 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Question Generation with Reinforcement Learning Based Graph-to-Sequence Model
Oct 19, 2019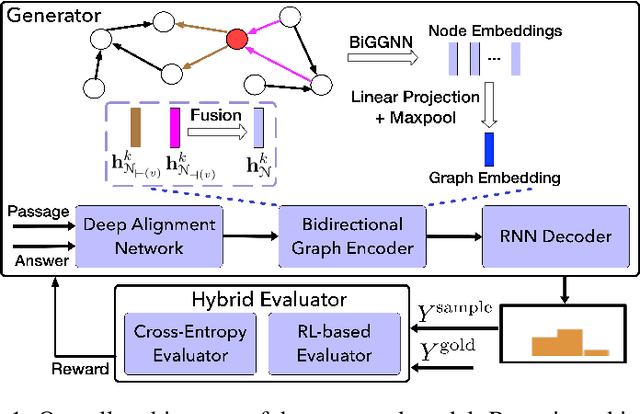
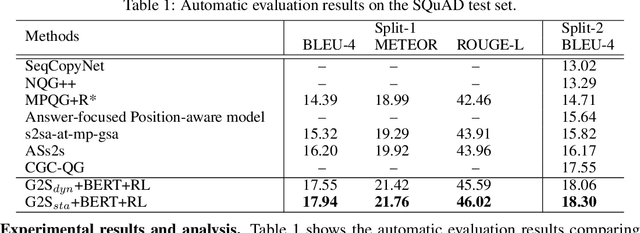
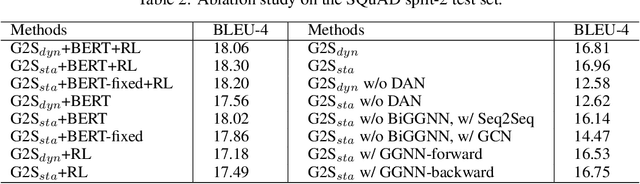
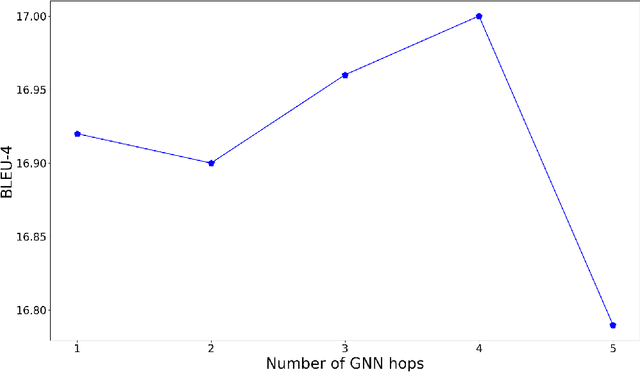
Natural question generation (QG) aims to generate questions from a passage and an answer. In this paper, we propose a novel reinforcement learning (RL) based graph-to-sequence (Graph2Seq) model for QG. Our model consists of a Graph2Seq generator where a novel Bidirectional Gated Graph Neural Network is proposed to embed the passage, and a hybrid evaluator with a mixed objective combining both cross-entropy and RL losses to ensure the generation of syntactically and semantically valid text. The proposed model outperforms previous state-of-the-art methods by a large margin on the SQuAD dataset.
MUTLA: A Large-Scale Dataset for Multimodal Teaching and Learning Analytics
Oct 05, 2019


Automatic analysis of teacher and student interactions could be very important to improve the quality of teaching and student engagement. However, despite some recent progress in utilizing multimodal data for teaching and learning analytics, a thorough analysis of a rich multimodal dataset coming for a complex real learning environment has yet to be done. To bridge this gap, we present a large-scale MUlti-modal Teaching and Learning Analytics (MUTLA) dataset. This dataset includes time-synchronized multimodal data records of students (learning logs, videos, EEG brainwaves) as they work in various subjects from Squirrel AI Learning System (SAIL) to solve problems of varying difficulty levels. The dataset resources include user records from the learner records store of SAIL, brainwave data collected by EEG headset devices, and video data captured by web cameras while students worked in the SAIL products. Our hope is that by analyzing real-world student learning activities, facial expressions, and brainwave patterns, researchers can better predict engagement, which can then be used to improve adaptive learning selection and student learning outcomes. An additional goal is to provide a dataset gathered from real-world educational activities versus those from controlled lab environments to benefit the educational learning community.
