 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Performance Profiling of Large Language Models
May 28, 2026Large language models (LLMs) frequently achieve impressive scores on standardized benchmarks, yet accuracy alone offers a limited view of their capabilities. Evaluating open-source LLMs through leaderboards faces persistent issues like data contamination, narrow task scope, and weak alignment with real-world reliability. Benchmark-based evaluations such as MMLU PRO, BBH, or IFEval primarily capture \textit{what} a model outputs on fixed test sets, not \textit{how} it processes information, calibrates uncertainty, or structures internal knowledge. In this article, we advocate for a shift from benchmark-centric evaluation toward a complementary, \textit{state-centered intrinsic assessment} of LLMs. To this end, we introduce \textbf{Latent Performance Profiling (LPP)} -- a framework that derives task-agnostic diagnostics from hidden activations and output distributions. LPP defines a set of scalar metrics on a model's latent representations and dynamics, revealing scale-independent traits that enable interpretable comparisons and uncover hidden vulnerabilities. Unlike static accuracy scores, LPP provides stable, architecture-sensitive signatures across models of similar size. With extensive empirical analyses across eight LLMs, spanning a size range of 0.5B-14B, we demonstrate that models with similar benchmark scores can exhibit contrasting latent profiles, such as differences in entropy or adaptability. Guided by these insights, we design synthetic probes for uncertainty and symbolic reasoning that align with intrinsic metrics while decoupling from leaderboard bias. We recommend that reporting LPP alongside benchmarks provides a deeper, interpretable understanding of model behavior, enabling more reliable model selection, safety assessment, and evaluation beyond surface-level accuracy.
Towards an Action-Centric Ontology for Cooking Procedures Using Temporal Graphs
Sep 04, 2025Formalizing cooking procedures remains a challenging task due to their inherent complexity and ambiguity. We introduce an extensible domain-specific language for representing recipes as directed action graphs, capturing processes, transfers, environments, concurrency, and compositional structure. Our approach enables precise, modular modeling of complex culinary workflows. Initial manual evaluation on a full English breakfast recipe demonstrates the DSL's expressiveness and suitability for future automated recipe analysis and execution. This work represents initial steps towards an action-centric ontology for cooking, using temporal graphs to enable structured machine understanding, precise interpretation, and scalable automation of culinary processes - both in home kitchens and professional culinary settings.
Enhancing FKG.in: automating Indian food composition analysis
Dec 09, 2024


This paper presents a novel approach to compute food composition data for Indian recipes using a knowledge graph for Indian food (FKG.in) and LLMs. The primary focus is to provide a broad overview of an automated food composition analysis workflow and describe its core functionalities: nutrition data aggregation, food composition analysis, and LLM-augmented information resolution. This workflow aims to complement FKG.in and iteratively supplement food composition data from verified knowledge bases. Additionally, this paper highlights the challenges of representing Indian food and accessing food composition data digitally. It also reviews three key sources of food composition data: the Indian Food Composition Tables, the Indian Nutrient Databank, and the Nutritionix API. Furthermore, it briefly outlines how users can interact with the workflow to obtain diet-based health recommendations and detailed food composition information for numerous recipes. We then explore the complex challenges of analyzing Indian recipe information across dimensions such as structure, multilingualism, and uncertainty as well as present our ongoing work on LLM-based solutions to address these issues. The methods proposed in this workshop paper for AI-driven knowledge curation and information resolution are application-agnostic, generalizable, and replicable for any domain.
Building FKG.in: a Knowledge Graph for Indian Food
Sep 01, 2024


This paper presents an ontology design along with knowledge engineering, and multilingual semantic reasoning techniques to build an automated system for assimilating culinary information for Indian food in the form of a knowledge graph. The main focus is on designing intelligent methods to derive ontology designs and capture all-encompassing knowledge about food, recipes, ingredients, cooking characteristics, and most importantly, nutrition, at scale. We present our ongoing work in this workshop paper, describe in some detail the relevant challenges in curating knowledge of Indian food, and propose our high-level ontology design. We also present a novel workflow that uses AI, LLM, and language technology to curate information from recipe blog sites in the public domain to build knowledge graphs for Indian food. The methods for knowledge curation proposed in this paper are generic and can be replicated for any domain. The design is application-agnostic and can be used for AI-driven smart analysis, building recommendation systems for Personalized Digital Health, and complementing the knowledge graph for Indian food with contextual information such as user information, food biochemistry, geographic information, agricultural information, etc.
Mapping Patient Trajectories: Understanding and Visualizing Sepsis Prognostic Pathways from Patients Clinical Narratives
Jul 20, 2024



