 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeULDP-FL: Federated Learning with Across Silo User-Level Differential Privacy
Aug 23, 2023



Differentially Private Federated Learning (DP-FL) has garnered attention as a collaborative machine learning approach that ensures formal privacy. Most DP-FL approaches ensure DP at the record-level within each silo for cross-silo FL. However, a single user's data may extend across multiple silos, and the desired user-level DP guarantee for such a setting remains unknown. In this study, we present ULDP-FL, a novel FL framework designed to guarantee user-level DP in cross-silo FL where a single user's data may belong to multiple silos. Our proposed algorithm directly ensures user-level DP through per-user weighted clipping, departing from group-privacy approaches. We provide a theoretical analysis of the algorithm's privacy and utility. Additionally, we enhance the algorithm's utility and showcase its private implementation using cryptographic building blocks. Empirical experiments on real-world datasets show substantial improvements in our methods in privacy-utility trade-offs under user-level DP compared to baseline methods. To the best of our knowledge, our work is the first FL framework that effectively provides user-level DP in the general cross-silo FL setting.
Echo of Neighbors: Privacy Amplification for Personalized Private Federated Learning with Shuffle Model
Apr 11, 2023



Federated Learning, as a popular paradigm for collaborative training, is vulnerable against privacy attacks. Different privacy levels regarding users' attitudes need to be satisfied locally, while a strict privacy guarantee for the global model is also required centrally. Personalized Local Differential Privacy (PLDP) is suitable for preserving users' varying local privacy, yet only provides a central privacy guarantee equivalent to the worst-case local privacy level. Thus, achieving strong central privacy as well as personalized local privacy with a utility-promising model is a challenging problem. In this work, a general framework (APES) is built up to strengthen model privacy under personalized local privacy by leveraging the privacy amplification effect of the shuffle model. To tighten the privacy bound, we quantify the heterogeneous contributions to the central privacy user by user. The contributions are characterized by the ability of generating "echos" from the perturbation of each user, which is carefully measured by proposed methods Neighbor Divergence and Clip-Laplace Mechanism. Furthermore, we propose a refined framework (S-APES) with the post-sparsification technique to reduce privacy loss in high-dimension scenarios. To the best of our knowledge, the impact of shuffling on personalized local privacy is considered for the first time. We provide a strong privacy amplification effect, and the bound is tighter than the baseline result based on existing methods for uniform local privacy. Experiments demonstrate that our frameworks ensure comparable or higher accuracy for the global model.
Wasserstein Adversarial Examples on Univariant Time Series Data
Mar 22, 2023Adversarial examples are crafted by adding indistinguishable perturbations to normal examples in order to fool a well-trained deep learning model to misclassify. In the context of computer vision, this notion of indistinguishability is typically bounded by $L_{\infty}$ or other norms. However, these norms are not appropriate for measuring indistinguishiability for time series data. In this work, we propose adversarial examples in the Wasserstein space for time series data for the first time and utilize Wasserstein distance to bound the perturbation between normal examples and adversarial examples. We introduce Wasserstein projected gradient descent (WPGD), an adversarial attack method for perturbing univariant time series data. We leverage the closed-form solution of Wasserstein distance in the 1D space to calculate the projection step of WPGD efficiently with the gradient descent method. We further propose a two-step projection so that the search of adversarial examples in the Wasserstein space is guided and constrained by Euclidean norms to yield more effective and imperceptible perturbations. We empirically evaluate the proposed attack on several time series datasets in the healthcare domain. Extensive results demonstrate that the Wasserstein attack is powerful and can successfully attack most of the target classifiers with a high attack success rate. To better study the nature of Wasserstein adversarial example, we evaluate a strong defense mechanism named Wasserstein smoothing for potential certified robustness defense. Although the defense can achieve some accuracy gain, it still has limitations in many cases and leaves space for developing a stronger certified robustness method to Wasserstein adversarial examples on univariant time series data.