Multi-stage Deep Classifier Cascades for Open World Recognition
Aug 26, 2019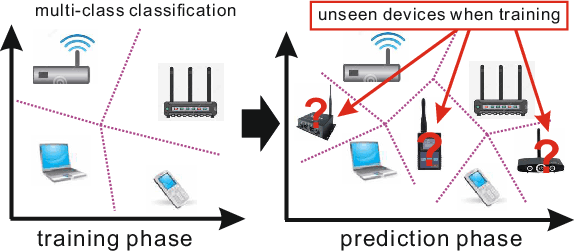

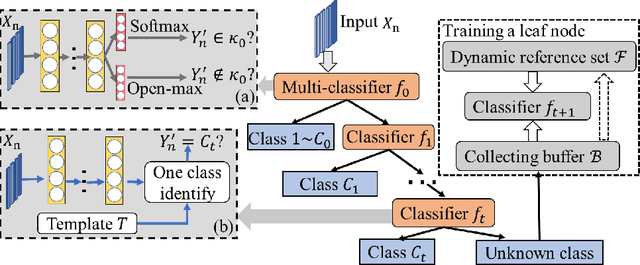

At present, object recognition studies are mostly conducted in a closed lab setting with classes in test phase typically in training phase. However, real-world problem is far more challenging because: i) new classes unseen in the training phase can appear when predicting; ii) discriminative features need to evolve when new classes emerge in real time; and iii) instances in new classes may not follow the "independent and identically distributed" (iid) assumption. Most existing work only aims to detect the unknown classes and is incapable of continuing to learn newer classes. Although a few methods consider both detecting and including new classes, all are based on the predefined handcrafted features that cannot evolve and are out-of-date for characterizing emerging classes. Thus, to address the above challenges, we propose a novel generic end-to-end framework consisting of a dynamic cascade of classifiers that incrementally learn their dynamic and inherent features. The proposed method injects dynamic elements into the system by detecting instances from unknown classes, while at the same time incrementally updating the model to include the new classes. The resulting cascade tree grows by adding a new leaf node classifier once a new class is detected, and the discriminative features are updated via an end-to-end learning strategy. Experiments on two real-world datasets demonstrate that our proposed method outperforms existing state-of-the-art methods.
DynGraph2Seq: Dynamic-Graph-to-Sequence Interpretable Learning for Health Stage Prediction in Online Health Forums
