 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOSA: Music Motion with Semantic Annotation Dataset for Cross-Modal Music Processing
Jun 10, 2024



In cross-modal music processing, translation between visual, auditory, and semantic content opens up new possibilities as well as challenges. The construction of such a transformative scheme depends upon a benchmark corpus with a comprehensive data infrastructure. In particular, the assembly of a large-scale cross-modal dataset presents major challenges. In this paper, we present the MOSA (Music mOtion with Semantic Annotation) dataset, which contains high quality 3-D motion capture data, aligned audio recordings, and note-by-note semantic annotations of pitch, beat, phrase, dynamic, articulation, and harmony for 742 professional music performances by 23 professional musicians, comprising more than 30 hours and 570 K notes of data. To our knowledge, this is the largest cross-modal music dataset with note-level annotations to date. To demonstrate the usage of the MOSA dataset, we present several innovative cross-modal music information retrieval (MIR) and musical content generation tasks, including the detection of beats, downbeats, phrase, and expressive contents from audio, video and motion data, and the generation of musicians' body motion from given music audio. The dataset and codes are available alongside this publication (https://github.com/yufenhuang/MOSA-Music-mOtion-and-Semantic-Annotation-dataset).
Context-aware Difference Distilling for Multi-change Captioning
May 31, 2024Multi-change captioning aims to describe complex and coupled changes within an image pair in natural language. Compared with single-change captioning, this task requires the model to have higher-level cognition ability to reason an arbitrary number of changes. In this paper, we propose a novel context-aware difference distilling (CARD) network to capture all genuine changes for yielding sentences. Given an image pair, CARD first decouples context features that aggregate all similar/dissimilar semantics, termed common/difference context features. Then, the consistency and independence constraints are designed to guarantee the alignment/discrepancy of common/difference context features. Further, the common context features guide the model to mine locally unchanged features, which are subtracted from the pair to distill locally difference features. Next, the difference context features augment the locally difference features to ensure that all changes are distilled. In this way, we obtain an omni-representation of all changes, which is translated into linguistic sentences by a transformer decoder. Extensive experiments on three public datasets show CARD performs favourably against state-of-the-art methods.The code is available at https://github.com/tuyunbin/CARD.
BEAST: Online Joint Beat and Downbeat Tracking Based on Streaming Transformer
Jan 05, 2024Many deep learning models have achieved dominant performance on the offline beat tracking task. However, online beat tracking, in which only the past and present input features are available, still remains challenging. In this paper, we propose BEAt tracking Streaming Transformer (BEAST), an online joint beat and downbeat tracking system based on the streaming Transformer. To deal with online scenarios, BEAST applies contextual block processing in the Transformer encoder. Moreover, we adopt relative positional encoding in the attention layer of the streaming Transformer encoder to capture relative timing position which is critically important information in music. Carrying out beat and downbeat experiments on benchmark datasets for a low latency scenario with maximum latency under 50 ms, BEAST achieves an F1-measure of 80.04% in beat and 52.73% in downbeat, which is a substantial improvement of about 5 and 13 percentage points over the state-of-the-art online beat and downbeat tracking model.
Adapting pretrained speech model for Mandarin lyrics transcription and alignment
Nov 21, 2023



The tasks of automatic lyrics transcription and lyrics alignment have witnessed significant performance improvements in the past few years. However, most of the previous works only focus on English in which large-scale datasets are available. In this paper, we address lyrics transcription and alignment of polyphonic Mandarin pop music in a low-resource setting. To deal with the data scarcity issue, we adapt pretrained Whisper model and fine-tune it on a monophonic Mandarin singing dataset. With the use of data augmentation and source separation model, results show that the proposed method achieves a character error rate of less than 18% on a Mandarin polyphonic dataset for lyrics transcription, and a mean absolute error of 0.071 seconds for lyrics alignment. Our results demonstrate the potential of adapting a pretrained speech model for lyrics transcription and alignment in low-resource scenarios.
Enhancing Motor Imagery Decoding in Brain Computer Interfaces using Riemann Tangent Space Mapping and Cross Frequency Coupling
Oct 29, 2023



