 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: A Structure and Texture Aware Retinex Model
Jun 30, 2019



Retinex theory is developed mainly to decompose an image into the illumination and reflectance components by analyzing local image derivatives. In this theory, larger derivatives are attributed to the changes in piece-wise constant reflectance, while smaller derivatives are emerged in the smooth illumination. In this paper, we propose to utilize the exponentiated derivatives (with an exponent $\gamma$) of an observed image to generate a structure map when being amplified with $\gamma>1$ and a texture map when being shrank with $\gamma<1$. To this end, we design exponential filters for the local derivatives, and present their capability on extracting accurate structure and texture maps, influenced by the choices of exponents $\gamma$ on the local derivatives. The extracted structure and texture maps are employed to regularize the illumination and reflectance components in Retinex decomposition. A novel Structure and Texture Aware Retinex (STAR) model is further proposed for illumination and reflectance decomposition of a single image. We solve the STAR model in an alternating minimization manner. Each sub-problem is transformed into a vectorized least squares regression with closed-form solution. Comprehensive experiments demonstrate that, the proposed STAR model produce better quantitative and qualitative performance than previous competing methods, on illumination and reflectance estimation, low-light image enhancement, and color correction. The code will be publicly released.
Human vs Machine Attention in Neural Networks: A Comparative Study
Jun 24, 2019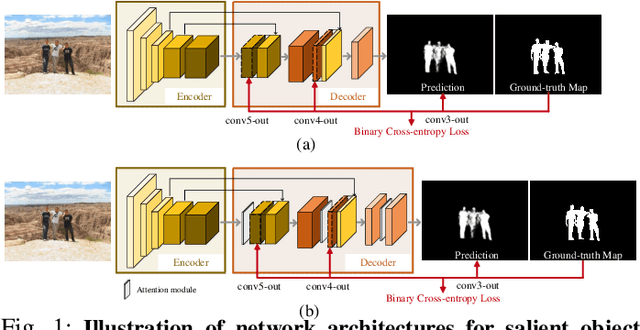
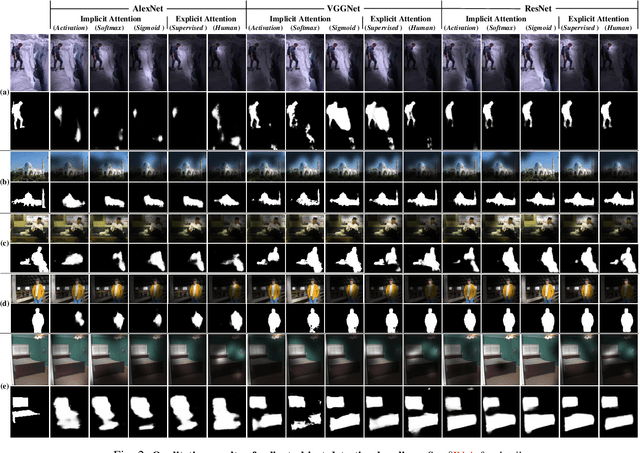
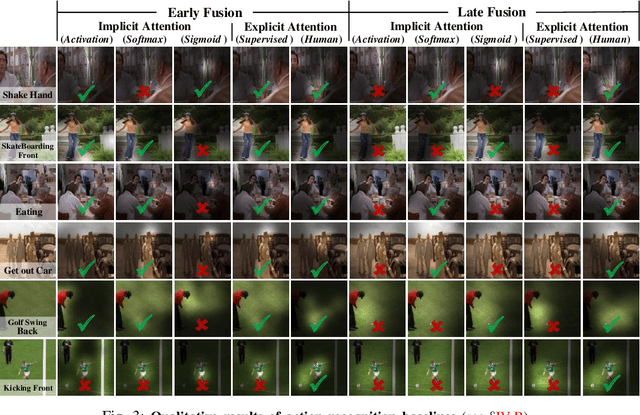
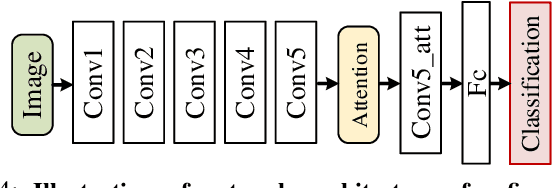
Recent years have witnessed a surge in the popularity of attention mechanisms encoded within deep neural networks. Inspired by the selective attention in the visual cortex, artificial attention is designed to focus a neural network on the most task-relevant input signal. Many works claim that the attention mechanism offers an extra dimension of