 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInharmonious Region Localization with Auxiliary Style Feature
Oct 05, 2022

With the prevalence of image editing techniques, users can create fantastic synthetic images, but the image quality may be compromised by the color/illumination discrepancy between the manipulated region and background. Inharmonious region localization aims to localize the inharmonious region in a synthetic image. In this work, we attempt to leverage auxiliary style feature to facilitate this task. Specifically, we propose a novel color mapping module and a style feature loss to extract discriminative style features containing task-relevant color/illumination information. Based on the extracted style features, we also propose a novel style voting module to guide the localization of inharmonious region. Moreover, we introduce semantic information into the style voting module to achieve further improvement. Our method surpasses the existing methods by a large margin on the benchmark dataset.
Inharmonious Region Localization by Magnifying Domain Discrepancy
Sep 30, 2022
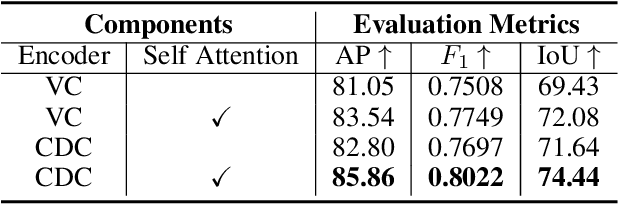
Inharmonious region localization aims to localize the region in a synthetic image which is incompatible with surrounding background. The inharmony issue is mainly attributed to the color and illumination inconsistency produced by image editing techniques. In this work, we tend to transform the input image to another color space to magnify the domain discrepancy between inharmonious region and background, so that the model can identify the inharmonious region more easily. To this end, we present a novel framework consisting of a color mapping module and an inharmonious region localization network, in which the former is equipped with a novel domain discrepancy magnification loss and the latter could be an arbitrary localization network. Extensive experiments on image harmonization dataset show the superiority of our designed framework. Our code is available at https://github.com/bcmi/MadisNet-Inharmonious-Region-Localization.
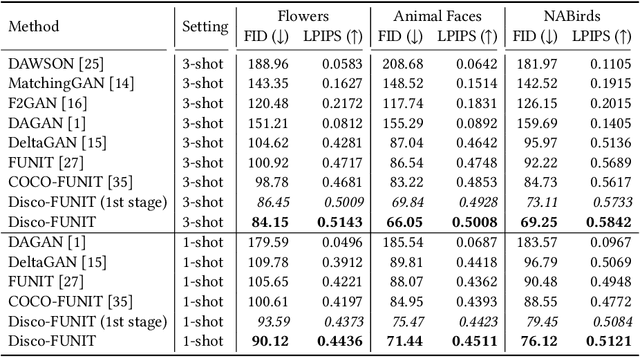
DeltaGAN: Towards Diverse Few-shot Image Generation with Sample-Specific Delta
Jul 28, 2022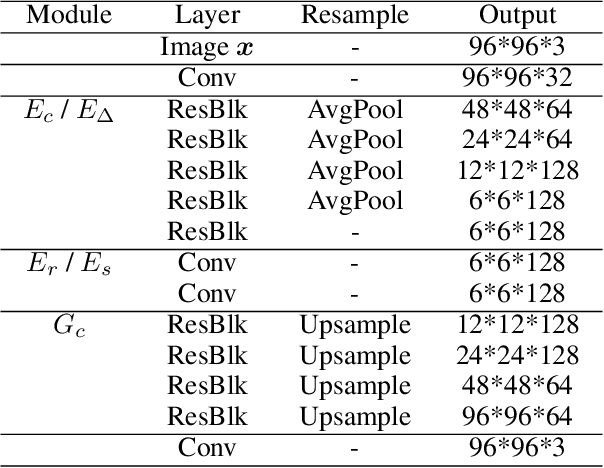