In recent years, healthcare professionals are increasingly emphasizing on personalized and evidence-based patient care through the exploration of prognostic pathways. To study this, structured clinical variables from Electronic Health Records (EHRs) data have traditionally been employed by many researchers. Presently, Natural Language Processing models have received great attention in clinical research which expanded the possibilities of using clinical narratives. In this paper, we propose a systematic methodology for developing sepsis prognostic pathways derived from clinical notes, focusing on diverse patient subgroups identified by exploring comorbidities associated with sepsis and generating explanations of these subgroups using SHAP. The extracted prognostic pathways of these subgroups provide valuable insights into the dynamic trajectories of sepsis severity over time. Visualizing these pathways sheds light on the likelihood and direction of disease progression across various contexts and reveals patterns and pivotal factors or biomarkers influencing the transition between sepsis stages, whether toward deterioration or improvement. This empowers healthcare providers to implement more personalized and effective healthcare strategies for individual patients.
Identification, Tracking and Impact: Understanding the trade secret of catchphrases
Jul 20, 2020

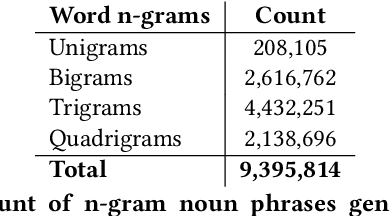
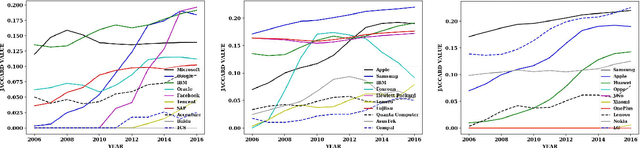
Understanding the topical evolution in industrial innovation is a challenging problem. With the advancement in the digital repositories in the form of patent documents, it is becoming increasingly more feasible to understand the innovation secrets -- "catchphrases" of organizations. However, searching and understanding this enormous textual information is a natural bottleneck. In this paper, we propose an unsupervised method for the extraction of catchphrases from the abstracts of patents granted by the U.S. Patent and Trademark Office over the years. Our proposed system achieves substantial improvement, both in terms of precision and recall, against state-of-the-art techniques. As a second objective, we conduct an extensive empirical study to understand the temporal evolution of the catchphrases across various organizations. We also show how the overall innovation evolution in the form of introduction of newer catchphrases in an organization's patents correlates with the future citations received by the patents filed by that organization. Our code and data sets will be placed in the public domain soon.
Multi-Document Summarization using Distributed Bag-of-Words Model
Jun 11, 2018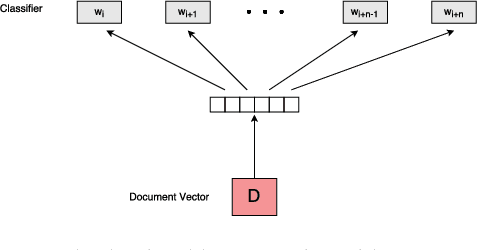

