 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Advanced Reinforcement Learning Framework for Online Scheduling of Deferrable Workloads in Cloud Computing
Jun 03, 2024



Efficient resource utilization and perfect user experience usually conflict with each other in cloud computing platforms. Great efforts have been invested in increasing resource utilization but trying not to affect users' experience for cloud computing platforms. In order to better utilize the remaining pieces of computing resources spread over the whole platform, deferrable jobs are provided with a discounted price to users. For this type of deferrable jobs, users are allowed to submit jobs that will run for a specific uninterrupted duration in a flexible range of time in the future with a great discount. With these deferrable jobs to be scheduled under the remaining capacity after deploying those on-demand jobs, it remains a challenge to achieve high resource utilization and meanwhile shorten the waiting time for users as much as possible in an online manner. In this paper, we propose an online deferrable job scheduling method called \textit{Online Scheduling for DEferrable jobs in Cloud} (\OSDEC{}), where a deep reinforcement learning model is adopted to learn the scheduling policy, and several auxiliary tasks are utilized to provide better state representations and improve the performance of the model. With the integrated reinforcement learning framework, the proposed method can well plan the deployment schedule and achieve a short waiting time for users while maintaining a high resource utilization for the platform. The proposed method is validated on a public dataset and shows superior performance.
MTLight: Efficient Multi-Task Reinforcement Learning for Traffic Signal Control
Apr 01, 2024Traffic signal control has a great impact on alleviating traffic congestion in modern cities. Deep reinforcement learning (RL) has been widely used for this task in recent years, demonstrating promising performance but also facing many challenges such as limited performances and sample inefficiency. To handle these challenges, MTLight is proposed to enhance the agent observation with a latent state, which is learned from numerous traffic indicators. Meanwhile, multiple auxiliary and supervisory tasks are constructed to learn the latent state, and two types of embedding latent features, the task-specific feature and task-shared feature, are used to make the latent state more abundant. Extensive experiments conducted on CityFlow demonstrate that MTLight has leading convergence speed and asymptotic performance. We further simulate under peak-hour pattern in all scenarios with increasing control difficulty and the results indicate that MTLight is highly adaptable.
Enhance Reasoning for Large Language Models in the Game Werewolf
Feb 04, 2024This paper presents an innovative framework that integrates Large Language Models (LLMs) with an external Thinker module to enhance the reasoning capabilities of LLM-based agents. Unlike augmenting LLMs with prompt engineering, Thinker directly harnesses knowledge from databases and employs various optimization techniques. The framework forms a reasoning hierarchy where LLMs handle intuitive System-1 tasks such as natural language processing, while the Thinker focuses on cognitive System-2 tasks that require complex logical analysis and domain-specific knowledge. Our framework is presented using a 9-player Werewolf game that demands dual-system reasoning. We introduce a communication protocol between LLMs and the Thinker, and train the Thinker using data from 18800 human sessions and reinforcement learning. Experiments demonstrate the framework's effectiveness in deductive reasoning, speech generation, and online game evaluation. Additionally, we fine-tune a 6B LLM to surpass GPT4 when integrated with the Thinker. This paper also contributes the largest dataset for social deduction games to date.
Multi-Agent Sequential Decision-Making via Communication
Sep 26, 2022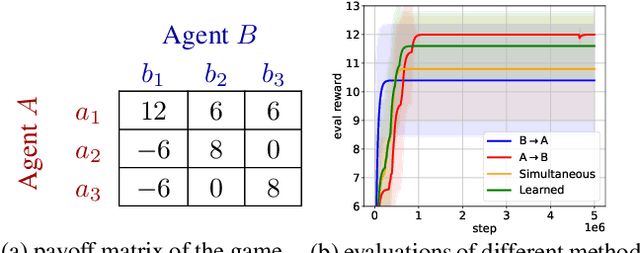

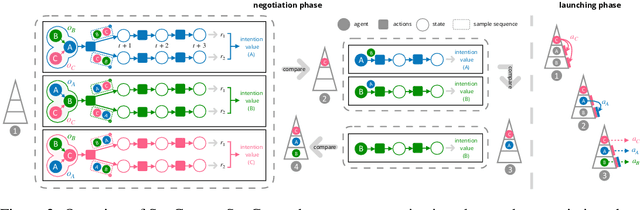

Communication helps agents to obtain information about others so that better coordinated behavior can be learned. Some existing work communicates predicted future trajectory with others, hoping to get clues about what others would do for better coordination. However, circular dependencies sometimes can occur when agents are treated synchronously so it is hard to coordinate decision-making. In this paper, we propose a novel communication scheme, Sequential Communication (SeqComm). SeqComm treats agents asynchronously (the upper-level agents make decisions before the lower-level ones) and has two communication phases. In negotiation phase, agents determine the priority of decision-making by communicating hidden states of observations and comparing the value of intention, which is obtained by modeling the environment dynamics. In launching phase, the upper-level agents take the lead in making decisions and communicate their actions with the lower-level agents. Theoretically, we prove the policies learned by SeqComm are guaranteed to improve monotonically and converge. Empirically, we show that SeqComm outperforms existing methods in various multi-agent cooperative tasks.
Variationally and Intrinsically motivated reinforcement learning for decentralized traffic signal control
Jan 20, 2021



One of the biggest challenges in multi-agent reinforcement learning is coordination, a typical application scenario of this is traffic signal control. Recently, it has attracted a rising number of researchers and has become a hot research field with great practical significance. In this paper, we propose a novel method called MetaVRS~(Meta Variational RewardShaping) for traffic signal coordination control. By heuristically applying the intrinsic reward to the environmental reward, MetaVRS can wisely capture the agent-to-agent interplay. Besides, latent variables generated by VAE are brought into policy for automatically tradeoff between exploration and exploitation to optimize the policy. In addition, meta learning was used in decoder for faster adaptation and better approximation. Empirically, we demonstate that MetaVRS substantially outperforms existing methods and shows superior adaptability, which predictably has a far-reaching significance to the multi-agent traffic signal coordination control.