Private Semi-supervised Knowledge Transfer for Deep Learning from Noisy Labels
Nov 03, 2022Deep learning models trained on large-scale data have achieved encouraging performance in many real-world tasks. Meanwhile, publishing those models trained on sensitive datasets, such as medical records, could pose serious privacy concerns. To counter these issues, one of the current state-of-the-art approaches is the Private Aggregation of Teacher Ensembles, or PATE, which achieved promising results in preserving the utility of the model while providing a strong privacy guarantee. PATE combines an ensemble of "teacher models" trained on sensitive data and transfers the knowledge to a "student" model through the noisy aggregation of teachers' votes for labeling unlabeled public data which the student model will be trained on. However, the knowledge or voted labels learned by the student are noisy due to private aggregation. Learning directly from noisy labels can significantly impact the accuracy of the student model. In this paper, we propose the PATE++ mechanism, which combines the current advanced noisy label training mechanisms with the original PATE framework to enhance its accuracy. A novel structure of Generative Adversarial Nets (GANs) is developed in order to integrate them effectively. In addition, we develop a novel noisy label detection mechanism for semi-supervised model training to further improve student model performance when training with noisy labels. We evaluate our method on Fashion-MNIST and SVHN to show the improvements on the original PATE on all measures.
Towards Training Graph Neural Networks with Node-Level Differential Privacy
Oct 10, 2022
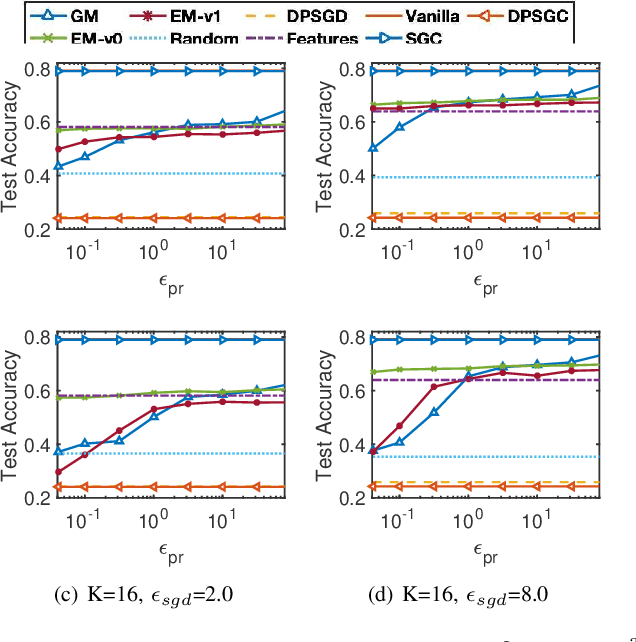
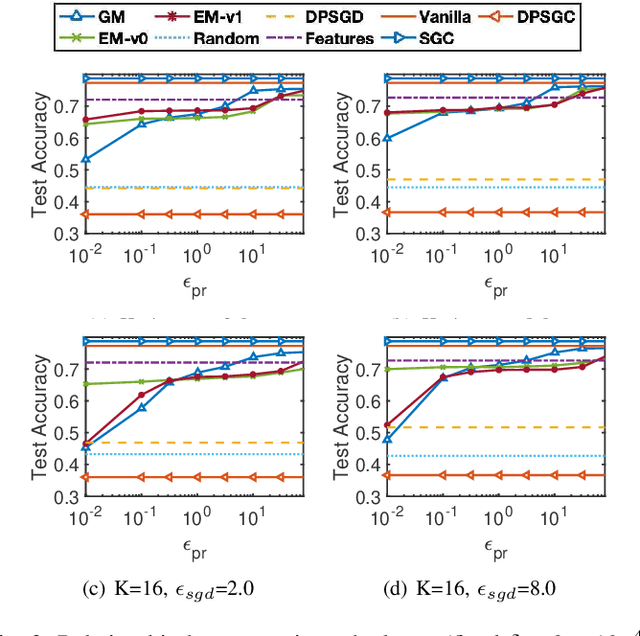
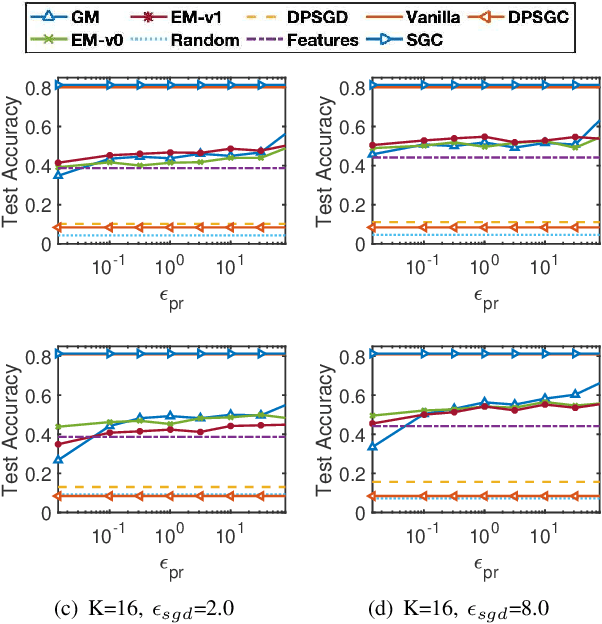