Aug 22, 2019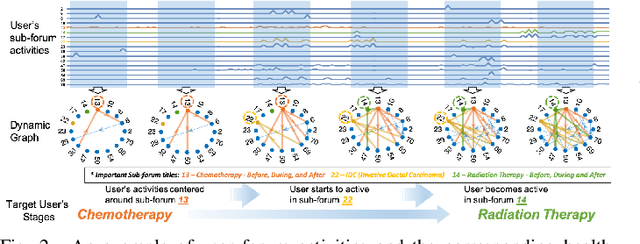
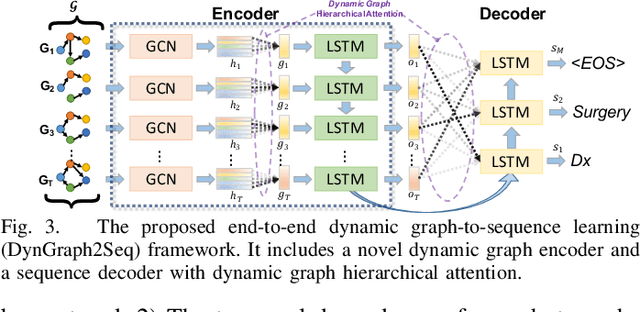
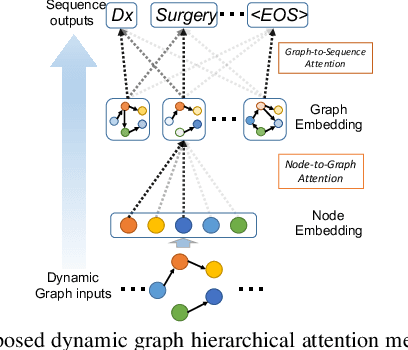
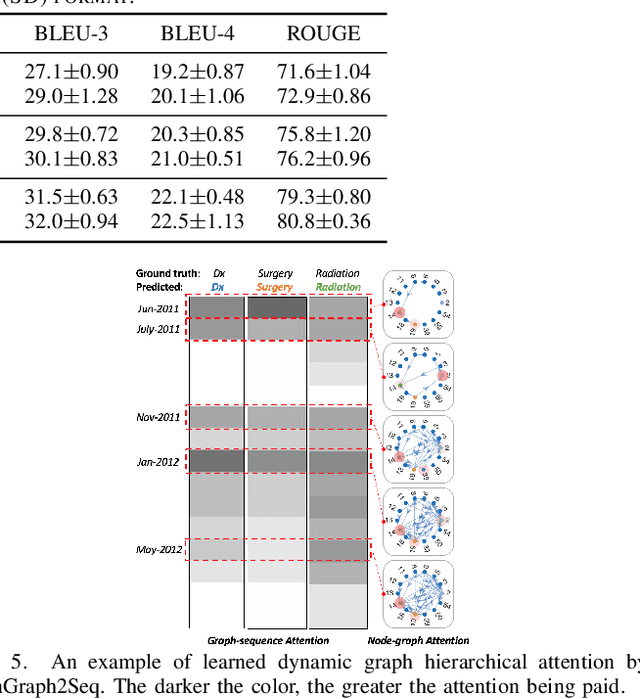
Online health communities such as the online breast cancer forum enable patients (i.e., users) to interact and help each other within various subforums, which are subsections of the main forum devoted to specific health topics. The changing nature of the users' activities in different subforums can be strong indicators of their health status changes. This additional information could allow health-care organizations to respond promptly and provide additional help for the patient. However, modeling complex transitions of an individual user's activities among different subforums over time and learning how these correspond to his/her health stage are extremely challenging. In this paper, we first formulate the transition of user activities as a dynamic graph with multi-attributed nodes, then formalize the health stage inference task as a dynamic graph-to-sequence learning problem, and hence propose a novel dynamic graph-to-sequence neural networks architecture (DynGraph2Seq) to address all the challenges. Our proposed DynGraph2Seq model consists of a novel dynamic graph encoder and an interpretable sequence decoder that learn the mapping between a sequence of time-evolving user activity graphs and a sequence of target health stages. We go on to propose dynamic graph hierarchical attention mechanisms to facilitate the necessary multi-level interpretability. A comprehensive experimental analysis of its use for a health stage prediction task demonstrates both the effectiveness and the interpretability of the proposed models.