interpretability by explaining where the neural networks look. However, recent studies demonstrate that artificial attention maps do not always coincide with common intuition. In view of these conflicting evidences, here we make a systematic study on using artificial attention and human attention in neural network design. With three example computer vision tasks (i.e., salient object segmentation, video action recognition, and fine-grained image classification), diverse representative network backbones (i.e., AlexNet, VGGNet, ResNet) and famous architectures (i.e., Two-stream, FCN), corresponding real human gaze data, and systematically conducted large-scale quantitative studies, we offer novel insights into existing artificial attention mechanisms and give preliminary answers to several key questions related to human and artificial attention mechanisms. Our overall results demonstrate that human attention is capable of bench-marking the meaningful `ground-truth' in attention-driven tasks, where the more the artificial attention is close to the human attention, the better the performance; for higher-level vision tasks, it is case-by-case. We believe it would be advisable for attention-driven tasks to explicitly force a better alignment between artificial and human attentions to boost the performance; such alignment would also benefit making the deep networks more transparent and explainable for higher-level computer vision tasks.
Dynamic Distribution Pruning for Efficient Network Architecture Search
Jun 09, 2019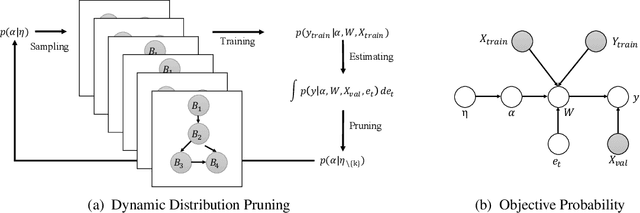
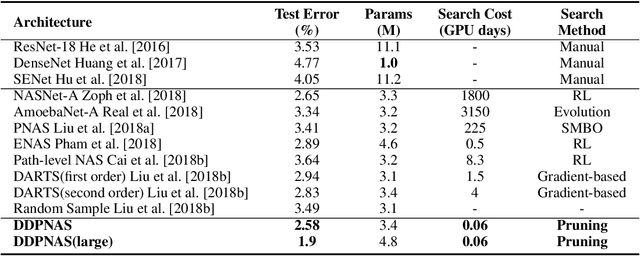
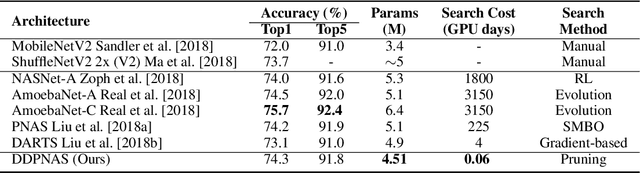
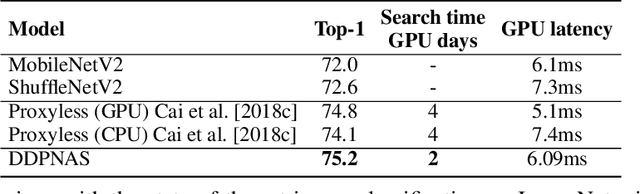
Network architectures obtained by Neural Architecture Search (NAS) have shown state-of-the-art performance in various computer vision tasks. Despite the exciting progress, the computational complexity of the forward-backward propagation and the search process makes it difficult to apply NAS in practice. In particular, most previous methods require thousands of GPU days for the search process to converge. In this paper, we propose a dynamic distribution pruning method towards extremely efficient NAS, which