 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKTN: Knowledge Transfer Network for Learning Multi-person 2D-3D Correspondences
Jun 21, 2022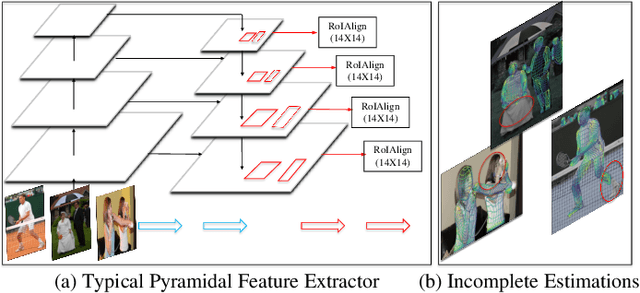
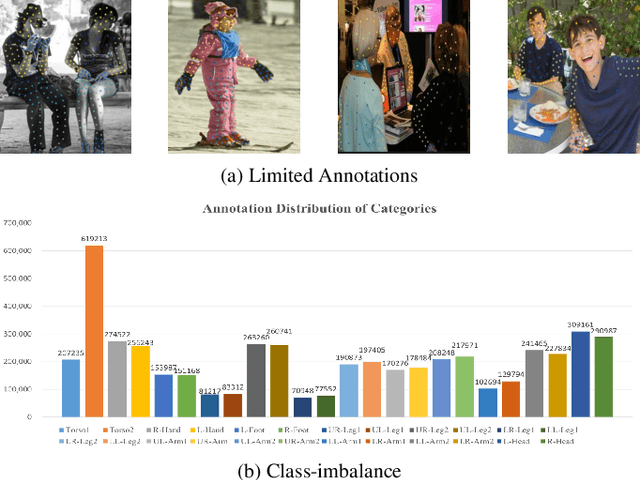
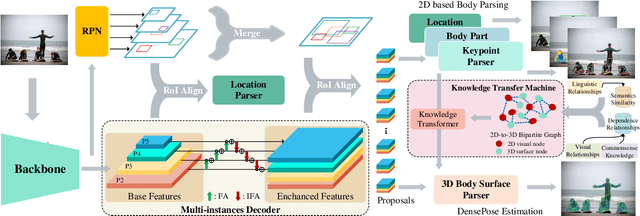
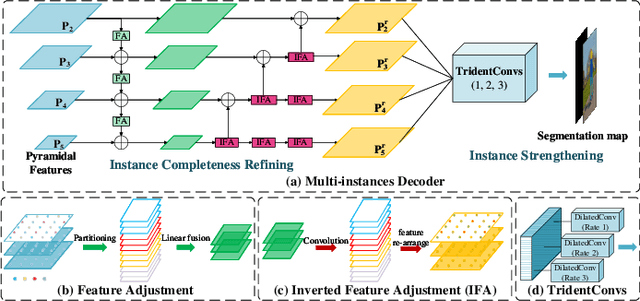
Human densepose estimation, aiming at establishing dense correspondences between 2D pixels of human body and 3D human body template, is a key technique in enabling machines to have an understanding of people in images. It still poses several challenges due to practical scenarios where real-world scenes are complex and only partial annotations are available, leading to incompelete or false estimations. In this work, we present a novel framework to detect the densepose of multiple people in an image. The proposed method, which we refer to Knowledge Transfer Network (KTN), tackles two main problems: 1) how to refine image representation for alleviating incomplete estimations, and 2) how to reduce false estimation caused by the low-quality training labels (i.e., limited annotations and class-imbalance labels). Unlike existing works directly propagating the pyramidal features of regions for densepose estimation, the KTN uses a refinement of pyramidal representation, where it simultaneously maintains feature resolution and suppresses background pixels, and this strategy results in a substantial increase in accuracy. Moreover, the KTN enhances the ability of 3D based body parsing with external knowledges, where it casts 2D based body parsers trained from sufficient annotations as a 3D based body parser through a structural body knowledge graph. In this way, it significantly reduces the adverse effects caused by the low-quality annotations. The effectiveness of KTN is demonstrated by its superior performance to the state-of-the-art methods on DensePose-COCO dataset. Extensive ablation studies and experimental results on representative tasks (e.g., human body segmentation, human part segmentation and keypoints detection) and two popular densepose estimation pipelines (i.e., RCNN and fully-convolutional frameworks), further indicate the generalizability of the proposed method.