Graph Neural Networks (GNNs) have achieved great success in mining graph-structured data. Despite the superior performance of GNNs in learning graph representations, serious privacy concerns have been raised for the trained models which could expose the sensitive information of graphs. We conduct the first formal study of training GNN models to ensure utility while satisfying the rigorous node-level differential privacy considering the private information of both node features and edges. We adopt the training framework utilizing personalized PageRank to decouple the message-passing process from feature aggregation during training GNN models and propose differentially private PageRank algorithms to protect graph topology information formally. Furthermore, we analyze the privacy degradation caused by the sampling process dependent on the differentially private PageRank results during model training and propose a differentially private GNN (DPGNN) algorithm to further protect node features and achieve rigorous node-level differential privacy. Extensive experiments on real-world graph datasets demonstrate the effectiveness of the proposed algorithms for providing node-level differential privacy while preserving good model utility.
Federated Pruning: Improving Neural Network Efficiency with Federated Learning
Sep 14, 2022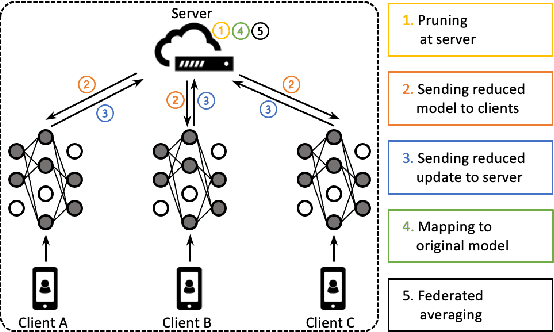
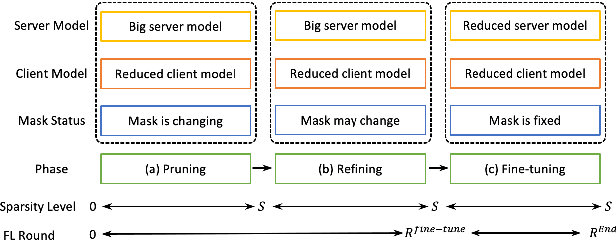
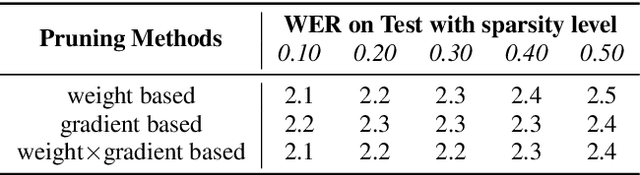
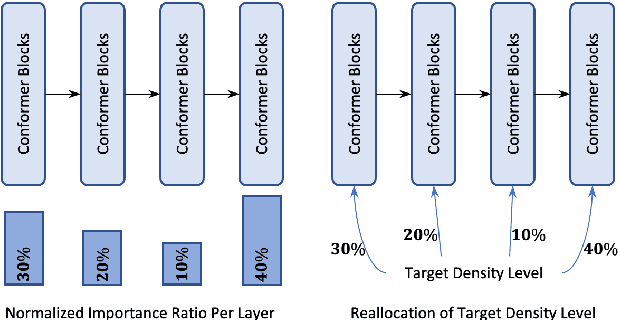
Automatic Speech Recognition models require large amount of speech data for training, and the collection of such data often leads to privacy concerns. Federated learning has been widely used and is considered to be an effective decentralized technique by collaboratively learning a shared prediction model while keeping the data local on different clients devices. However, the limited computation and communication resources on clients devices present practical difficulties for large models. To overcome such challenges, we propose Federated Pruning to train a reduced model under the federated setting, while maintaining similar performance compared to the full model. Moreover, the vast amount of clients data can also be leveraged to improve the pruning results compared to centralized training. We explore different pruning schemes and provide empirical evidence of the effectiveness of our methods.