samples architectures from a joint categorical distribution. The search space is dynamically pruned every a few epochs to update this distribution, and the optimal neural architecture is obtained when there is only one structure remained. We conduct experiments on two widely-used datasets in NAS. On CIFAR-10, the optimal structure obtained by our method achieves the state-of-the-art $1.9$\% test error, while the search process is more than $1,000$ times faster (only $1.5$ GPU hours on a Tesla V100) than the state-of-the-art NAS algorithms. On ImageNet, our model achieves 75.2\% top-1 accuracy under the MobileNet settings, with a time cost of only $2$ GPU days that is $100\%$ acceleration over the fastest NAS algorithm. The code is available at \url{ https://github.com/tanglang96/DDPNAS}
Extreme Points Derived Confidence Map as a Cue For Class-Agnostic Segmentation Using Deep Neural Network
Jun 06, 2019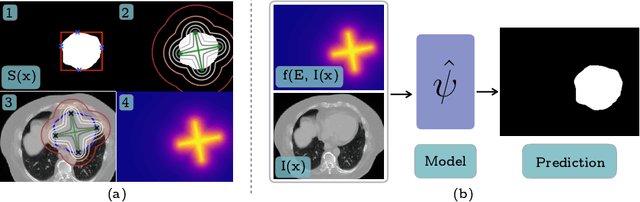
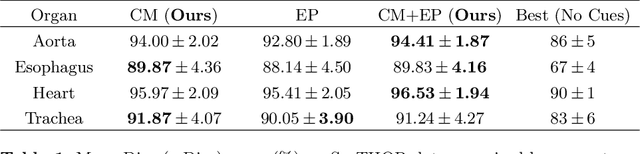
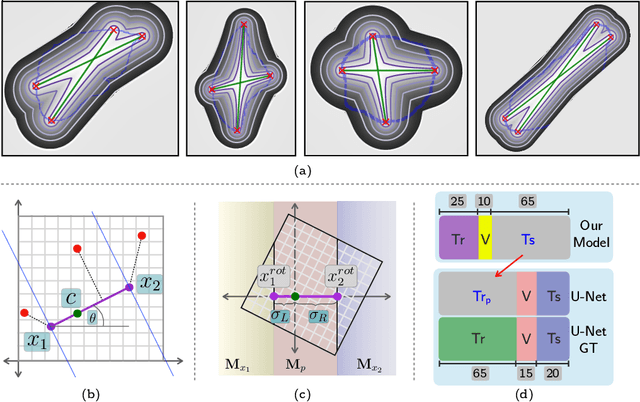
To automate the process of segmenting an anatomy of interest, we can learn a model from previously annotated data. The learning-based approach uses annotations to train a model that tries to emulate the expert labeling on a new data set. While tremendous progress has been made using such approaches, labeling of medical images remains a time-consuming and expensive task. In this paper, we evaluate the utility of extreme points in learning to segment. Specifically, we propose a novel approach to compute a confidence map from extreme points that quantitatively encodes the priors derived from extreme points. We use the confidence map as a cue to train a deep neural network based on ResNet-101 and PSP module to develop a class-agnostic segmentation model that outperforms state-of-the-art method that employs extreme points as a cue. Further, we evaluate a realistic use-case by using our model to generate training data for supervised learning (U-Net) and observed that U-Net performs comparably when trained with either the generated data or the ground truth data. These findings suggest that models trained using cues can be used to generate reliable training data.