From Pixels to Objects: Cubic Visual Attention for Visual Question Answering
Jun 04, 2022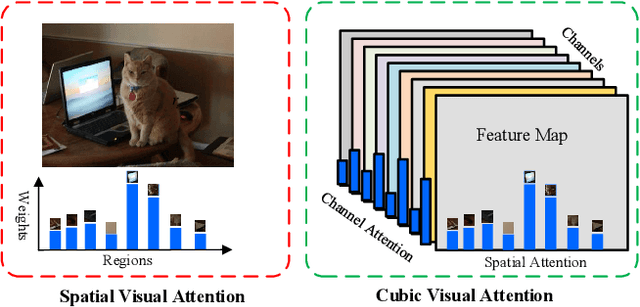
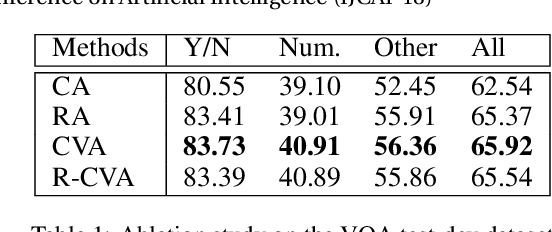
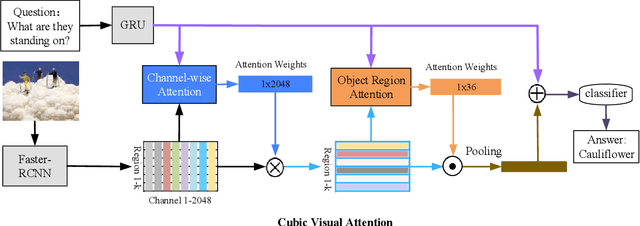
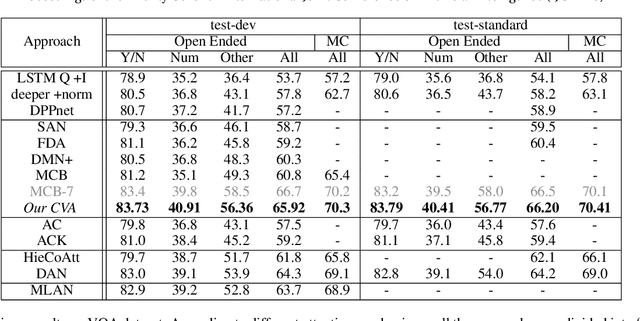
Recently, attention-based Visual Question Answering (VQA) has achieved great success by utilizing question to selectively target different visual areas that are related to the answer. Existing visual attention models are generally planar, i.e., different channels of the last conv-layer feature map of an image share the same weight. This conflicts with the attention mechanism because CNN features are naturally spatial and channel-wise. Also, visual attention models are usually conducted on pixel-level, which may cause region discontinuous problems. In this paper, we propose a Cubic Visual Attention (CVA) model by successfully applying a novel channel and spatial attention on object regions to improve VQA task. Specifically, instead of attending to pixels, we first take advantage of the object proposal networks to generate a set of object candidates and extract their associated conv features. Then, we utilize the question to guide channel attention and spatial attention calculation based on the con-layer feature map. Finally, the attended visual features and the question are combined to infer the answer. We assess the performance of our proposed CVA on three public image QA datasets, including COCO-QA, VQA and Visual7W. Experimental results show that our proposed method significantly outperforms the state-of-the-arts.