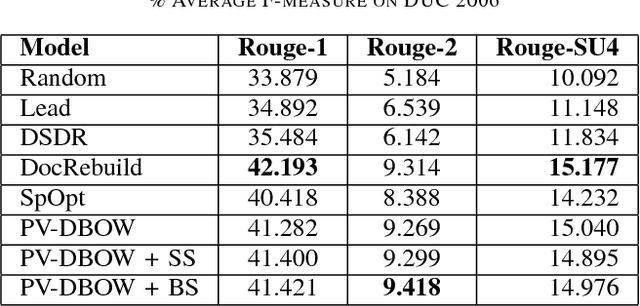
As the number of documents on the web is growing exponentially, multi-document summarization is becoming more and more important since it can provide the main ideas in a document set in short time. In this paper, we present an unsupervised centroid-based document-level reconstruction framework using distributed bag of words model. Specifically, our approach selects summary sentences in order to minimize the reconstruction error between the summary and the documents. We apply sentence selection and beam search, to further improve the performance of our model. Experimental results on two different datasets show significant performance gains compared with the state-of-the-art baselines.
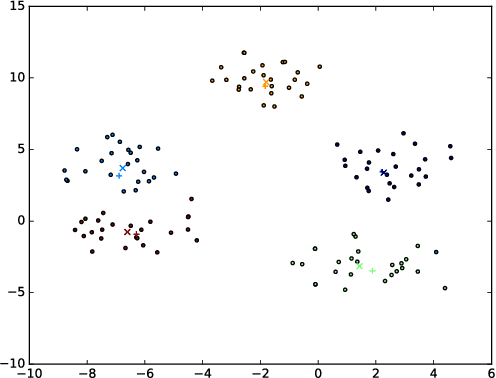
A Machine Learning Approach to Quantitative Prosopography
Jan 30, 2018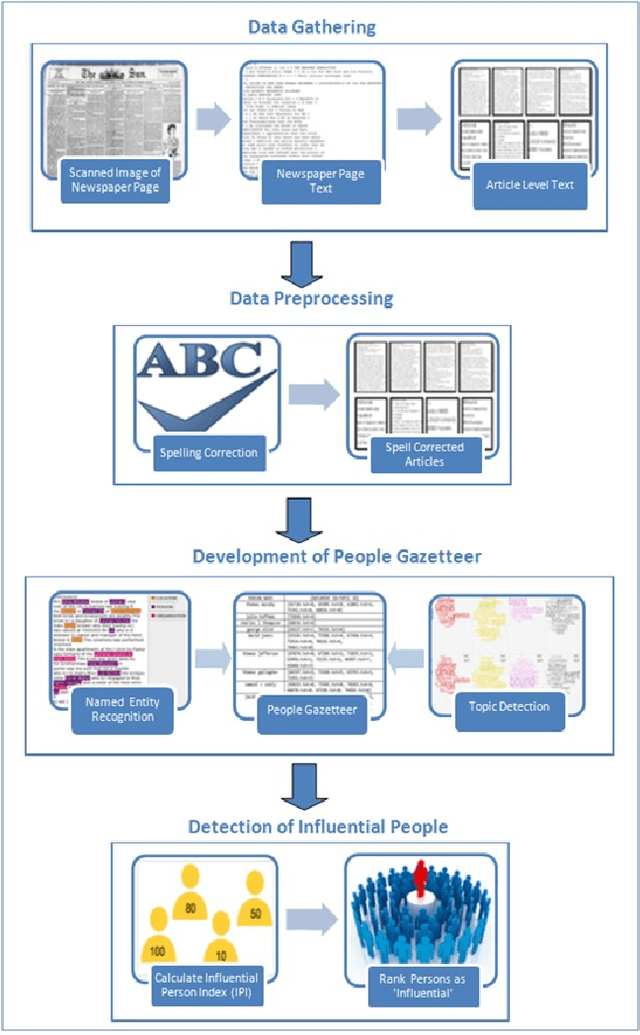


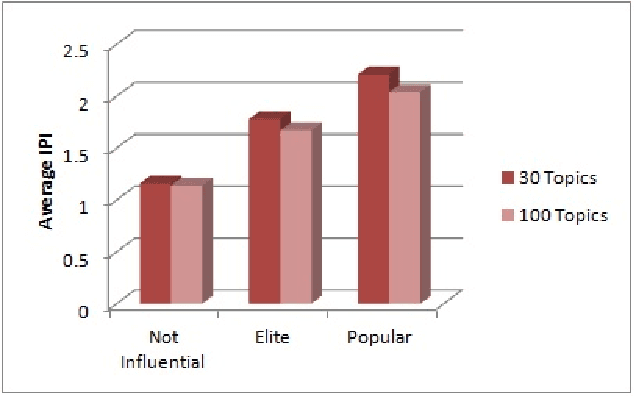
Prosopography is an investigation of the common characteristics of a group of people in history, by a collective study of their lives. It involves a study of biographies to solve historical problems. If such biographies are unavailable, surviving documents and secondary biographical data are used. Quantitative prosopography involves analysis of information from a wide variety of sources about "ordinary people". In this paper, we present a machine learning framework for automatically designing a people gazetteer which forms the basis of quantitative prosopographical research. The gazetteer is learnt from the noisy text of newspapers using a Named Entity Recognizer (NER). It is capable of identifying influential people from it by making use of a custom designed Influential Person Index (IPI). Our corpus comprises of 14020 articles from a local newspaper, "The Sun", published from New York in 1896. Some influential people identified by our algorithm include Captain Donald Hankey (an English soldier), Dame Nellie Melba (an Australian operatic soprano), Hugh Allan (a Canadian shipping magnate) and Sir Hugh John McDonald (the first Prime Minister of Canada).