MULTIPAR: Supervised Irregular Tensor Factorization with Multi-task Learning
Aug 09, 2022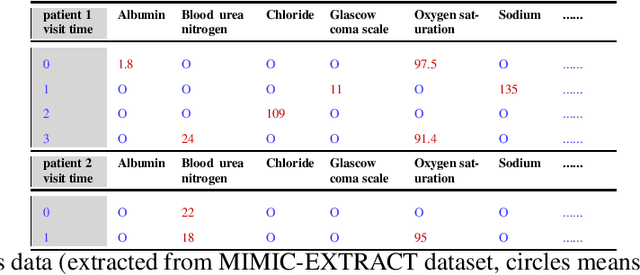
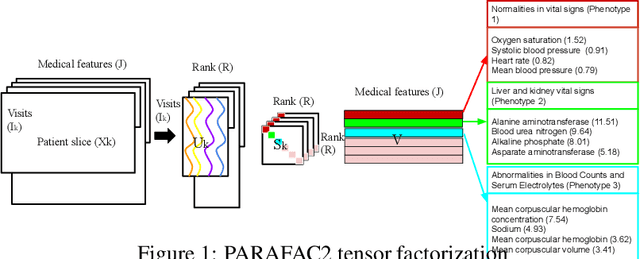
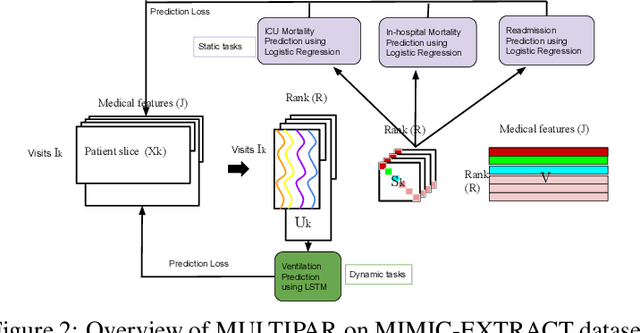
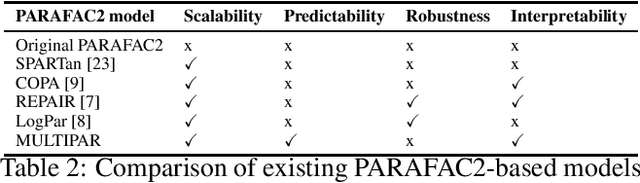
Tensor factorization has received increasing interest due to its intrinsic ability to capture latent factors in multi-dimensional data with many applications such as recommender systems and Electronic Health Records (EHR) mining. PARAFAC2 and its variants have been proposed to address irregular tensors where one of the tensor modes is not aligned, e.g., different users in recommender systems or patients in EHRs may have different length of records. PARAFAC2 has been successfully applied on EHRs for extracting meaningful medical concepts (phenotypes). Despite recent advancements, current models' predictability and interpretability are not satisfactory, which limits its utility for downstream analysis. In this paper, we propose MULTIPAR: a supervised irregular tensor factorization with multi-task learning. MULTIPAR is flexible to incorporate both static (e.g. in-hospital mortality prediction) and continuous or dynamic (e.g. the need for ventilation) tasks. By supervising the tensor factorization with downstream prediction tasks and leveraging information from multiple related predictive tasks, MULTIPAR can yield not only more meaningful phenotypes but also better predictive performance for downstream tasks. We conduct extensive experiments on two real-world temporal EHR datasets to demonstrate that MULTIPAR is scalable and achieves better tensor fit with more meaningful subgroups and stronger predictive performance compared to existing state-of-the-art methods.