Structured Two-stream Attention Network for Video Question Answering
Jun 02, 2022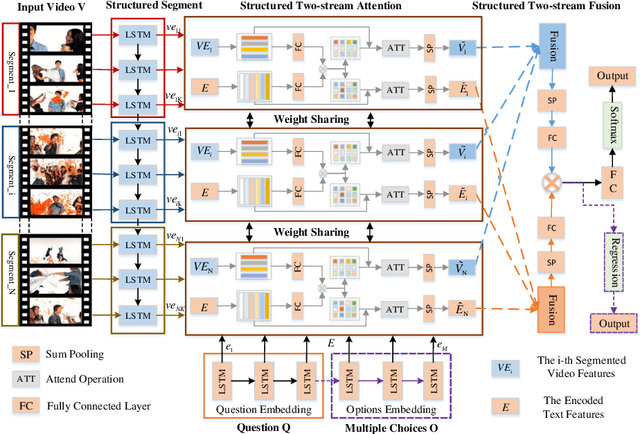
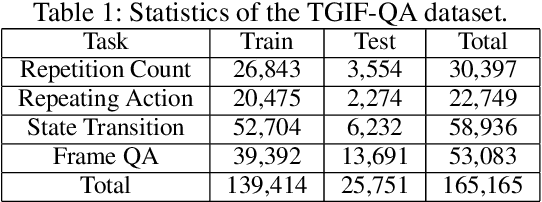
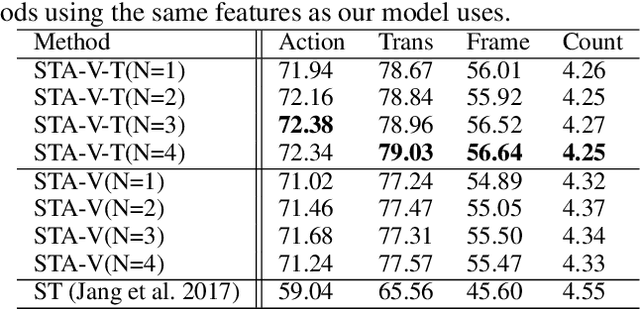

To date, visual question answering (VQA) (i.e., image QA and video QA) is still a holy grail in vision and language understanding, especially for video QA. Compared with image QA that focuses primarily on understanding the associations between image region-level details and corresponding questions, video QA requires a model to jointly reason across both spatial and long-range temporal structures of a video as well as text to provide an accurate answer. In this paper, we specifically tackle the problem of video QA by proposing a Structured Two-stream Attention network, namely STA, to answer a free-form or open-ended natural language question about the content of a given video. First, we infer rich long-range temporal structures in videos using our structured segment component and encode text features. Then, our structured two-stream attention component simultaneously localizes important visual instance, reduces the influence of background video and focuses on the relevant text. Finally, the structured two-stream fusion component incorporates different segments of query and video aware context representation and infers the answers. Experiments on the large-scale video QA dataset \textit{TGIF-QA} show that our proposed method significantly surpasses the best counterpart (i.e., with one representation for the video input) by 13.0%, 13.5%, 11.0% and 0.3 for Action, Trans., TrameQA and Count tasks. It also outperforms the best competitor (i.e., with two representations) on the Action, Trans., TrameQA tasks by 4.1%, 4.7%, and 5.1%.
Support-set based Multi-modal Representation Enhancement for Video Captioning
May 19, 2022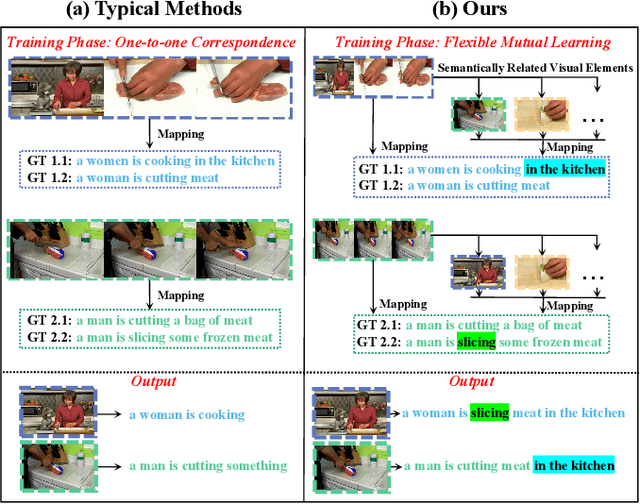
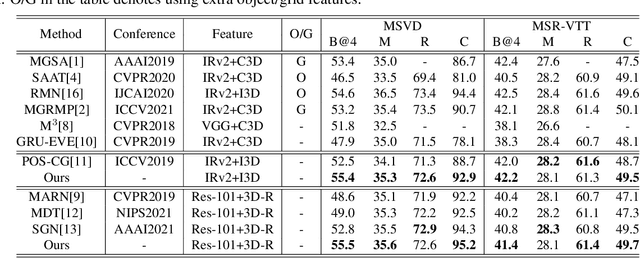
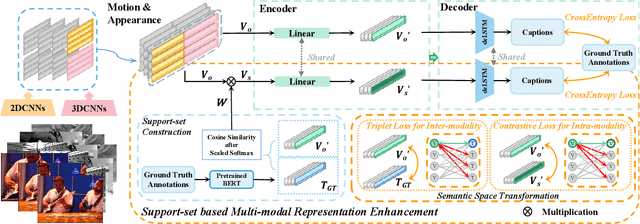
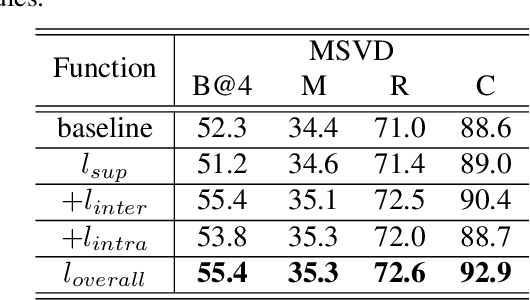