Dynamic Neural Network Decoupling
Jun 04, 2019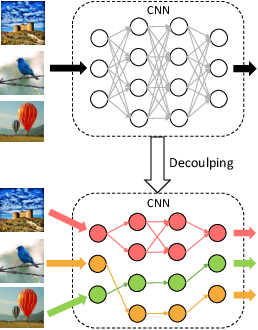
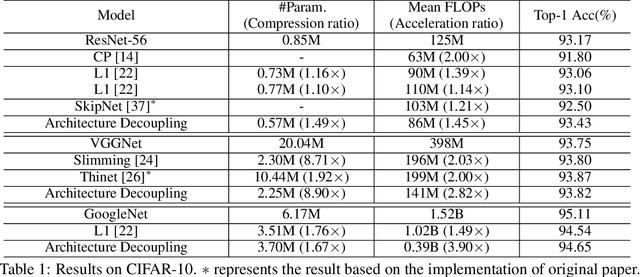
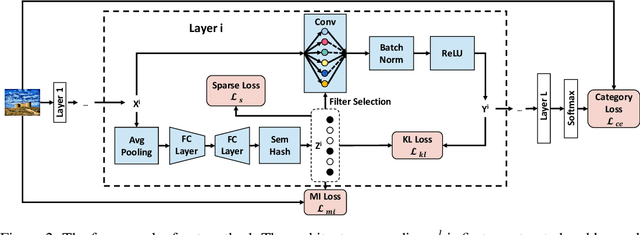
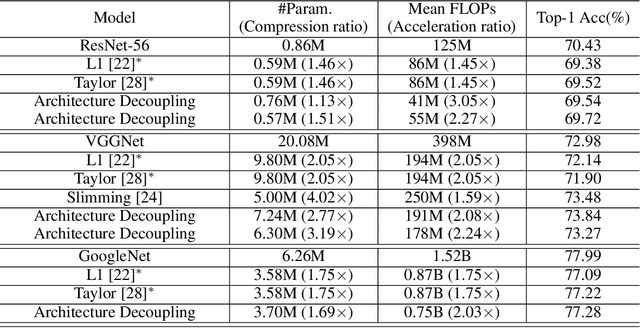
Convolutional neural networks (CNNs) have achieved a superior performance by taking advantages of the complex network architectures and huge numbers of parameters, which however become uninterpretable and challenge their full potential to practical applications. Towards better understand the rationale behind the network decisions, we propose a novel architecture decoupling method, which dynamically discovers the hierarchical path consisting of activated filters for each input image. In particular, architecture controlling module is introduced in each layer to encode the network architecture and identify the activated filters corresponding to the specific input. Then, mutual information between architecture encoding and the attribute of input image is maximized to decouple the network architecture, and subsequently disentangles the filters by limiting the outputs of filter during training. Extensive experiments show that several merits have been achieved based on the proposed architecture decoupling, i.e., interpretation, acceleration and adversarial attacking.
Random Path Selection for Incremental Learning
Jun 03, 2019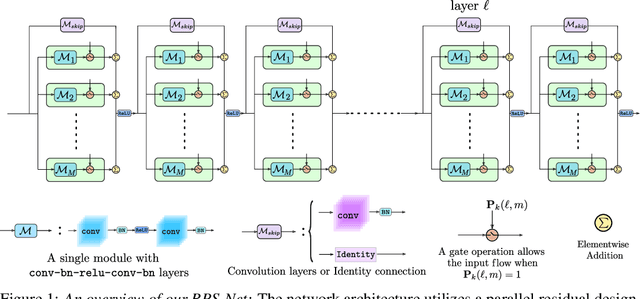
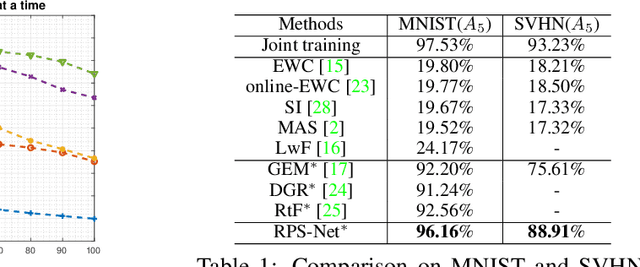
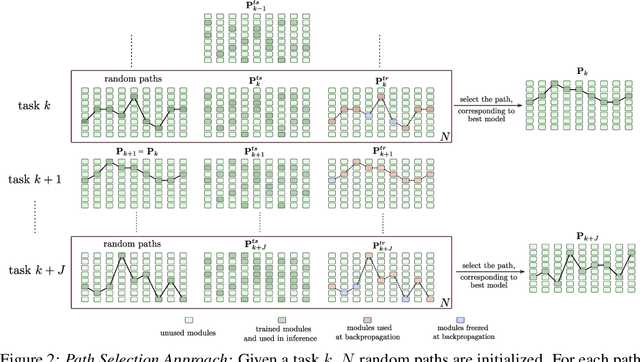
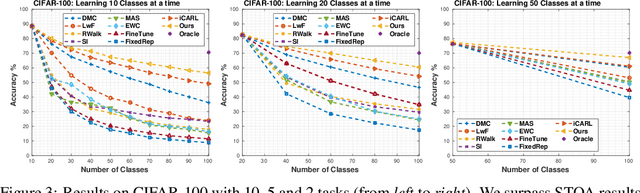
