 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRdSOBA: Rendered Shadow-Object Association Dataset
Jun 30, 2023



Image composition refers to inserting a foreground object into a background image to obtain a composite image. In this work, we focus on generating plausible shadows for the inserted foreground object to make the composite image more realistic. To supplement the existing small-scale dataset DESOBA, we created a large-scale dataset called RdSOBA with 3D rendering techniques. Specifically, we place a group of 3D objects in the 3D scene, and get the images without or with object shadows using controllable rendering techniques. Dataset is available at https://github.com/bcmi/Rendered-Shadow-Generation-Dataset-RdSOBA.
WeditGAN: Few-shot Image Generation via Latent Space Relocation
May 11, 2023In few-shot image generation, directly training GAN models on just a handful of images faces the risk of overfitting. A popular solution is to transfer the models pretrained on large source domains to small target ones. In this work, we introduce WeditGAN, which realizes model transfer by editing the intermediate latent codes $w$ in StyleGANs with learned constant offsets ($\Delta w$), discovering and constructing target latent spaces via simply relocating the distribution of source latent spaces. The established one-to-one mapping between latent spaces can naturally prevents mode collapse and overfitting. Besides, we also propose variants of WeditGAN to further enhance the relocation process by regularizing the direction or finetuning the intensity of $\Delta w$. Experiments on a collection of widely used source/target datasets manifest the capability of WeditGAN in generating realistic and diverse images, which is simple yet highly effective in the research area of few-shot image generation.
Few-Shot Defect Image Generation via Defect-Aware Feature Manipulation
Mar 04, 2023The performances of defect inspection have been severely hindered by insufficient defect images in industries, which can be alleviated by generating more samples as data augmentation. We propose the first defect image generation method in the challenging few-shot cases. Given just a handful of defect images and relatively more defect-free ones, our goal is to augment the dataset with new defect images. Our method consists of two training stages. First, we train a data-efficient StyleGAN2 on defect-free images as the backbone. Second, we attach defect-aware residual blocks to the backbone, which learn to produce reasonable defect masks and accordingly manipulate the features within the masked regions by training the added modules on limited defect images. Extensive experiments on MVTec AD dataset not only validate the effectiveness of our method in generating realistic and diverse defect images, but also manifest the benefits it brings to downstream defect inspection tasks. Codes are available at https://github.com/Ldhlwh/DFMGAN.
Painterly Image Harmonization in Dual Domains
Dec 20, 2022



Image harmonization aims to produce visually harmonious composite images by adjusting the foreground appearance to be compatible with the background. When the composite image has photographic foreground and painterly background, the task is called painterly image harmonization. There are only few works on this task, which are either time-consuming or weak in generating well-harmonized results. In this work, we propose a novel painterly harmonization network consisting of a dual-domain generator and a dual-domain discriminator, which harmonizes the composite image in both spatial domain and frequency domain. The dual-domain generator performs harmonization by using AdaIn modules in the spatial domain and our proposed ResFFT modules in the frequency domain. The dual-domain discriminator attempts to distinguish the inharmonious patches based on the spatial feature and frequency feature of each patch, which can enhance the ability of generator in an adversarial manner. Extensive experiments on the benchmark dataset show the effectiveness of our method. Our code and model are available at https://github.com/bcmi/PHDNet-Painterly-Image-Harmonization.
Video Object of Interest Segmentation
Dec 06, 2022



In this work, we present a new computer vision task named video object of interest segmentation (VOIS). Given a video and a target image of interest, our objective is to simultaneously segment and track all objects in the video that are relevant to the target image. This problem combines the traditional video object segmentation task with an additional image indicating the content that users are concerned with. Since no existing dataset is perfectly suitable for this new task, we specifically construct a large-scale dataset called LiveVideos, which contains 2418 pairs of target images and live videos with instance-level annotations. In addition, we propose a transformer-based method for this task. We revisit Swin Transformer and design a dual-path structure to fuse video and image features. Then, a transformer decoder is employed to generate object proposals for segmentation and tracking from the fused features. Extensive experiments on LiveVideos dataset show the superiority of our proposed method.