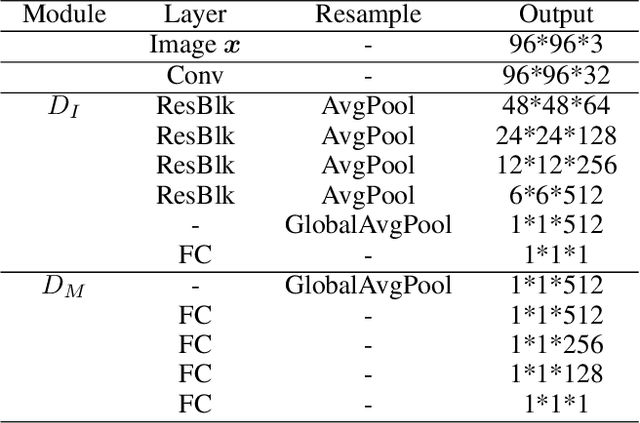

Learning to generate new images for a novel category based on only a few images, named as few-shot image generation, has attracted increasing research interest. Several state-of-the-art works have yielded impressive results, but the diversity is still limited. In this work, we propose a novel Delta Generative Adversarial Network (DeltaGAN), which consists of a reconstruction subnetwork and a generation subnetwork. The reconstruction subnetwork captures intra-category transformation, i.e., delta, between same-category pairs. The generation subnetwork generates sample-specific delta for an input image, which is combined with this input image to generate a new image within the same category. Besides, an adversarial delta matching loss is designed to link the above two subnetworks together. Extensive experiments on six benchmark datasets demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/bcmi/DeltaGAN-Few-Shot-Image-Generation.
Learning Object Placement via Dual-path Graph Completion
Jul 23, 2022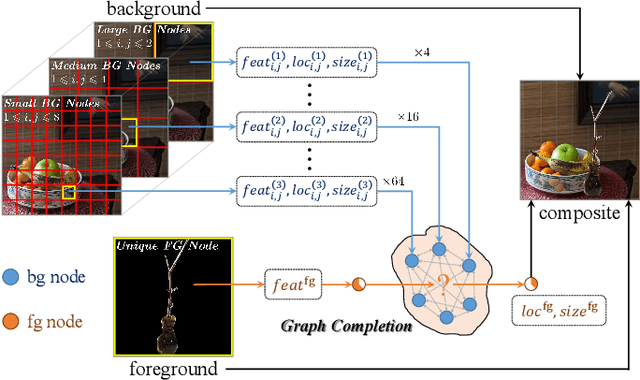

Object placement aims to place a foreground object over a background image with a suitable location and size. In this work, we treat object placement as a graph completion problem and propose a novel graph completion module (GCM). The background scene is represented by a graph with multiple nodes at different spatial locations with various receptive fields. The foreground object is encoded as a special node that should be inserted at a reasonable place in this graph. We also design a dual-path framework upon the structure of GCM to fully exploit annotated composite images. With extensive experiments on OPA dataset, our method proves to significantly outperform existing methods in generating plausible object placement without loss of diversity.
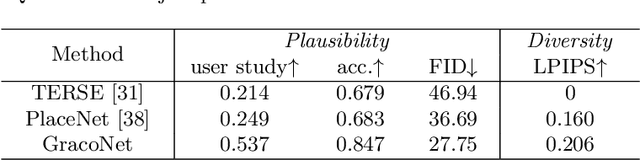
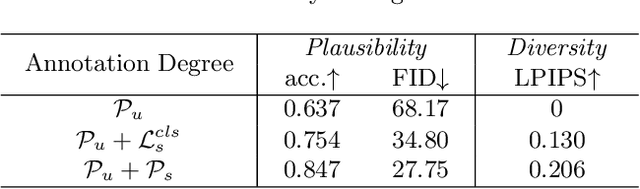
Few-shot Image Generation Using Discrete Content Representation
Jul 22, 2022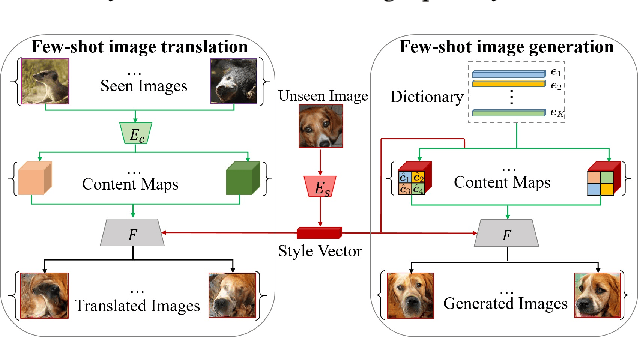