Incremental life-long learning is a main challenge towards the long-standing goal of Artificial General Intelligence. In real-life settings, learning tasks arrive in a sequence and machine learning models must continually learn to increment already acquired knowledge. Existing incremental learning approaches, fall well below the state-of-the-art cumulative models that use all training classes at once. In this paper, we propose a random path selection algorithm, called RPSnet, that progressively chooses optimal paths for the new tasks while encouraging parameter sharing and reuse. Our approach avoids the overhead introduced by computationally expensive evolutionary and reinforcement learning based path selection strategies while achieving considerable performance gains. As an added novelty, the proposed model integrates knowledge distillation and retrospection along with the path selection strategy to overcome catastrophic forgetting. In order to maintain an equilibrium between previous and newly acquired knowledge, we propose a simple controller to dynamically balance the model plasticity. Through extensive experiments, we demonstrate that the proposed method surpasses the state-of-the-art performance on incremental learning and by utilizing parallel computation this method can run in constant time with nearly the same efficiency as a conventional deep convolutional neural network.
iSAID: A Large-scale Dataset for Instance Segmentation in Aerial Images
May 30, 2019
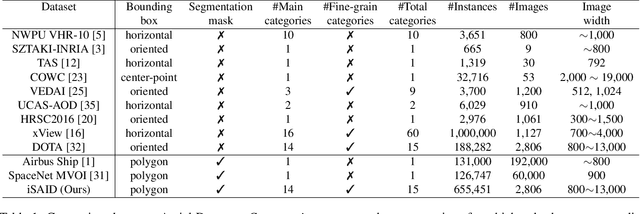
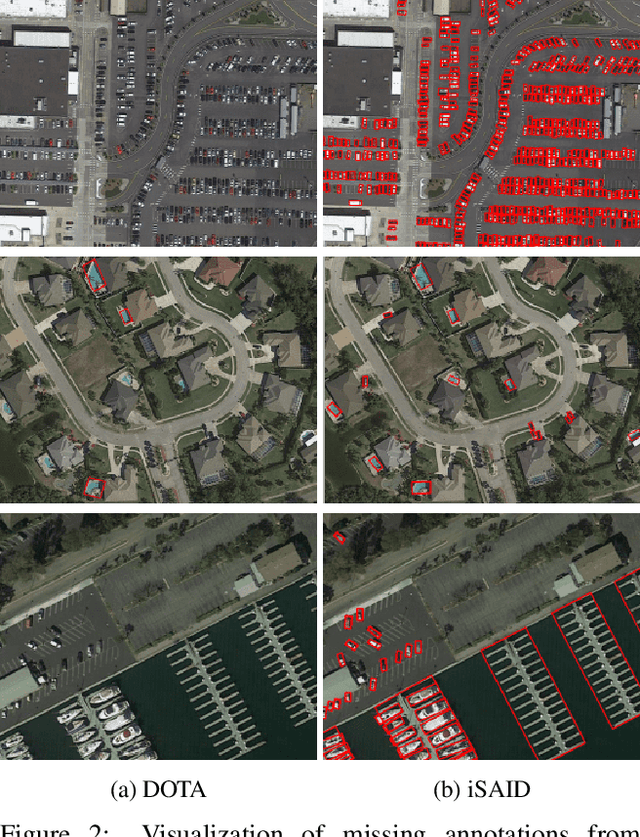
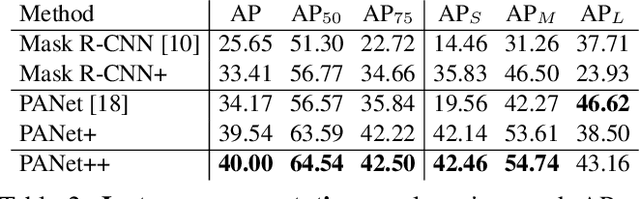
Existing Earth Vision datasets are either suitable for semantic segmentation or object detection. In this work, we introduce the first benchmark dataset for instance segmentation in aerial imagery that combines instance-level object detection and pixel-level segmentation tasks. In comparison to instance segmentation in natural scenes, aerial images present unique challenges e.g., a huge number of