Contextual Multi-View Query Learning for Short Text Classification in User-Generated Data
Dec 05, 2021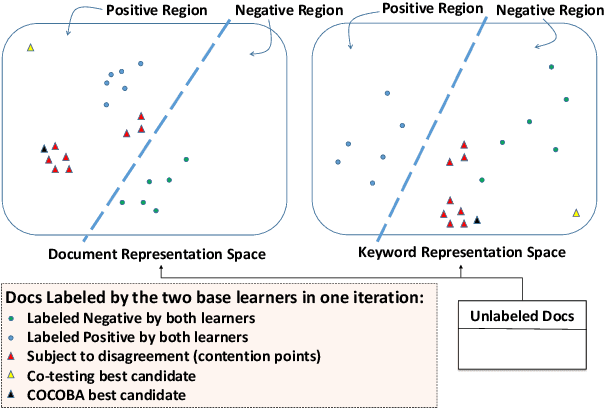
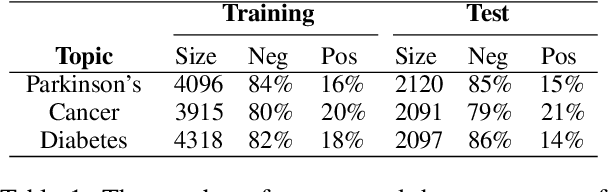
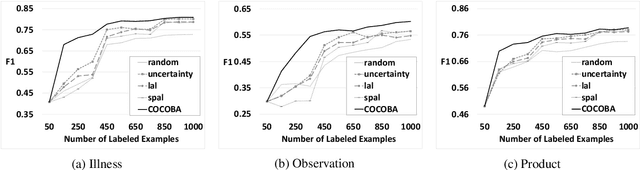

Mining user-generated content--e.g., for the early detection of outbreaks or for extracting personal observations--often suffers from the lack of enough training data, short document length, and informal language model. We propose a novel multi-view active learning model, called Context-aware Co-testing with Bagging (COCOBA), to address these issues in the classification tasks tailored for a query word--e.g., detecting illness reports given the disease name. COCOBA employs the context of user postings to construct two views. Then it uses the distribution of the representations in each view to detect the regions that are assigned to the opposite classes. This effectively leads to detecting the contexts that the two base learners disagree on. Our model also employs a query-by-committee model to address the usually noisy language of user postings. The experiments testify that our model is applicable to multiple important representative Twitter tasks and also significantly outperforms the existing baselines.
PRECAD: Privacy-Preserving and Robust Federated Learning via Crypto-Aided Differential Privacy
Oct 22, 2021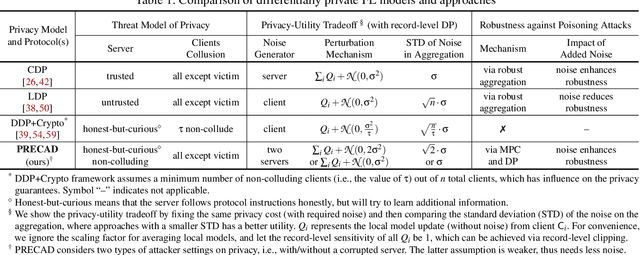
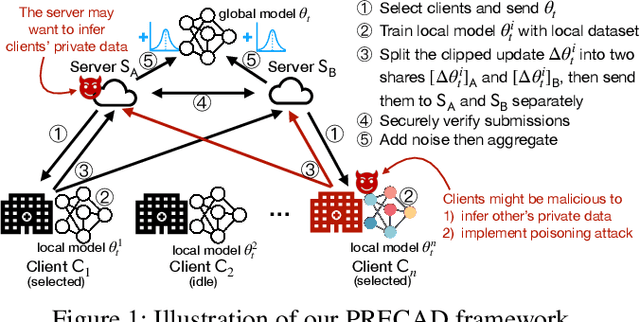

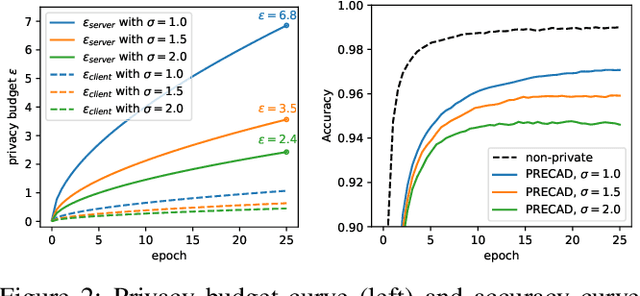
Federated Learning (FL) allows multiple participating clients to train machine learning models collaboratively by keeping their datasets local and only exchanging model updates. Existing FL protocol designs have been shown to be vulnerable to attacks that aim to compromise data privacy and/or model robustness. Recently proposed defenses focused on ensuring either privacy or robustness, but not both. In this paper, we develop a framework called PRECAD, which simultaneously achieves differential privacy (DP) and enhances robustness against model poisoning attacks with the help of cryptography. Using secure multi-party computation (MPC) techniques (e.g., secret sharing), noise is added to the model updates by the honest-but-curious server(s) (instead of each client) without revealing clients' inputs, which achieves the benefit of centralized DP in terms of providing a better privacy-utility tradeoff than local DP based solutions. Meanwhile, a crypto-aided secure validation protocol is designed to verify that the contribution of model update from each client is bounded without leaking privacy. We show analytically that the noise added to ensure DP also provides enhanced robustness against malicious model submissions. We experimentally demonstrate that our PRECAD framework achieves higher privacy-utility tradeoff and enhances robustness for the trained models.