Video captioning is a challenging task that necessitates a thorough comprehension of visual scenes. Existing methods follow a typical one-to-one mapping, which concentrates on a limited sample space while ignoring the intrinsic semantic associations between samples, resulting in rigid and uninformative expressions. To address this issue, we propose a novel and flexible framework, namely Support-set based Multi-modal Representation Enhancement (SMRE) model, to mine rich information in a semantic subspace shared between samples. Specifically, we propose a Support-set Construction (SC) module to construct a support-set to learn underlying connections between samples and obtain semantic-related visual elements. During this process, we design a Semantic Space Transformation (SST) module to constrain relative distance and administrate multi-modal interactions in a self-supervised way. Extensive experiments on MSVD and MSR-VTT datasets demonstrate that our SMRE achieves state-of-the-art performance.
Fine-Grained Predicates Learning for Scene Graph Generation
Apr 08, 2022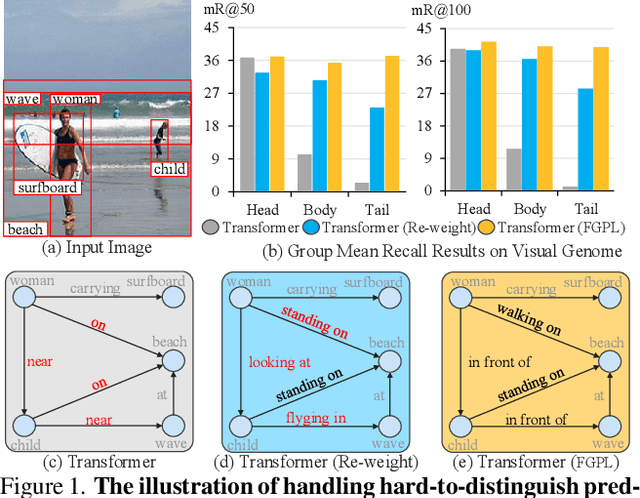
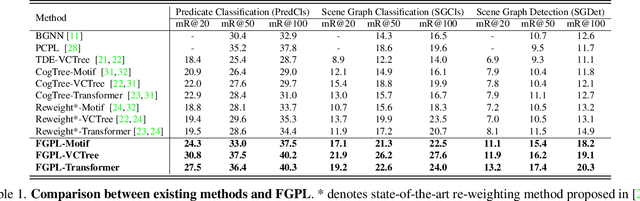
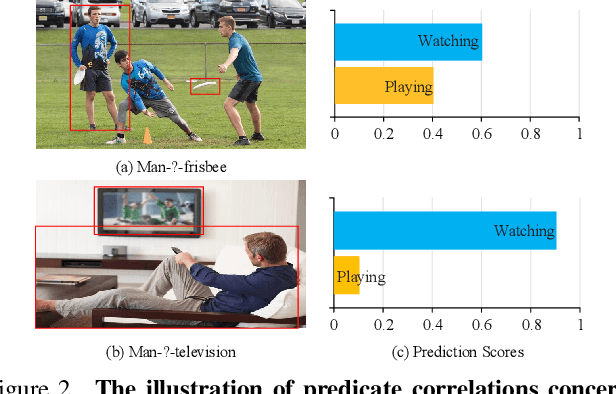
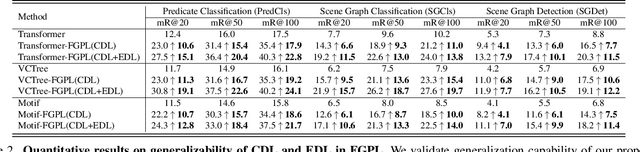
The performance of current Scene Graph Generation models is severely hampered by some hard-to-distinguish predicates, e.g., "woman-on/standing on/walking on-beach" or "woman-near/looking at/in front of-child". While general SGG models are prone to predict head predicates and existing re-balancing strategies prefer tail categories, none of them can appropriately handle these hard-to-distinguish predicates. To tackle this issue, inspired by fine-grained image classification, which focuses on differentiating among hard-to-distinguish object classes, we propose a method named Fine-Grained Predicates Learning (FGPL) which aims at differentiating among hard-to-distinguish predicates for Scene Graph Generation task. Specifically, we first introduce a Predicate Lattice that helps SGG models to figure out fine-grained predicate pairs. Then, utilizing the Predicate Lattice, we propose a Category