instances per image, large object-scale variations and abundant tiny objects. Our large-scale and densely annotated Instance Segmentation in Aerial Images Dataset (iSAID) comes with 655,451 object instances for 15 categories across 2,806 high-resolution images. Such precise per-pixel annotations for each instance ensure accurate localization that is essential for detailed scene analysis. Compared to existing small-scale aerial image based instance segmentation datasets, iSAID contains 15$\times$ the number of object categories and 5$\times$ the number of instances. We benchmark our dataset using two popular instance segmentation approaches for natural images, namely Mask R-CNN and PANet. In our experiments we show that direct application of off-the-shelf Mask R-CNN and PANet on aerial images provide suboptimal instance segmentation results, thus requiring specialized solutions from the research community.
Dynamically Visual Disambiguation of Keyword-based Image Search
May 27, 2019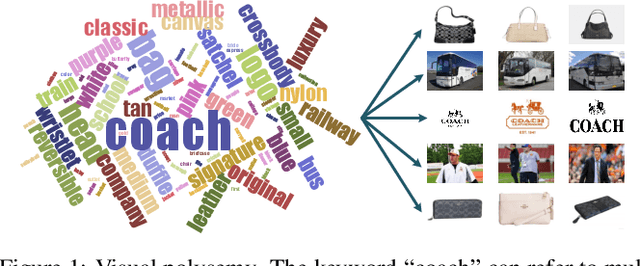
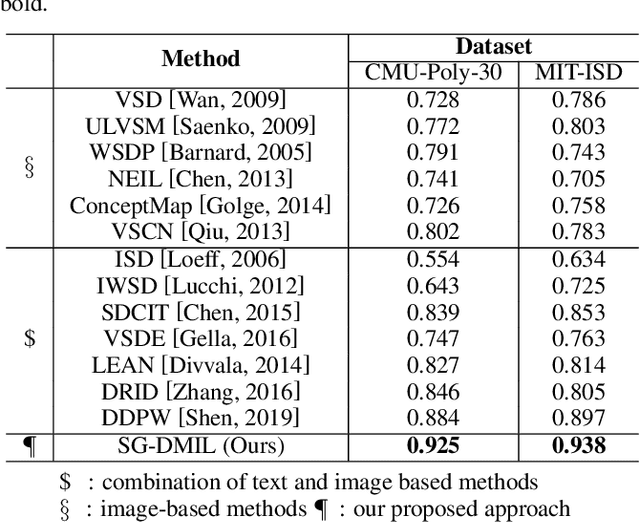
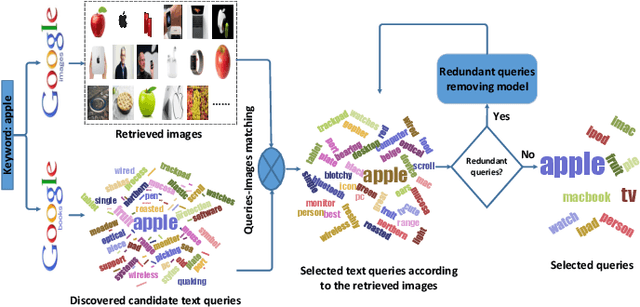
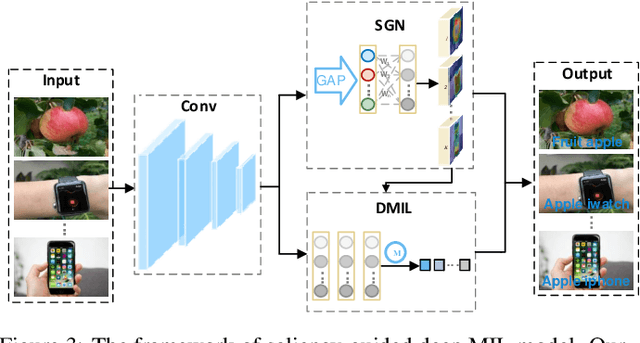
Due to the high cost of manual annotation, learning directly from the web has attracted broad attention. One issue that limits their performance is the problem of visual polysemy. To address this issue, we present an adaptive multi-model framework that resolves polysemy by visual disambiguation. Compared to existing methods, the primary advantage of our approach lies in that our approach can adapt to the dynamic changes in the search results. Our proposed framework consists of two major steps: we first discover and dynamically select the text queries according to the image search results, then we employ the proposed saliency-guided deep multi-instance learning network to remove outliers and learn classification models for visual disambiguation. Extensive experiments demonstrate the superiority of our proposed approach.