Reinforcement Learning Based Graph-to-Sequence Model for Natural Question Generation
Aug 14, 2019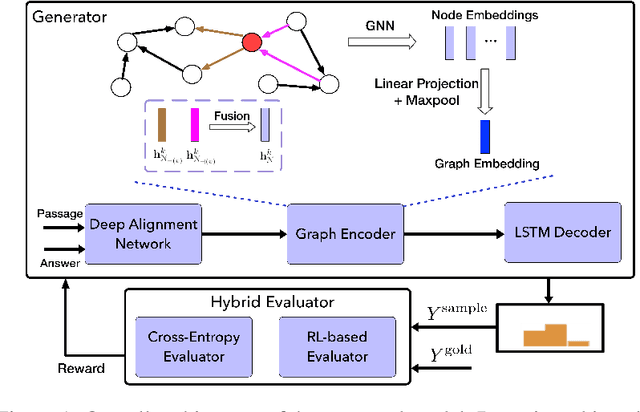
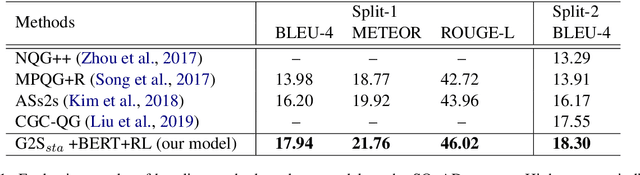

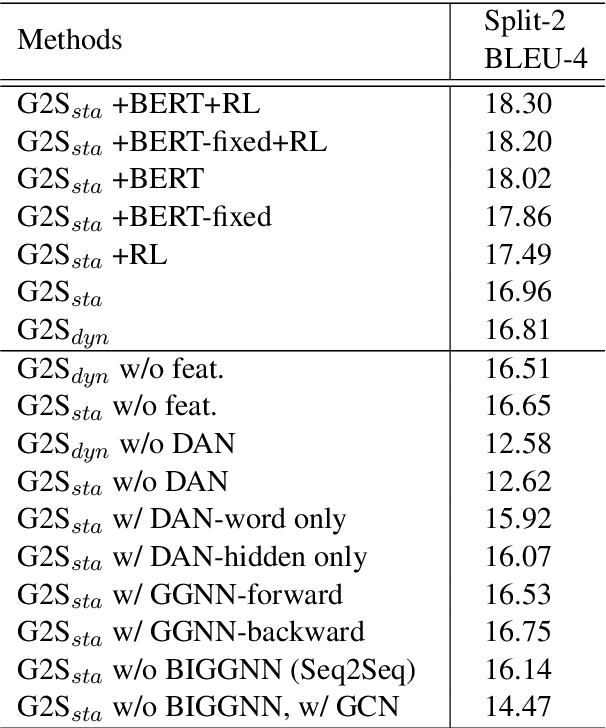
Natural question generation (QG) is a challenging yet rewarding task, that aims to generate questions given an input passage and a target answer. Previous works on QG, however, either (i) ignore the rich structure information hidden in the word sequence, (ii) fail to fully exploit the target answer, or (iii) solely rely on cross-entropy loss that leads to issues like exposure bias and evaluation discrepancy between training and testing. To address the above limitations, in this paper, we propose a reinforcement learning (RL) based graph-to-sequence (Graph2Seq) architecture for the QG task. Our model consists of a Graph2Seq generator where a novel bidirectional graph neural network (GNN) based encoder is applied to embed the input passage incorporating the answer information via a simple yet effective Deep Alignment Network, and an evaluator where a mixed objective function combining both cross-entropy loss and RL loss is designed for ensuring the generation of semantically and syntactically valid text. The proposed model is end-to-end trainable, and achieves new state-of-the-art scores and outperforms all previous methods by a great margin on the SQuAD benchmark.
GraphFlow: Exploiting Conversation Flow with Graph Neural Networks for Conversational Machine Comprehension
Jul 31, 2019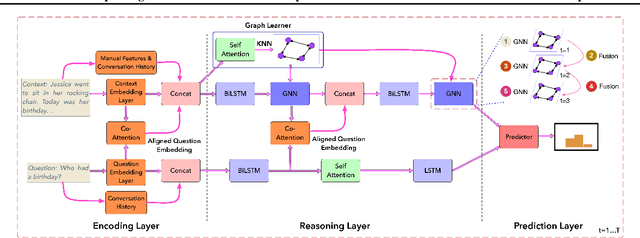
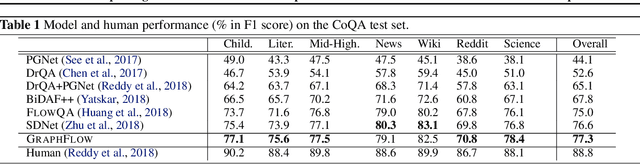
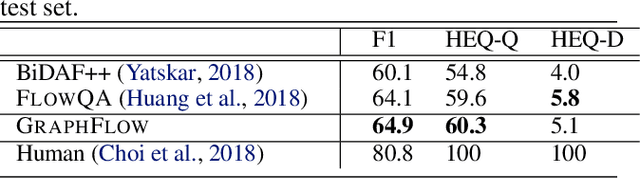
Conversational machine reading comprehension (MRC) has proven significantly more challenging compared to traditional MRC since it requires better utilization of conversation history. However, most existing approaches do not effectively capture conversation history and thus have trouble handling questions involving coreference or ellipsis. We propose a novel graph neural network (GNN) based model, namely GraphFlow, which captures conversational flow in the dialog. Specifically, we first propose a new approach to dynamically construct a question-aware context graph from passage text at each turn. We then present a novel flow mechanism to model the temporal dependencies in the sequence of context graphs. The proposed GraphFlow model shows superior performance compared to existing state-of-the-art methods. For instance, GraphFlow outperforms two recently proposed models on the CoQA benchmark dataset: FlowQA by 2.3% and SDNet by 0.7% on F1 score, respectively. In addition, visualization experiments show that our proposed model can better mimic the human reasoning process for conversational MRC compared to existing models.