Discriminating Loss and an Entity Discriminating Loss, which both contribute to distinguishing fine-grained predicates while maintaining learned discriminatory power over recognizable ones. The proposed model-agnostic strategy significantly boosts the performances of three benchmark models (Transformer, VCTree, and Motif) by 22.8\%, 24.1\% and 21.7\% of Mean Recall (mR@100) on the Predicate Classification sub-task, respectively. Our model also outperforms state-of-the-art methods by a large margin (i.e., 6.1\%, 4.6\%, and 3.2\% of Mean Recall (mR@100)) on the Visual Genome dataset.
Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
Mar 28, 2022
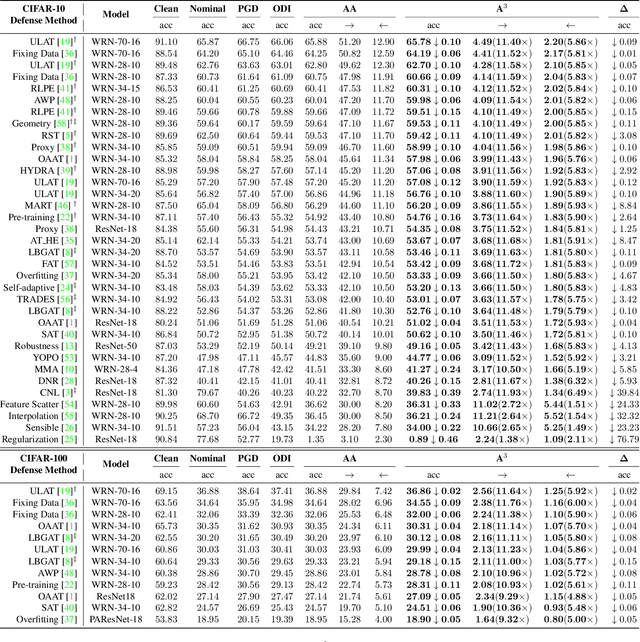
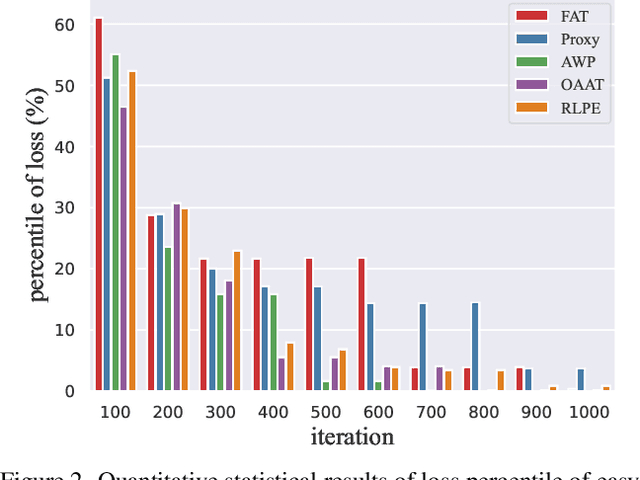
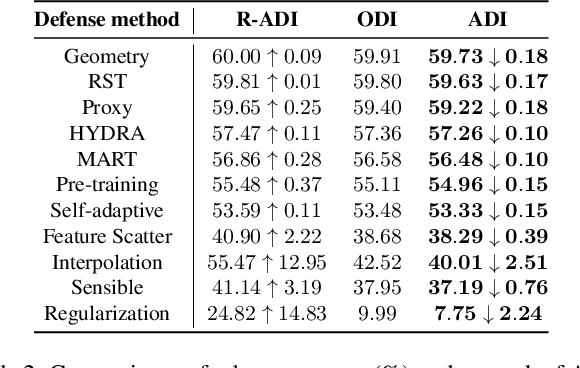
Defense models against adversarial attacks have grown significantly, but the lack of practical evaluation methods has hindered progress. Evaluation can be defined as looking for defense models' lower bound of robustness given a budget number of iterations and a test dataset. A practical evaluation method should be convenient (i.e., parameter-free), efficient (i.e., fewer iterations) and reliable (i.e., approaching the lower bound of robustness). Towards this target, we propose a parameter-free Adaptive Auto Attack (A$^3$) evaluation method which addresses the efficiency and reliability in a test-time-training fashion. Specifically, by observing that adversarial examples to a specific defense model follow some regularities in their starting points, we design an Adaptive Direction Initialization strategy to speed up the evaluation. Furthermore, to approach the lower bound of robustness under the budget number of iterations, we propose an online statistics-based discarding strategy that automatically identifies and abandons hard-to-attack images. Extensive experiments demonstrate the effectiveness of our A$^3$. Particularly, we apply A$^3$ to nearly 50 widely-used defense models. By consuming much fewer iterations than existing methods, i.e., $1/10$ on average (10$\times$ speed up), we