Weak-shot Semantic Segmentation via Dual Similarity Transfer
Oct 05, 2022
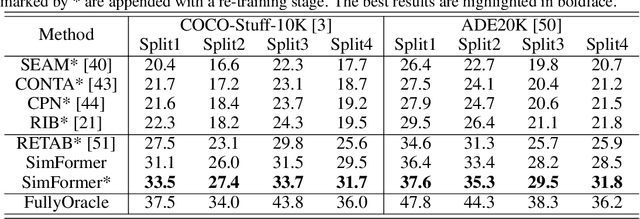
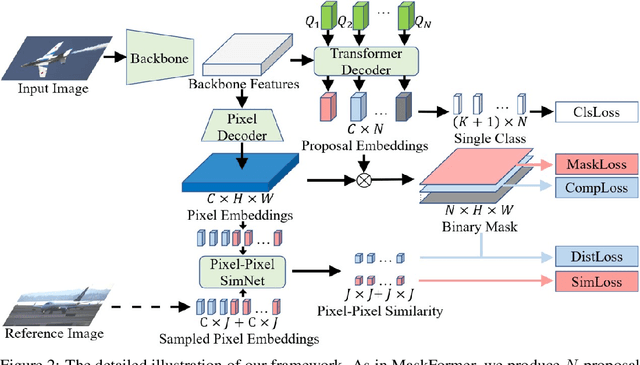
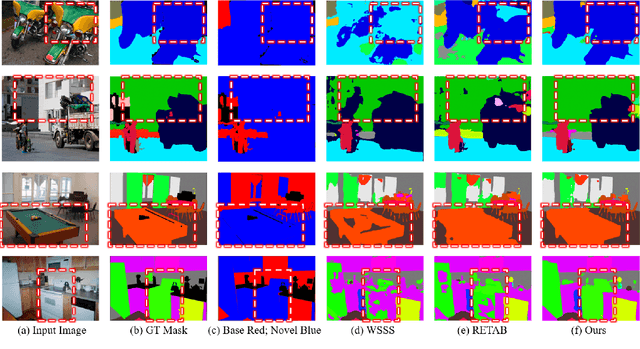
Semantic segmentation is an important and prevalent task, but severely suffers from the high cost of pixel-level annotations when extending to more classes in wider applications. To this end, we focus on the problem named weak-shot semantic segmentation, where the novel classes are learnt from cheaper image-level labels with the support of base classes having off-the-shelf pixel-level labels. To tackle this problem, we propose SimFormer, which performs dual similarity transfer upon MaskFormer. Specifically, MaskFormer disentangles the semantic segmentation task into two sub-tasks: proposal classification and proposal segmentation for each proposal. Proposal segmentation allows proposal-pixel similarity transfer from base classes to novel classes, which enables the mask learning of novel classes. We also learn pixel-pixel similarity from base classes and distill such class-agnostic semantic similarity to the semantic masks of novel classes, which regularizes the segmentation model with pixel-level semantic relationship across images. In addition, we propose a complementary loss to facilitate the learning of novel classes. Comprehensive experiments on the challenging COCO-Stuff-10K and ADE20K datasets demonstrate the effectiveness of our method. Codes are available at https://github.com/bcmi/SimFormer-Weak-Shot-Semantic-Segmentation.
