 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing User Sequence Modeling through Barlow Twins-based Self-Supervised Learning
May 02, 2025



User sequence modeling is crucial for modern large-scale recommendation systems, as it enables the extraction of informative representations of users and items from their historical interactions. These user representations are widely used for a variety of downstream tasks to enhance users' online experience. A key challenge for learning these representations is the lack of labeled training data. While self-supervised learning (SSL) methods have emerged as a promising solution for learning representations from unlabeled data, many existing approaches rely on extensive negative sampling, which can be computationally expensive and may not always be feasible in real-world scenario. In this work, we propose an adaptation of Barlow Twins, a state-of-the-art SSL methods, to user sequence modeling by incorporating suitable augmentation methods. Our approach aims to mitigate the need for large negative sample batches, enabling effective representation learning with smaller batch sizes and limited labeled data. We evaluate our method on the MovieLens-1M, MovieLens-20M, and Yelp datasets, demonstrating that our method consistently outperforms the widely-used dual encoder model across three downstream tasks, achieving an 8%-20% improvement in accuracy. Our findings underscore the effectiveness of our approach in extracting valuable sequence-level information for user modeling, particularly in scenarios where labeled data is scarce and negative examples are limited.
RLPF: Reinforcement Learning from Prediction Feedback for User Summarization with LLMs
Sep 06, 2024



LLM-powered personalization agent systems employ Large Language Models (LLMs) to predict users' behavior from their past activities. However, their effectiveness often hinges on the ability to effectively leverage extensive, long user historical data due to its inherent noise and length of such data. Existing pretrained LLMs may generate summaries that are concise but lack the necessary context for downstream tasks, hindering their utility in personalization systems. To address these challenges, we introduce Reinforcement Learning from Prediction Feedback (RLPF). RLPF fine-tunes LLMs to generate concise, human-readable user summaries that are optimized for downstream task performance. By maximizing the usefulness of the generated summaries, RLPF effectively distills extensive user history data while preserving essential information for downstream tasks. Our empirical evaluation demonstrates significant improvements in both extrinsic downstream task utility and intrinsic summary quality, surpassing baseline methods by up to 22% on downstream task performance and achieving an up to 84.59% win rate on Factuality, Abstractiveness, and Readability. RLPF also achieves a remarkable 74% reduction in context length while improving performance on 16 out of 19 unseen tasks and/or datasets, showcasing its generalizability. This approach offers a promising solution for enhancing LLM personalization by effectively transforming long, noisy user histories into informative and human-readable representations.
UserSumBench: A Benchmark Framework for Evaluating User Summarization Approaches
Aug 30, 2024



Large language models (LLMs) have shown remarkable capabilities in generating user summaries from a long list of raw user activity data. These summaries capture essential user information such as preferences and interests, and therefore are invaluable for LLM-based personalization applications, such as explainable recommender systems. However, the development of new summarization techniques is hindered by the lack of ground-truth labels, the inherent subjectivity of user summaries, and human evaluation which is often costly and time-consuming. To address these challenges, we introduce \UserSumBench, a benchmark framework designed to facilitate iterative development of LLM-based summarization approaches. This framework offers two key components: (1) A reference-free summary quality metric. We show that this metric is effective and aligned with human preferences across three diverse datasets (MovieLens, Yelp and Amazon Review). (2) A novel robust summarization method that leverages time-hierarchical summarizer and self-critique verifier to produce high-quality summaries while eliminating hallucination. This method serves as a strong baseline for further innovation in summarization techniques.
MoDE: Effective Multi-task Parameter Efficient Fine-Tuning with a Mixture of Dyadic Experts
Aug 02, 2024Parameter-efficient fine-tuning techniques like Low-Rank Adaptation (LoRA) have revolutionized the adaptation of large language models (LLMs) to diverse tasks. Recent efforts have explored mixtures of LoRA modules for multi-task settings. However, our analysis reveals redundancy in the down-projection matrices of these architectures. This observation motivates our proposed method, Mixture of Dyadic Experts (MoDE), which introduces a novel design for efficient multi-task adaptation. This is done by sharing the down-projection matrix across tasks and employing atomic rank-one adapters, coupled with routers that allow more sophisticated task-level specialization. Our design allows for more fine-grained mixing, thereby increasing the model's ability to jointly handle multiple tasks. We evaluate MoDE on the Supernatural Instructions (SNI) benchmark consisting of a diverse set of 700+ tasks and demonstrate that it outperforms state-of-the-art multi-task parameter-efficient fine-tuning (PEFT) methods, without introducing additional parameters. Our findings contribute to a deeper understanding of parameter efficiency in multi-task LLM adaptation and provide a practical solution for deploying high-performing, lightweight models.
User-LLM: Efficient LLM Contextualization with User Embeddings
Feb 21, 2024Large language models (LLMs) have revolutionized natural language processing. However, effectively incorporating complex and potentially noisy user interaction data remains a challenge. To address this, we propose User-LLM, a novel framework that leverages user embeddings to contextualize LLMs. These embeddings, distilled from diverse user interactions using self-supervised pretraining, capture latent user preferences and their evolution over time. We integrate these user embeddings with LLMs through cross-attention and soft-prompting, enabling LLMs to dynamically adapt to user context. Our comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate significant performance gains across various tasks. Notably, our approach outperforms text-prompt-based contextualization on long sequence tasks and tasks that require deep user understanding while being computationally efficient. We further incorporate Perceiver layers to streamline the integration between user encoders and LLMs, reducing computational demands.