achieve lower robust accuracy in all cases. Notably, we won $\textbf{first place}$ out of 1681 teams in CVPR 2021 White-box Adversarial Attacks on Defense Models competitions with this method. Code is available at: $\href{https://github.com/liuye6666/adaptive_auto_attack}{https://github.com/liuye6666/adaptive\_auto\_attack}$
Unified Multivariate Gaussian Mixture for Efficient Neural Image Compression
Mar 21, 2022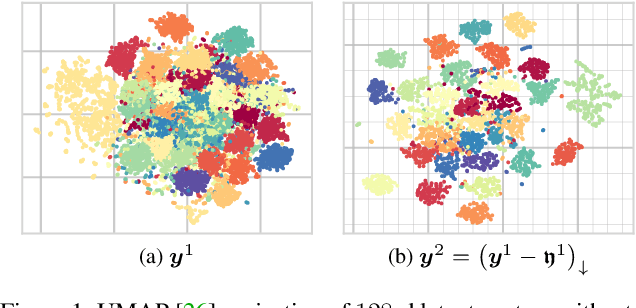
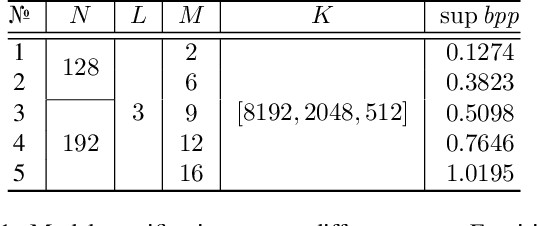
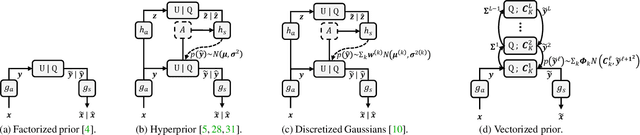
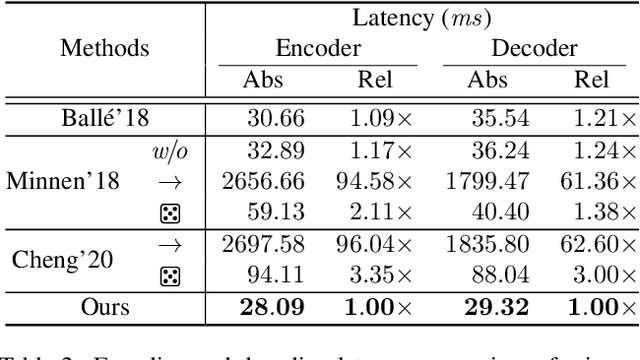
Modeling latent variables with priors and hyperpriors is an essential problem in variational image compression. Formally, trade-off between rate and distortion is handled well if priors and hyperpriors precisely describe latent variables. Current practices only adopt univariate priors and process each variable individually. However, we find inter-correlations and intra-correlations exist when observing latent variables in a vectorized perspective. These findings reveal visual redundancies to improve rate-distortion performance and parallel processing ability to speed up compression. This encourages us to propose a novel vectorized prior. Specifically, a multivariate Gaussian mixture is proposed with means and covariances to be estimated. Then, a novel probabilistic vector quantization is utilized to effectively approximate means, and remaining covariances are further induced to a unified mixture and solved by cascaded estimation without context models involved. Furthermore, codebooks involved in quantization are extended to multi-codebooks for complexity reduction, which formulates an efficient compression procedure. Extensive experiments on benchmark datasets against state-of-the-art indicate our model has better rate-distortion performance and an impressive $3.18\times$ compression speed up, giving us the ability to perform real-time, high-quality variational image compression in practice. Our source code is publicly available at \url{https://github.com/xiaosu-zhu/McQuic}.