Objective: Motor Imagery (MI) serves as a crucial experimental paradigm within the realm of Brain Computer Interfaces (BCIs), aiming to decoding motor intentions from electroencephalogram (EEG) signals. Method: Drawing inspiration from Riemannian geometry and Cross-Frequency Coupling (CFC), this paper introduces a novel approach termed Riemann Tangent Space Mapping using Dichotomous Filter Bank with Convolutional Neural Network (DFBRTS) to enhance the representation quality and decoding capability pertaining to MI features. DFBRTS first initiates the process by meticulously filtering EEG signals through a Dichotomous Filter Bank, structured in the fashion of a complete binary tree. Subsequently, it employs Riemann Tangent Space Mapping to extract salient EEG signal features within each sub-band. Finally, a lightweight convolutional neural network is employed for further feature extraction and classification, operating under the joint supervision of cross-entropy and center loss. To validate the efficacy, extensive experiments were conducted using DFBRTS on two well-established benchmark datasets: the BCI competition IV 2a (BCIC-IV-2a) dataset and the OpenBMI dataset. The performance of DFBRTS was benchmarked against several state-of-the-art MI decoding methods, alongside other Riemannian geometry-based MI decoding approaches. Results: DFBRTS significantly outperforms other MI decoding algorithms on both datasets, achieving a remarkable classification accuracy of 78.16% for four-class and 71.58% for two-class hold-out classification, as compared to the existing benchmarks.
Self-supervised Cross-view Representation Reconstruction for Change Captioning
Sep 28, 2023



Change captioning aims to describe the difference between a pair of similar images. Its key challenge is how to learn a stable difference representation under pseudo changes caused by viewpoint change. In this paper, we address this by proposing a self-supervised cross-view representation reconstruction (SCORER) network. Concretely, we first design a multi-head token-wise matching to model relationships between cross-view features from similar/dissimilar images. Then, by maximizing cross-view contrastive alignment of two similar images, SCORER learns two view-invariant image representations in a self-supervised way. Based on these, we reconstruct the representations of unchanged objects by cross-attention, thus learning a stable difference representation for caption generation. Further, we devise a cross-modal backward reasoning to improve the quality of caption. This module reversely models a ``hallucination'' representation with the caption and ``before'' representation. By pushing it closer to the ``after'' representation, we enforce the caption to be informative about the difference in a self-supervised manner. Extensive experiments show our method achieves the state-of-the-art results on four datasets. The code is available at https://github.com/tuyunbin/SCORER.
A Phoneme-Informed Neural Network Model for Note-Level Singing Transcription
Apr 12, 2023



Note-level automatic music transcription is one of the most representative music information retrieval (MIR) tasks and has been studied for various instruments to understand music. However, due to the lack of high-quality labeled data, transcription of many instruments is still a challenging task. In particular, in the case of singing, it is difficult to find accurate notes due to its expressiveness in pitch, timbre, and dynamics. In this paper, we propose a method of finding note onsets of singing voice more accurately by leveraging the linguistic characteristics of singing, which are not seen in other instruments. The proposed model uses mel-scaled spectrogram and phonetic posteriorgram (PPG), a frame-wise likelihood of phoneme, as an input of the onset detection network while PPG is generated by the pre-trained network with singing and speech data. To verify how linguistic features affect onset detection, we compare the evaluation results through the dataset with different languages and divide onset types for detailed analysis. Our approach substantially improves the performance of singing transcription and therefore emphasizes the importance of linguistic features in singing analysis.
Neighborhood Contrastive Transformer for Change Captioning
Mar 06, 2023