Inharmonious Region Localization via Recurrent Self-Reasoning
Oct 05, 2022
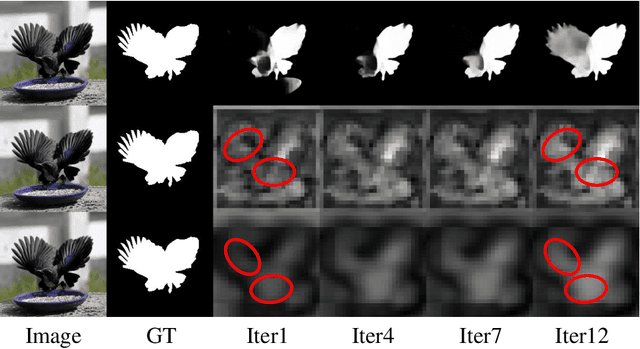
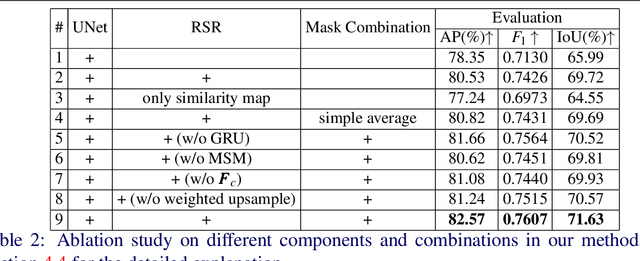
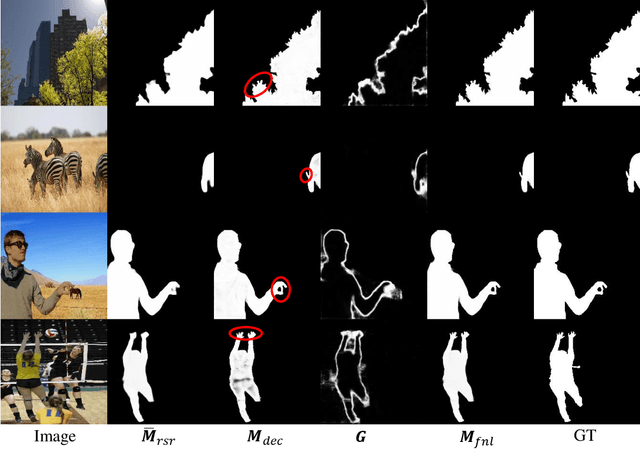
Synthetic images created by image editing operations are prevalent, but the color or illumination inconsistency between the manipulated region and background may make it unrealistic. Thus, it is important yet challenging to localize the inharmonious region to improve the quality of synthetic image. Inspired by the classic clustering algorithm, we aim to group pixels into two clusters: inharmonious cluster and background cluster by inserting a novel Recurrent Self-Reasoning (RSR) module into the bottleneck of UNet structure. The mask output from RSR module is provided for the decoder as attention guidance. Finally, we adaptively combine the masks from RSR and the decoder to form our final mask. Experimental results on the image harmonization dataset demonstrate that our method achieves competitive performance both quantitatively and qualitatively.
Inharmonious Region Localization with Auxiliary Style Feature
Oct 05, 2022

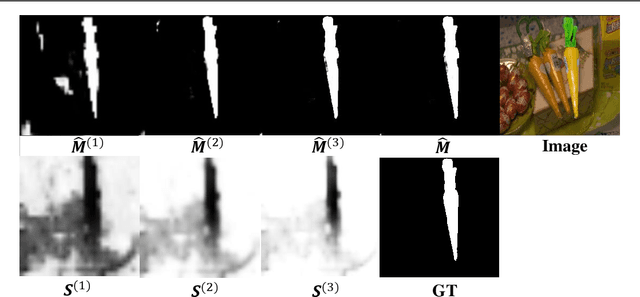
With the prevalence of image editing techniques, users can create fantastic synthetic images, but the image quality may be compromised by the color/illumination discrepancy between the manipulated region and background. Inharmonious region localization aims to localize the inharmonious region in a synthetic image. In this work, we attempt to leverage auxiliary style feature to facilitate this task. Specifically, we propose a novel color mapping module and a style feature loss to extract discriminative style features containing task-relevant color/illumination information. Based on the extracted style features, we also propose a novel style voting module to guide the localization of inharmonious region. Moreover, we introduce semantic information into the style voting module to achieve further improvement. Our method surpasses the existing methods by a large margin on the benchmark dataset.