Attacking Graph Convolutional Networks via Rewiring
Jun 10, 2019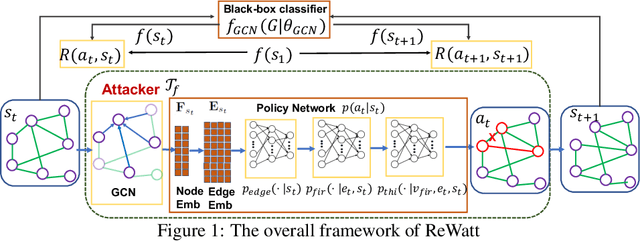
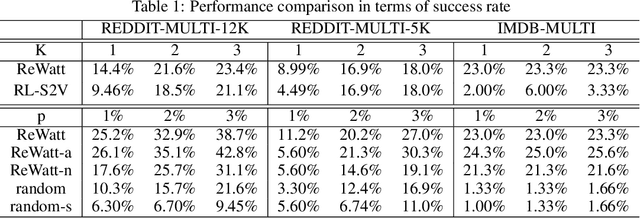
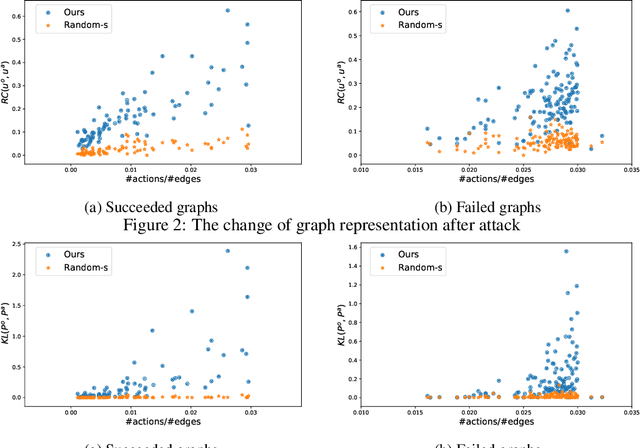
Graph Neural Networks (GNNs) have boosted the performance of many graph related tasks such as node classification and graph classification. Recent researches show that graph neural networks are vulnerable to adversarial attacks, which deliberately add carefully created unnoticeable perturbation to the graph structure. The perturbation is usually created by adding/deleting a few edges, which might be noticeable even when the number of edges modified is small. In this paper, we propose a graph rewiring operation which affects the graph in a less noticeable way compared to adding/deleting edges. We then use reinforcement learning to learn the attack strategy based on the proposed rewiring operation. Experiments on real world graphs demonstrate the effectiveness of the proposed framework. To understand the proposed framework, we further analyze how its generated perturbation to the graph structure affects the output of the target model.