Communication Efficient Tensor Factorization for Decentralized Healthcare Networks
Sep 03, 2021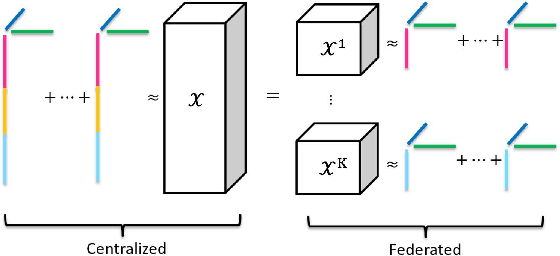
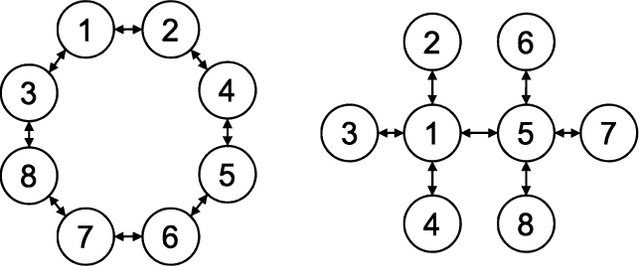
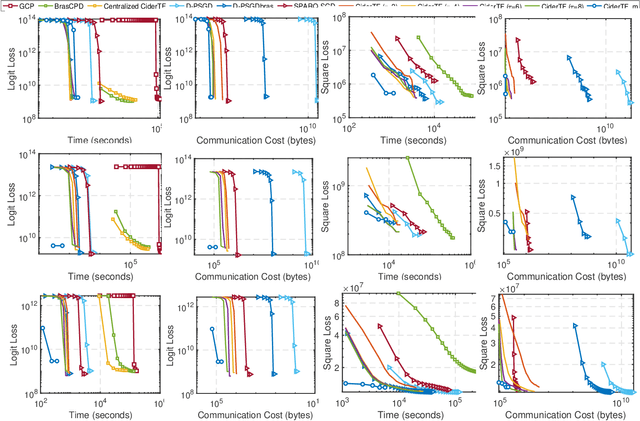
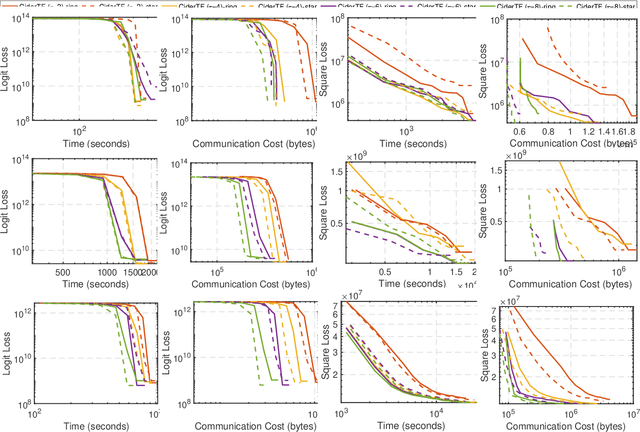
Tensor factorization has been proved as an efficient unsupervised learning approach for health data analysis, especially for computational phenotyping, where the high-dimensional Electronic Health Records (EHRs) with patients history of medical procedures, medications, diagnosis, lab tests, etc., are converted to meaningful and interpretable medical concepts. Federated tensor factorization distributes the tensor computation to multiple workers under the coordination of a central server, which enables jointly learning the phenotypes across multiple hospitals while preserving the privacy of the patient information. However, existing federated tensor factorization algorithms encounter the single-point-failure issue with the involvement of the central server, which is not only easily exposed to external attacks, but also limits the number of clients sharing information with the server under restricted uplink bandwidth. In this paper, we propose CiderTF, a communication-efficient decentralized generalized tensor factorization, which reduces the uplink communication cost by leveraging a four-level communication reduction strategy designed for a generalized tensor factorization, which has the flexibility of modeling different tensor distribution with multiple kinds of loss functions. Experiments on two real-world EHR datasets demonstrate that CiderTF achieves comparable convergence with the communication reduction up to 99.99%.