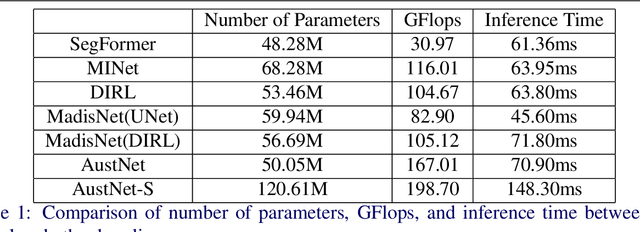
Inharmonious Region Localization by Magnifying Domain Discrepancy
Sep 30, 2022
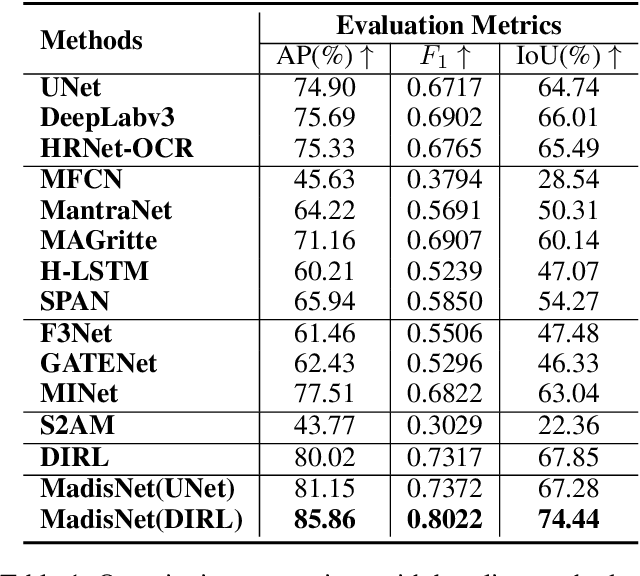
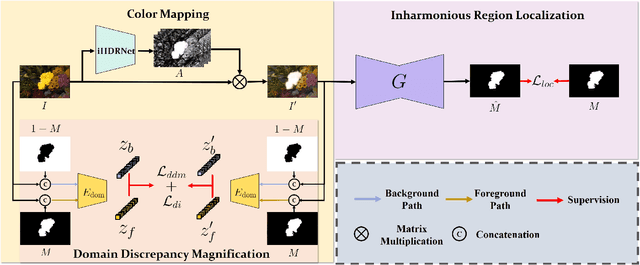
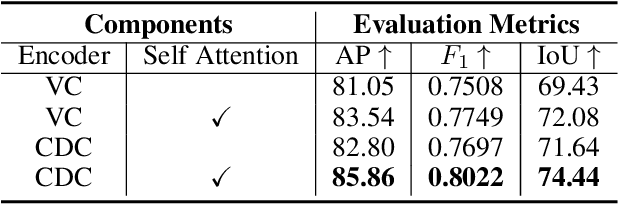
Inharmonious region localization aims to localize the region in a synthetic image which is incompatible with surrounding background. The inharmony issue is mainly attributed to the color and illumination inconsistency produced by image editing techniques. In this work, we tend to transform the input image to another color space to magnify the domain discrepancy between inharmonious region and background, so that the model can identify the inharmonious region more easily. To this end, we present a novel framework consisting of a color mapping module and an inharmonious region localization network, in which the former is equipped with a novel domain discrepancy magnification loss and the latter could be an arbitrary localization network. Extensive experiments on image harmonization dataset show the superiority of our designed framework. Our code is available at https://github.com/bcmi/MadisNet-Inharmonious-Region-Localization.
DeltaGAN: Towards Diverse Few-shot Image Generation with Sample-Specific Delta
Jul 28, 2022

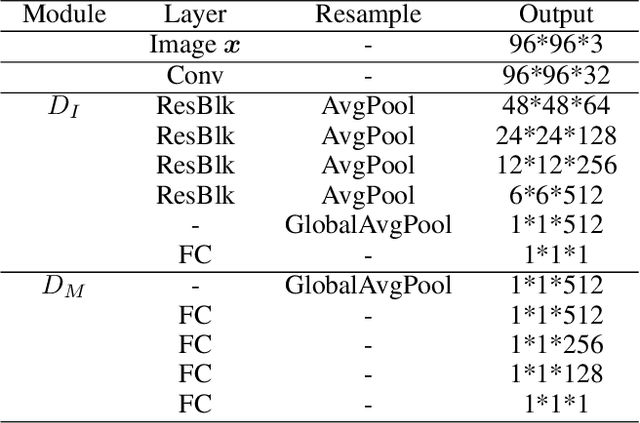

Learning to generate new images for a novel category based on only a few images, named as few-shot image generation, has attracted increasing research interest. Several state-of-the-art works have yielded impressive results, but the diversity is still limited. In this work, we propose a novel Delta Generative Adversarial Network (DeltaGAN), which consists of a reconstruction subnetwork and a generation subnetwork. The reconstruction subnetwork captures intra-category transformation, i.e., delta, between same-category pairs. The generation subnetwork generates sample-specific delta for an input image, which is combined with this input image to generate a new image within the same category. Besides, an adversarial delta matching loss is designed to link the above two subnetworks together. Extensive experiments on six benchmark datasets demonstrate the effectiveness of our proposed method. Our code is available at https://github.com/bcmi/DeltaGAN-Few-Shot-Image-Generation.