 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Motion Synthesis in 3D Scenes via Unified Scene Semantic Occupancy
Nov 11, 2025Human motion synthesis in 3D scenes relies heavily on scene comprehension, while current methods focus mainly on scene structure but ignore the semantic understanding. In this paper, we propose a human motion synthesis framework that take an unified Scene Semantic Occupancy (SSO) for scene representation, termed SSOMotion. We design a bi-directional tri-plane decomposition to derive a compact version of the SSO, and scene semantics are mapped to an unified feature space via CLIP encoding and shared linear dimensionality reduction. Such strategy can derive the fine-grained scene semantic structures while significantly reduce redundant computations. We further take these scene hints and movement direction derived from instructions for motion control via frame-wise scene query. Extensive experiments and ablation studies conducted on cluttered scenes using ShapeNet furniture, as well as scanned scenes from PROX and Replica datasets, demonstrate its cutting-edge performance while validating its effectiveness and generalization ability. Code will be publicly available at https://github.com/jingyugong/SSOMotion.
Knowledge Squeezed Adversarial Network Compression
Apr 25, 2019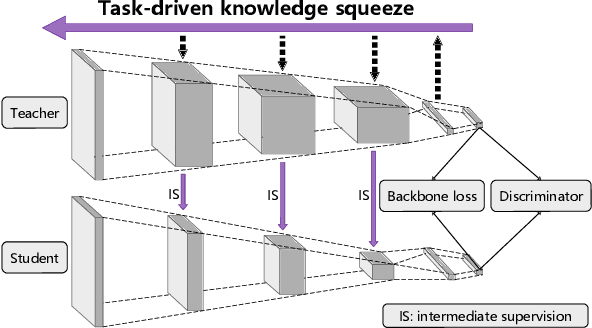
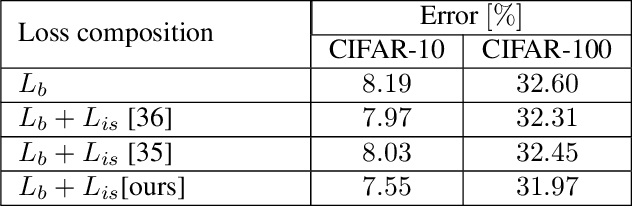
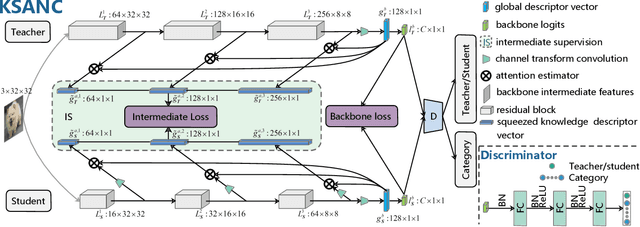
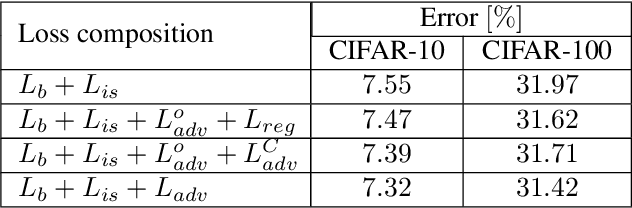
Deep network compression has been achieved notable progress via knowledge distillation, where a teacher-student learning manner is adopted by using predetermined loss. Recently, more focuses have been transferred to employ the adversarial training to minimize the discrepancy between distributions of output from two networks. However, they always emphasize on result-oriented learning while neglecting the scheme of process-oriented learning, leading to the loss of rich information contained in the whole network pipeline. Inspired by the assumption that, the small network can not perfectly mimic a large one due to the huge gap of network scale, we propose a knowledge transfer method, involving effective intermediate supervision, under the adversarial training framework to learn the student network. To achieve powerful but highly compact intermediate information representation, the squeezed knowledge is realized by task-driven attention mechanism. Then, the transferred knowledge from teacher network could accommodate the size of student network. As a result, the proposed method integrates merits from both process-oriented and result-oriented learning. Extensive experimental results on three typical benchmark datasets, i.e., CIFAR-10, CIFAR-100, and ImageNet, demonstrate that our method achieves highly superior performances against other state-of-the-art methods.