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
Apr 08, 2019
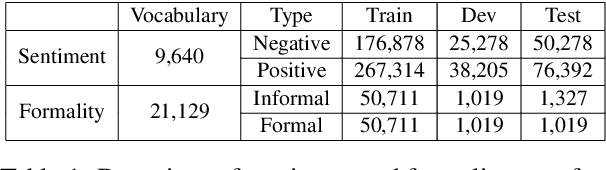
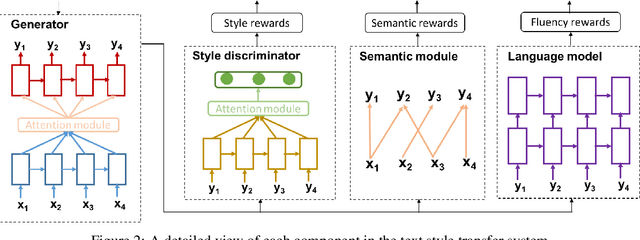

Text style transfer rephrases a text from a source style (e.g., informal) to a target style (e.g., formal) while keeping its original meaning. Despite the success existing works have achieved using a parallel corpus for the two styles, transferring text style has proven significantly more challenging when there is no parallel training corpus. In this paper, we address this challenge by using a reinforcement-learning-based generator-evaluator architecture. Our generator employs an attention-based encoder-decoder to transfer a sentence from the source style to the target style. Our evaluator is an adversarially trained style discriminator with semantic and syntactic constraints that score the generated sentence for style, meaning preservation, and fluency. Experimental results on two different style transfer tasks (sentiment transfer and formality transfer) show that our model outperforms state-of-the-art approaches. Furthermore, we perform a manual evaluation that demonstrates the effectiveness of the proposed method using subjective metrics of generated text quality.
Bidirectional Attentive Memory Networks for Question Answering over Knowledge Bases
Apr 04, 2019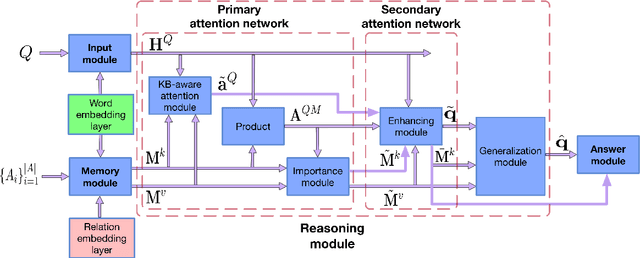
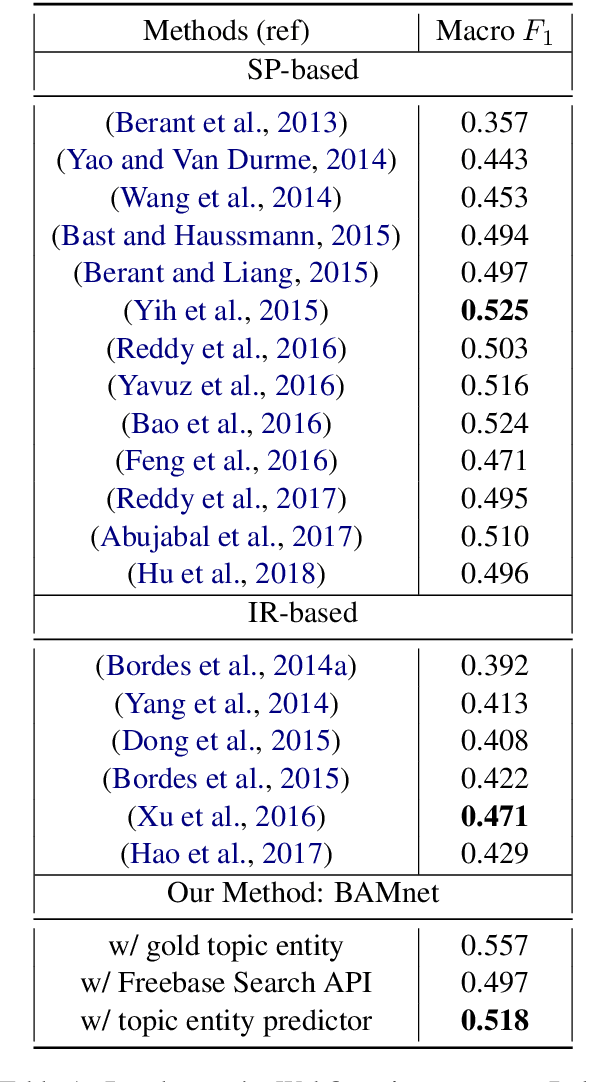
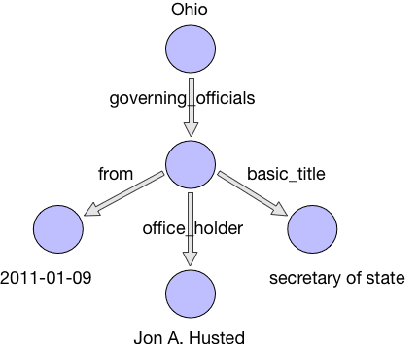
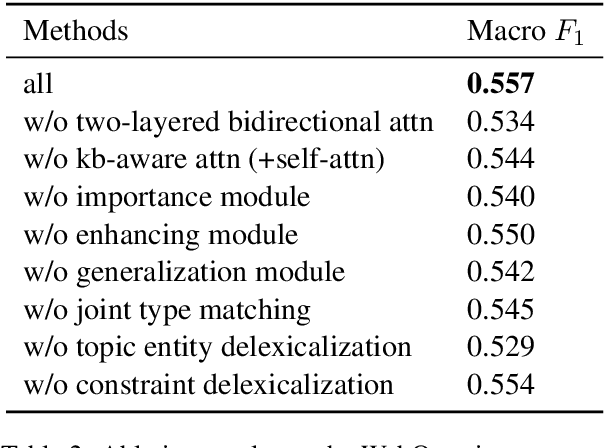
When answering natural language questions over knowledge bases (KBs), different question components and KB aspects play different roles. However, most existing embedding-based methods for knowledge base question answering (KBQA) ignore the subtle inter-relationships