Few-shot image generation and few-shot image translation are two related tasks, both of which aim to generate new images for an unseen category with only a few images. In this work, we make the first attempt to adapt few-shot image translation method to few-shot image generation task. Few-shot image translation disentangles an image into style vector and content map. An unseen style vector can be combined with different seen content maps to produce different images. However, it needs to store seen images to provide content maps and the unseen style vector may be incompatible with seen content maps. To adapt it to few-shot image generation task, we learn a compact dictionary of local content vectors via quantizing continuous content maps into discrete content maps instead of storing seen images. Furthermore, we model the autoregressive distribution of discrete content map conditioned on style vector, which can alleviate the incompatibility between content map and style vector. Qualitative and quantitative results on three real datasets demonstrate that our model can produce images of higher diversity and fidelity for unseen categories than previous methods.
Human-centric Image Cropping with Partition-aware and Content-preserving Features
Jul 21, 2022

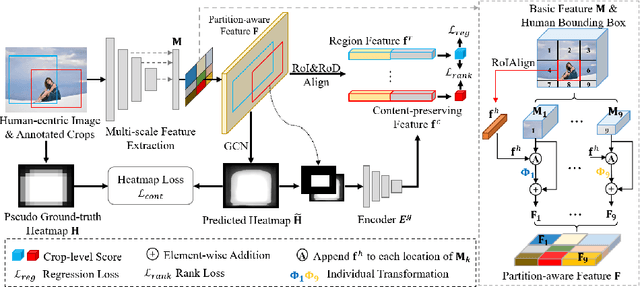
Image cropping aims to find visually appealing crops in an image, which is an important yet challenging task. In this paper, we consider a specific and practical application: human-centric image cropping, which focuses on the depiction of a person. To this end, we propose a human-centric image cropping method with two novel feature designs for the candidate crop: partition-aware feature and content-preserving feature. For partition-aware feature, we divide the whole image into nine partitions based on the human bounding box and treat different partitions in a candidate crop differently conditioned on the human information. For content-preserving feature, we predict a heatmap indicating the important content to be included in a good crop, and extract the geometric relation between the heatmap and a candidate crop. Extensive experiments demonstrate that our method can perform favorably against state-of-the-art image cropping methods on human-centric image cropping task. Code is available at https://github.com/bcmi/Human-Centric-Image-Cropping.
Spatial Transformation for Image Composition via Correspondence Learning
Jul 06, 2022

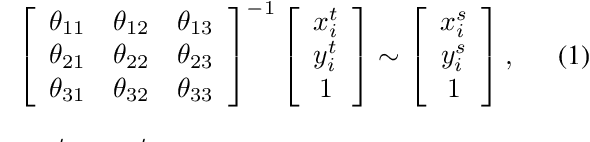

When using cut-and-paste to acquire a composite image, the geometry inconsistency between foreground and background may severely harm its fidelity. To address the geometry inconsistency in composite images, several existing works learned to warp the foreground object for geometric correction. However, the absence of annotated dataset results in unsatisfactory performance and unreliable evaluation. In this work, we contribute a Spatial TRAnsformation for virtual Try-on (STRAT) dataset covering three typical application scenarios. Moreover, previous works simply concatenate foreground and background as input without considering their mutual correspondence. Instead, we propose a novel correspondence learning network (CorrelNet) to model the correspondence between foreground and background using cross-attention maps, based on which we can predict the target coordinate that each source coordinate of foreground should be mapped to on the background. Then, the warping parameters of foreground object can be derived from pairs of source and target coordinates. Additionally, we learn a filtering mask to eliminate noisy pairs of coordinates to estimate more accurate warping parameters. Extensive experiments on our STRAT dataset demonstrate that our proposed CorrelNet performs more favorably against previous methods.
CcHarmony: Color-checker based Image Harmonization Dataset
Jun 01, 2022
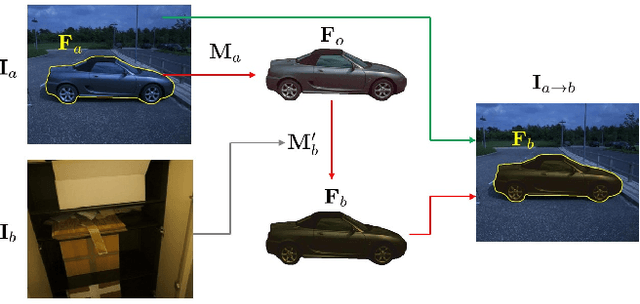