* Accepted to CVPR 2022
Practical No-box Adversarial Attacks with Training-free Hybrid Image Transformation
Mar 09, 2022


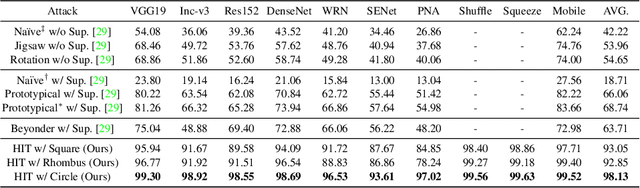
In recent years, the adversarial vulnerability of deep neural networks (DNNs) has raised increasing attention. Among all the threat models, no-box attacks are the most practical but extremely challenging since they neither rely on any knowledge of the target model or similar substitute model, nor access the dataset for training a new substitute model. Although a recent method has attempted such an attack in a loose sense, its performance is not good enough and computational overhead of training is expensive. In this paper, we move a step forward and show the existence of a \textbf{training-free} adversarial perturbation under the no-box threat model, which can be successfully used to attack different DNNs in real-time. Motivated by our observation that high-frequency component (HFC) domains in low-level features and plays a crucial role in classification, we attack an image mainly by manipulating its frequency components. Specifically, the perturbation is manipulated by suppression of the original HFC and adding of noisy HFC. We empirically and experimentally analyze the requirements of effective noisy HFC and show that it should be regionally homogeneous, repeating and dense. Extensive experiments on the ImageNet dataset demonstrate the effectiveness of our proposed no-box method. It attacks ten well-known models with a success rate of \textbf{98.13\%} on average, which outperforms state-of-the-art no-box attacks by \textbf{29.39\%}. Furthermore, our method is even competitive to mainstream transfer-based black-box attacks.
One-shot Scene Graph Generation
Feb 26, 2022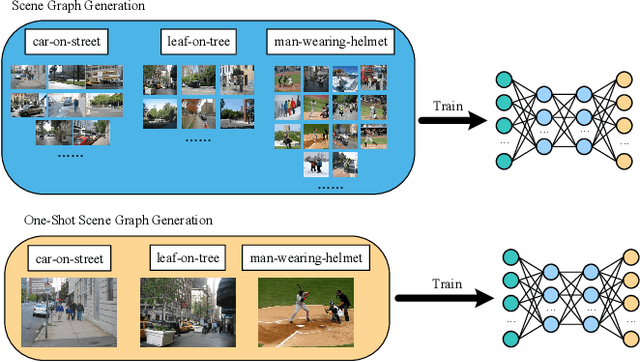
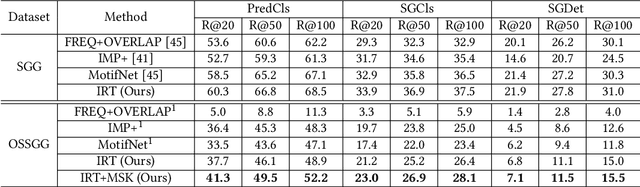
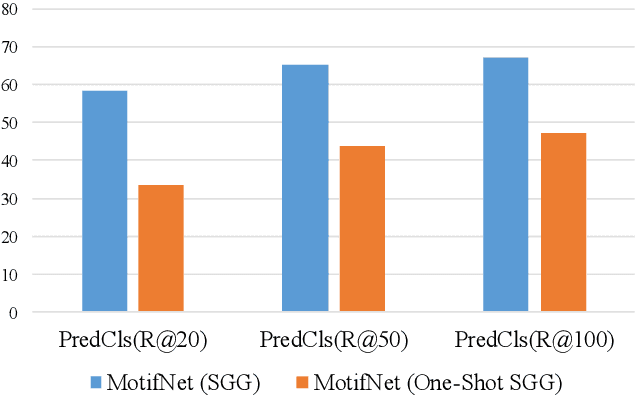
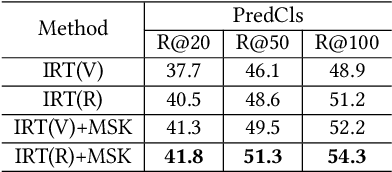
As a structured representation of the image content, the visual scene graph (visual relationship) acts as a bridge between computer vision and natural language processing. Existing models on the scene graph generation task notoriously require tens or hundreds of labeled samples. By contrast, human beings can learn visual relationships from a few or even one example. Inspired by this, we design a task named One-Shot Scene Graph Generation, where each relationship triplet (e.g., "dog-has-head") comes from only one labeled example. The key insight is that rather than learning from scratch, one can utilize rich prior knowledge. In this paper, we propose Multiple Structured Knowledge (Relational Knowledge and Commonsense Knowledge) for the one-shot scene graph generation task. Specifically, the Relational Knowledge represents the prior knowledge of relationships between entities extracted from the visual content, e.g., the visual relationships "standing in", "sitting in", and "lying in" may exist between "dog" and "yard", while the Commonsense Knowledge encodes "sense-making" knowledge like "dog can guard yard". By organizing these two kinds of knowledge in a graph structure, Graph Convolution Networks (GCNs) are used to extract knowledge-embedded semantic features of the entities. Besides, instead of extracting isolated visual features from each entity generated by Faster R-CNN, we utilize an Instance Relation Transformer encoder to fully explore their context information. Based on a constructed one-shot dataset, the experimental results show that our method significantly outperforms existing state-of-the-art methods by a large margin. Ablation studies also verify the effectiveness of the Instance Relation Transformer encoder and the Multiple Structured Knowledge.
Exploiting long-term temporal dynamics for video captioning
Feb 22, 2022
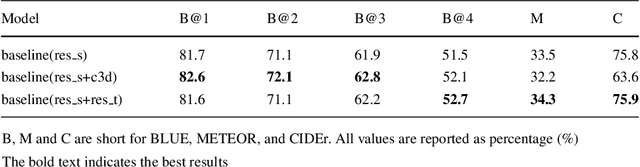
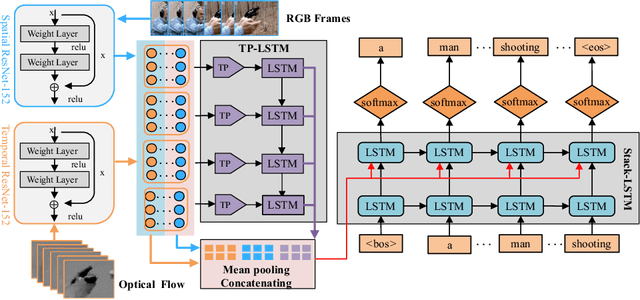
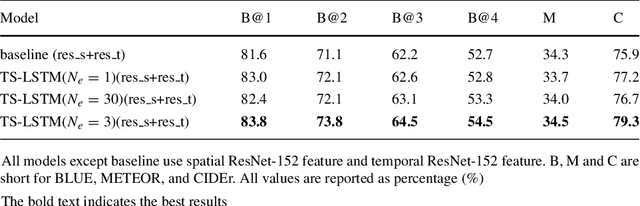
Automatically describing videos with natural language is a fundamental challenge for computer vision and natural language processing. Recently, progress in this problem has been achieved through two steps: 1) employing 2-D and/or 3-D Convolutional Neural Networks (CNNs) (e.g. VGG, ResNet or C3D) to extract spatial and/or temporal features to encode video contents; and 2) applying Recurrent Neural Networks (RNNs) to generate sentences to describe events in videos. Temporal attention-based model has gained much progress by considering the importance of each video frame. However, for a long video, especially for a video which consists of a set of sub-events, we should discover and leverage the importance of each sub-shot instead of each frame. In this paper, we propose a novel approach, namely temporal and spatial LSTM (TS-LSTM), which systematically exploits spatial and temporal dynamics within video sequences. In TS-LSTM, a temporal pooling LSTM (TP-LSTM) is designed to incorporate both spatial and temporal information to extract long-term temporal dynamics within video sub-shots; and a stacked LSTM is introduced to generate a list of words to describe the video. Experimental results obtained in two public video captioning benchmarks indicate that our TS-LSTM outperforms the state-of-the-art methods.