between the question and the KB (e.g., entity types, relation paths and context). In this work, we propose to directly model the two-way flow of interactions between the questions and the KB via a novel Bidirectional Attentive Memory Network, called BAMnet. Requiring no external resources and only very few hand-crafted features, on the WebQuestions benchmark, our method significantly outperforms existing information-retrieval based methods, and remains competitive with (hand-crafted) semantic parsing based methods. Also, since we use attention mechanisms, our method offers better interpretability compared to other baselines.
High-Fidelity Vector Space Models of Structured Data
Jan 15, 2019

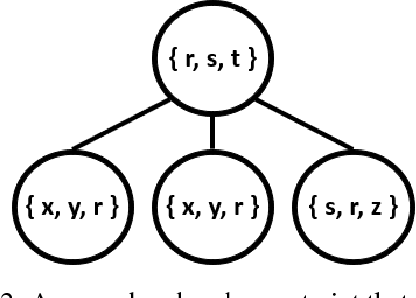
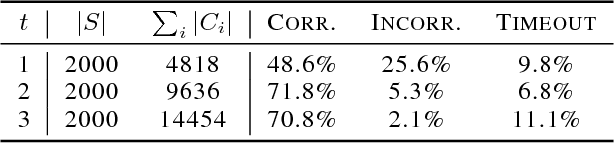
Machine learning systems regularly deal with structured data in real-world applications. Unfortunately, such data has been difficult to faithfully represent in a way that most machine learning techniques would expect, i.e. as a real-valued vector of a fixed, pre-specified size. In this work, we introduce a novel approach that compiles structured data into a satisfiability problem which has in its set of solutions at least (and often only) the input data. The satisfiability problem is constructed from constraints which are generated automatically a priori from a given signature, thus trivially allowing for a bag-of-words-esque vector representation of the input to be constructed. The method is demonstrated in two areas, automated reasoning and natural language processing, where it is shown to produce vector representations of natural-language sentences and first-order logic clauses that can be precisely translated back to their original, structured input forms.