Mixed Federated Learning: Joint Decentralized and Centralized Learning
May 26, 2022
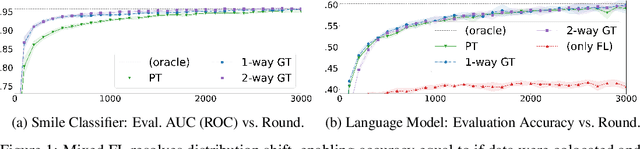
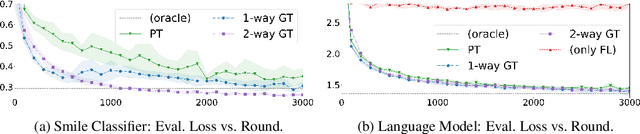
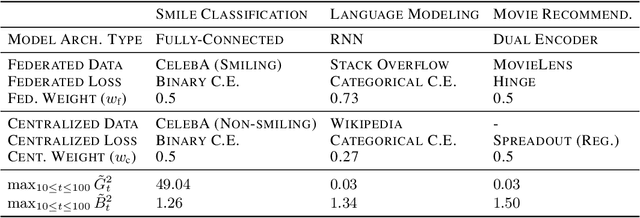
Federated learning (FL) enables learning from decentralized privacy-sensitive data, with computations on raw data confined to take place at edge clients. This paper introduces mixed FL, which incorporates an additional loss term calculated at the coordinating server (while maintaining FL's private data restrictions). There are numerous benefits. For example, additional datacenter data can be leveraged to jointly learn from centralized (datacenter) and decentralized (federated) training data and better match an expected inference data distribution. Mixed FL also enables offloading some intensive computations (e.g., embedding regularization) to the server, greatly reducing communication and client computation load. For these and other mixed FL use cases, we present three algorithms: PARALLEL TRAINING, 1-WAY GRADIENT TRANSFER, and 2-WAY GRADIENT TRANSFER. We state convergence bounds for each, and give intuition on which are suited to particular mixed FL problems. Finally we perform extensive experiments on three tasks, demonstrating that mixed FL can blend training data to achieve an oracle's accuracy on an inference distribution, and can reduce communication and computation overhead by over 90%. Our experiments confirm theoretical predictions of how algorithms perform under different mixed FL problem settings.
What Do We Mean by Generalization in Federated Learning?
Oct 27, 2021
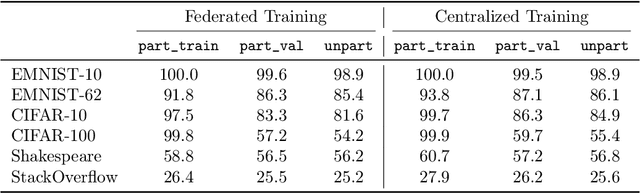
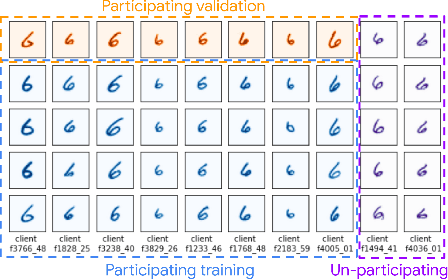
Federated learning data is drawn from a distribution of distributions: clients are drawn from a meta-distribution, and their data are drawn from local data distributions. Thus generalization studies in federated learning should separate performance gaps from unseen client data (out-of-sample gap) from performance gaps from unseen client distributions (participation gap). In this work, we propose a framework for disentangling these performance gaps. Using this framework, we observe and explain differences in behavior across natural and synthetic federated datasets, indicating that dataset synthesis strategy can be important for realistic simulations of generalization in federated learning. We propose a semantic synthesis strategy that enables realistic simulation without naturally-partitioned data. Informed by our findings, we call out community suggestions for future federated learning works.