Out-of-Distribution Detection for Generalized Zero-Shot Action Recognition
May 06, 2019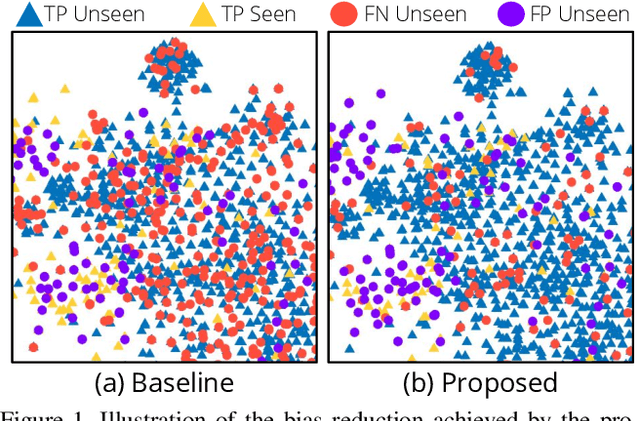
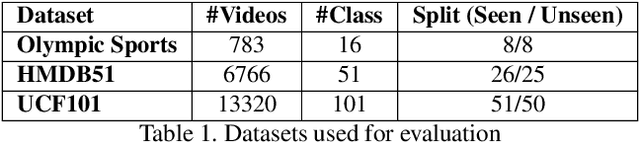
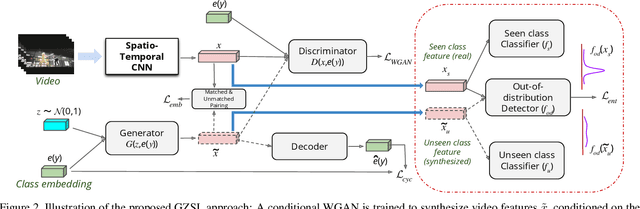
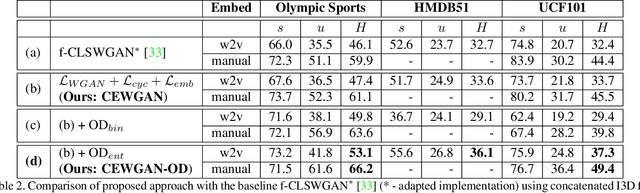
Generalized zero-shot action recognition is a challenging problem, where the task is to recognize new action categories that are unavailable during the training stage, in addition to the seen action categories. Existing approaches suffer from the inherent bias of the learned classifier towards the seen action categories. As a consequence, unseen category samples are incorrectly classified as belonging to one of the seen action categories. In this paper, we set out to tackle this issue by arguing for a separate treatment of seen and unseen action categories in generalized zero-shot action recognition. We introduce an out-of-distribution detector that determines whether the video features belong to a seen or unseen action category. To train our out-of-distribution detector, video features for unseen action categories are synthesized using generative adversarial networks trained on seen action category features. To the best of our knowledge, we are the first to propose an out-of-distribution detector based GZSL framework for action recognition in videos. Experiments are performed on three action recognition datasets: Olympic Sports, HMDB51 and UCF101. For generalized zero-shot action recognition, our proposed approach outperforms the baseline (f-CLSWGAN) with absolute gains (in classification accuracy) of 7.0%, 3.4%, and 4.9%, respectively, on these datasets.
