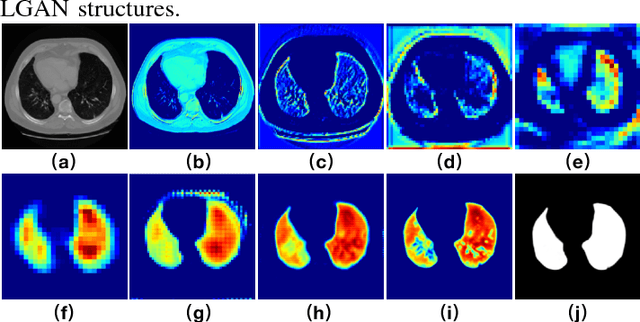
Lung segmentation in computerized tomography (CT) images is an important procedure in various lung disease diagnosis. Most of the current lung segmentation approaches are performed through a series of procedures with manually empirical parameter adjustments in each step. Pursuing an automatic segmentation method with fewer steps, in this paper, we propose a novel deep learning Generative Adversarial Network (GAN) based lung segmentation schema, which we denote as LGAN. Our proposed schema can be generalized to different kinds of neural networks for lung segmentation in CT images and is evaluated on a dataset containing 220 individual CT scans with two metrics: segmentation quality and shape similarity. Also, we compared our work with current state of the art methods. The results obtained with this study demonstrate that the proposed LGAN schema can be used as a promising tool for automatic lung segmentation due to its simplified procedure as well as its good performance.