Image harmonization targets at adjusting the foreground in a composite image to make it compatible with the background, producing a more realistic and harmonious image. Training deep image harmonization network requires abundant training data, but it is extremely difficult to acquire training pairs of composite images and ground-truth harmonious images. Therefore, existing works turn to adjust the foreground appearance in a real image to create a synthetic composite image. However, such adjustment may not faithfully reflect the natural illumination change of foreground. In this work, we explore a novel transitive way to construct image harmonization dataset. Specifically, based on the existing datasets with recorded illumination information, we first convert the foreground in a real image to the standard illumination condition, and then convert it to another illumination condition, which is combined with the original background to form a synthetic composite image. In this manner, we construct an image harmonization dataset called ccHarmony, which is named after color checker (cc). The dataset is available at https://github.com/bcmi/Image-Harmonization-Dataset-ccHarmony.
From Representation to Reasoning: Towards both Evidence and Commonsense Reasoning for Video Question-Answering
May 30, 2022
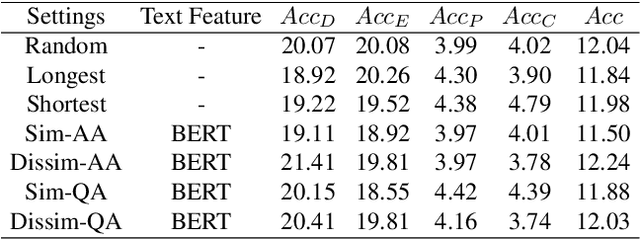

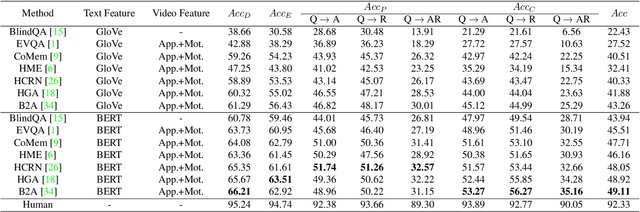
Video understanding has achieved great success in representation learning, such as video caption, video object grounding, and video descriptive question-answer. However, current methods still struggle on video reasoning, including evidence reasoning and commonsense reasoning. To facilitate deeper video understanding towards video reasoning, we present the task of Causal-VidQA, which includes four types of questions ranging from scene description (description) to evidence reasoning (explanation) and commonsense reasoning (prediction and counterfactual). For commonsense reasoning, we set up a two-step solution by answering the question and providing a proper reason. Through extensive experiments on existing VideoQA methods, we find that the state-of-the-art methods are strong in descriptions but weak in reasoning. We hope that Causal-VidQA can guide the research of video understanding from representation learning to deeper reasoning. The dataset and related resources are available at \url{https://github.com/bcmi/Causal-VidQA.git}.
Fast Object Placement Assessment
May 28, 2022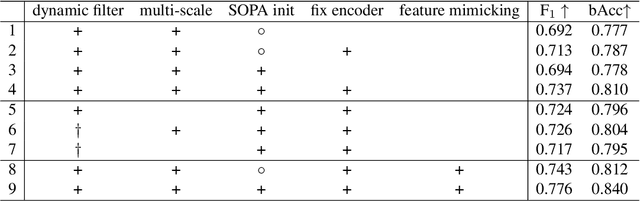
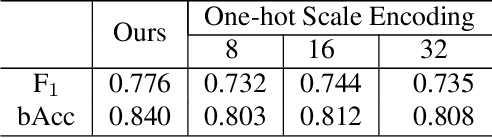
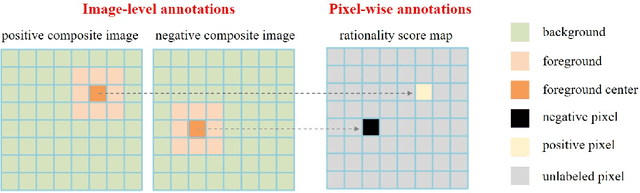

Object placement assessment (OPA) aims to predict the rationality score of a composite image in terms of the placement (e.g., scale, location) of inserted foreground object. However, given a pair of scaled foreground and background, to enumerate all the reasonable locations, existing OPA model needs to place the foreground at each location on the background and pass the obtained composite image through the model one at a time, which is very time-consuming. In this work, we investigate a new task named as fast OPA. Specifically, provided with a scaled foreground and a background, we only pass them through the model once and predict the rationality scores for all locations. To accomplish this task, we propose a pioneering fast OPA model with several innovations (i.e., foreground dynamic filter, background prior transfer, and composite feature mimicking) to bridge the performance gap between slow OPA model and fast OPA model. Extensive experiments on OPA dataset show that our proposed fast OPA model performs on par with slow OPA model but runs significantly faster.