Interpretable and Generalizable Deep Image Matching with Adaptive Convolutions
Apr 23, 2019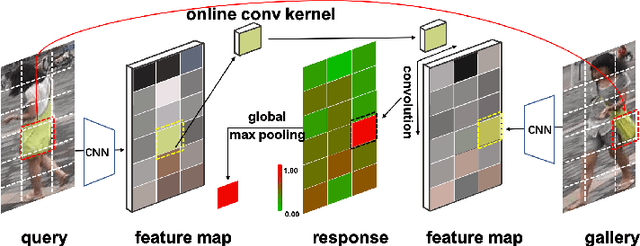
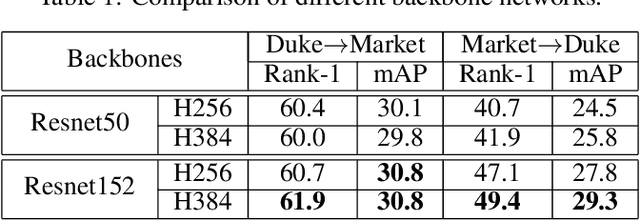

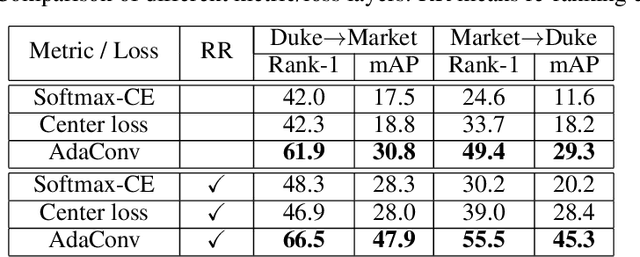
For image matching tasks, like face recognition and person re-identification, existing deep networks often focus on representation learning. However, without domain adaptation or transfer learning, the learned model is fixed as is, which is not adaptable to handle various unseen scenarios. In this paper, beyond representation learning, we consider how to formulate image matching directly in deep feature maps. We treat image matching as finding local correspondences in feature maps, and construct adaptive convolution kernels on the fly to achieve local matching. In this way, the matching process and result is interpretable, and this explicit matching is more generalizable than representation features to unseen scenarios, such as unknown misalignments, pose or viewpoint changes. To facilitate end-to-end training of such an image matching architecture, we further build a class memory module to cache feature maps of the most recent samples of each class, so as to compute image matching losses for metric learning. The proposed method is preliminarily validated on the person re-identification task. Through direct cross-dataset evaluation without further transfer learning, it achieves better results than many transfer learning methods. Besides, a model-free temporal cooccurrence based score weighting method is proposed, which improves the performance to a further extent, resulting in state-of-the-art results in cross-dataset evaluation.