Learning Federated Representations and Recommendations with Limited Negatives
Aug 18, 2021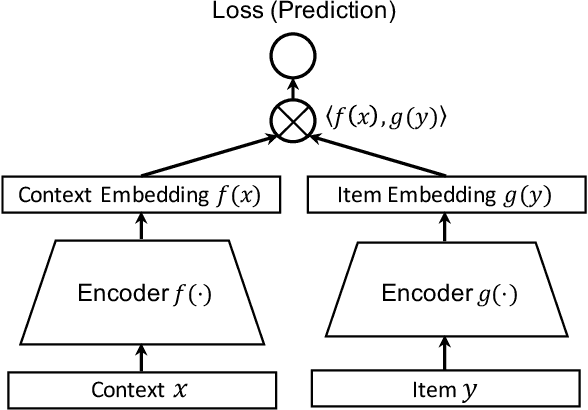
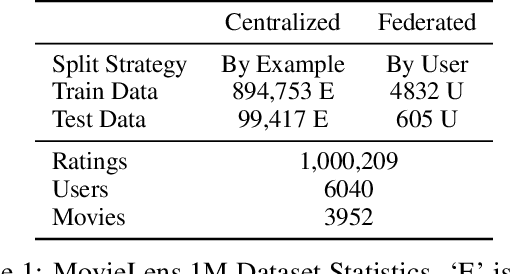

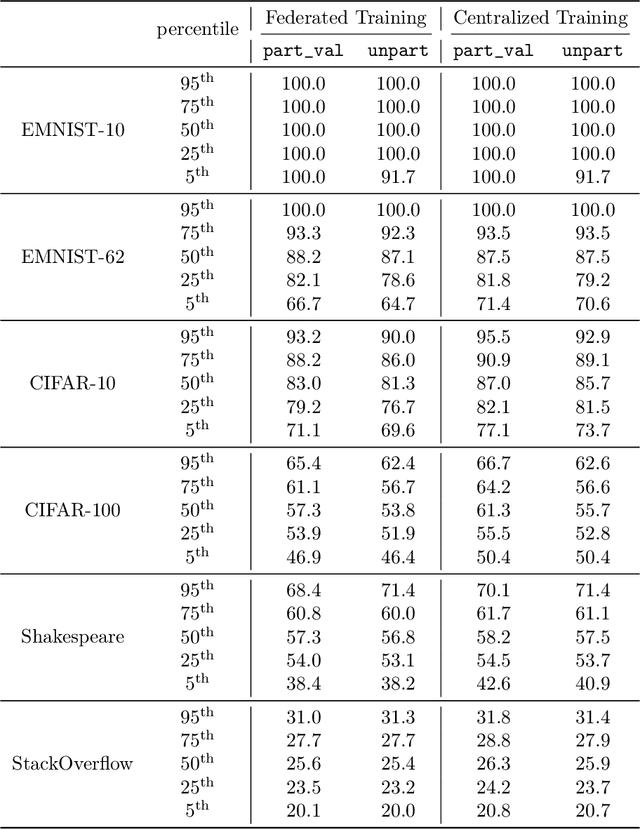
Deep retrieval models are widely used for learning entity representations and recommendations. Federated learning provides a privacy-preserving way to train these models without requiring centralization of user data. However, federated deep retrieval models usually perform much worse than their centralized counterparts due to non-IID (independent and identically distributed) training data on clients, an intrinsic property of federated learning that limits negatives available for training. We demonstrate that this issue is distinct from the commonly studied client drift problem. This work proposes batch-insensitive losses as a way to alleviate the non-IID negatives issue for federated movie recommendation. We explore a variety of techniques and identify that batch-insensitive losses can effectively improve the performance of federated deep retrieval models, increasing the relative recall of the federated model by up to 93.15% and reducing the relative gap in recall between it and a centralized model from 27.22% - 43.14% to 0.53% - 2.42%. We open-source our code framework to accelerate further research and applications of federated deep retrieval models.
In-Place Zero-Space Memory Protection for CNN
Oct 31, 2019
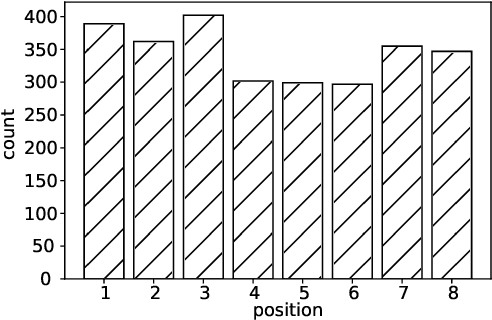
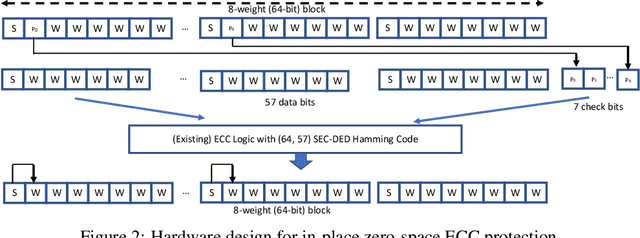
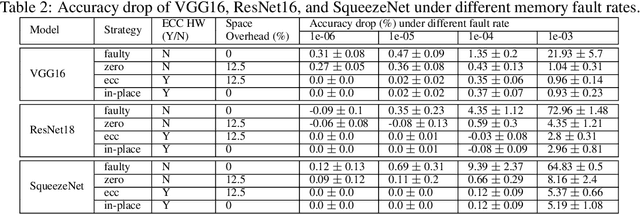
Convolutional Neural Networks (CNN) are being actively explored for safety-critical applications such as autonomous vehicles and aerospace, where it is essential to ensure the reliability of inference results in the presence of possible memory faults. Traditional methods such as error correction codes (ECC) and Triple Modular Redundancy (TMR) are CNN-oblivious and incur substantial memory overhead and energy cost. This paper introduces in-place zero-space ECC assisted with a new training scheme weight distribution-oriented training. The new method provides the first known zero space cost memory protection for CNNs without compromising the reliability offered by traditional ECC.