Change captioning is to describe the semantic change between a pair of similar images in natural language. It is more challenging than general image captioning, because it requires capturing fine-grained change information while being immune to irrelevant viewpoint changes, and solving syntax ambiguity in change descriptions. In this paper, we propose a neighborhood contrastive transformer to improve the model's perceiving ability for various changes under different scenes and cognition ability for complex syntax structure. Concretely, we first design a neighboring feature aggregating to integrate neighboring context into each feature, which helps quickly locate the inconspicuous changes under the guidance of conspicuous referents. Then, we devise a common feature distilling to compare two images at neighborhood level and extract common properties from each image, so as to learn effective contrastive information between them. Finally, we introduce the explicit dependencies between words to calibrate the transformer decoder, which helps better understand complex syntax structure during training. Extensive experimental results demonstrate that the proposed method achieves the state-of-the-art performance on three public datasets with different change scenarios. The code is available at https://github.com/tuyunbin/NCT.
ReAssigner: A Plug-and-Play Virtual Machine Scheduling Intensifier for Heterogeneous Requests
Nov 29, 2022With the rapid development of cloud computing, virtual machine scheduling has become one of the most important but challenging issues for the cloud computing community, especially for practical heterogeneous request sequences. By analyzing the impact of request heterogeneity on some popular heuristic schedulers, it can be found that existing scheduling algorithms can not handle the request heterogeneity properly and efficiently. In this paper, a plug-and-play virtual machine scheduling intensifier, called Resource Assigner (ReAssigner), is proposed to enhance the scheduling efficiency of any given scheduler for heterogeneous requests. The key idea of ReAssigner is to pre-assign roles to physical resources and let resources of the same role form a virtual cluster to handle homogeneous requests. ReAssigner can cooperate with arbitrary schedulers by restricting their scheduling space to virtual clusters. With evaluations on the real dataset from Huawei Cloud, the proposed ReAssigner achieves significant scheduling performance improvement compared with some state-of-the-art scheduling methods.
Modeling Temporal Concept Receptive Field Dynamically for Untrimmed Video Analysis
Nov 23, 2021
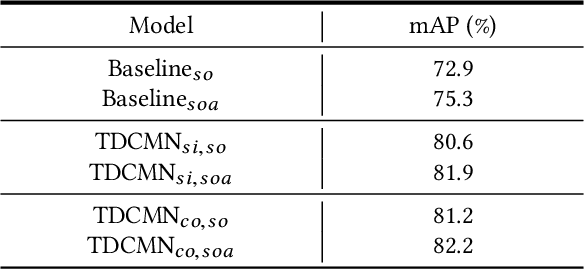
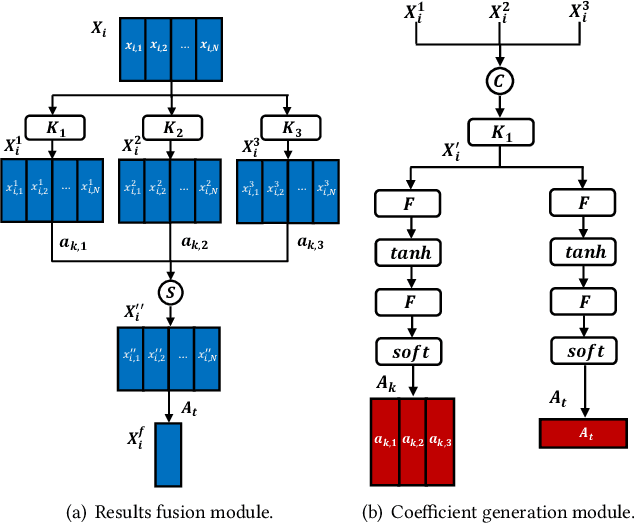
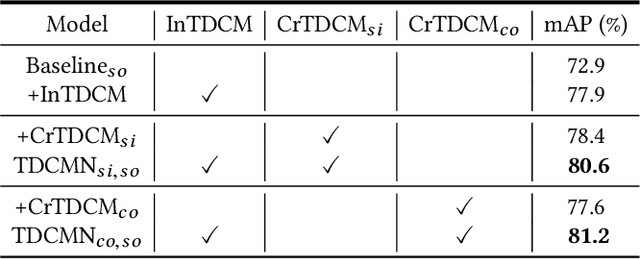
Event analysis in untrimmed videos has attracted increasing attention due to the application of cutting-edge techniques such as CNN. As a well studied property for CNN-based models, the receptive field is a measurement for measuring the spatial range covered by a single feature response, which is crucial in improving the image categorization accuracy. In video domain, video event semantics are actually described by complex interaction among different concepts, while their behaviors vary drastically from one video to another, leading to the difficulty in concept-based analytics for accurate event categorization. To model the concept behavior, we study temporal concept receptive field of concept-based event representation, which encodes the temporal occurrence pattern of different mid-level concepts. Accordingly, we introduce temporal dynamic convolution (TDC) to give stronger flexibility to concept-based event analytics. TDC can adjust the temporal concept receptive field size dynamically according to different inputs. Notably, a set of coefficients are learned to fuse the results of multiple convolutions with different kernel widths that provide various temporal concept receptive field sizes. Different coefficients can generate appropriate and accurate temporal concept receptive field size according to input videos and highlight crucial concepts. Based on TDC, we propose the temporal dynamic concept modeling network (TDCMN) to learn an accurate and complete concept representation for efficient untrimmed video analysis. Experiment results on FCVID and ActivityNet show that TDCMN demonstrates adaptive event recognition ability conditioned on different inputs, and improve the event recognition performance of Concept-based methods by a large margin. Code is available at https://github.com/qzhb/TDCMN.