 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Captions to Visual Concepts and Back
Apr 14, 2015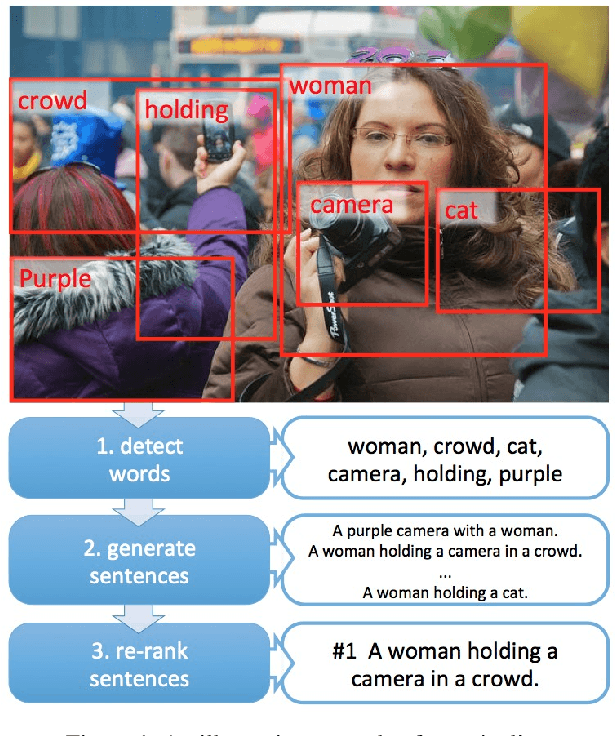

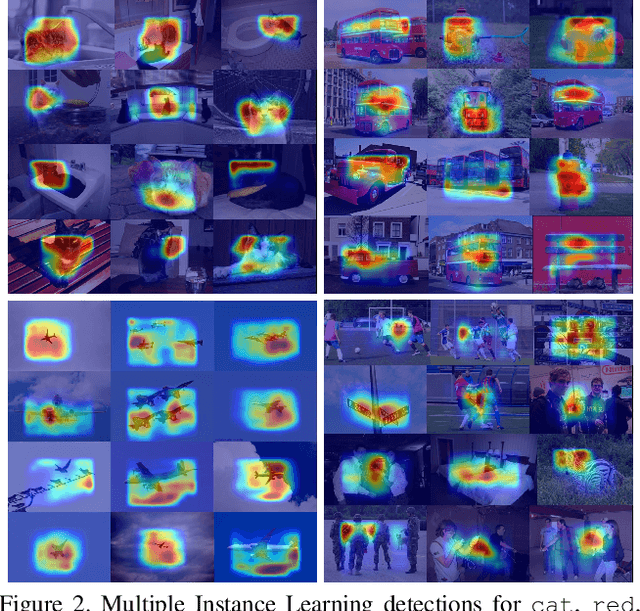

This paper presents a novel approach for automatically generating image descriptions: visual detectors, language models, and multimodal similarity models learnt directly from a dataset of image captions. We use multiple instance learning to train visual detectors for words that commonly occur in captions, including many different parts of speech such as nouns, verbs, and adjectives. The word detector outputs serve as conditional inputs to a maximum-entropy language model. The language model learns from a set of over 400,000 image descriptions to capture the statistics of word usage. We capture global semantics by re-ranking caption candidates using sentence-level features and a deep multimodal similarity model. Our system is state-of-the-art on the official Microsoft COCO benchmark, producing a BLEU-4 score of 29.1%. When human judges compare the system captions to ones written by other people on our held-out test set, the system captions have equal or better quality 34% of the time.
Learning Multi-Relational Semantics Using Neural-Embedding Models
Nov 14, 2014
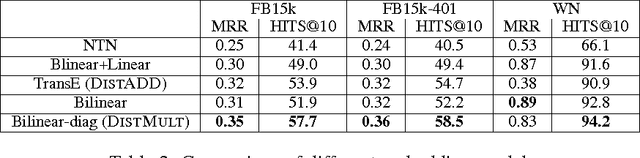
In this paper we present a unified framework for modeling multi-relational representations, scoring, and learning, and conduct an empirical study of several recent multi-relational embedding models under the framework. We investigate the different choices of relation operators based on linear and bilinear transformations, and also the effects of entity representations by incorporating unsupervised vectors pre-trained on extra textual resources. Our results show several interesting findings, enabling the design of a simple embedding model that achieves the new state-of-the-art performance on a popular knowledge base completion task evaluated on Freebase.
A Primal-Dual Method for Training Recurrent Neural Networks Constrained by the Echo-State Property
Mar 06, 2014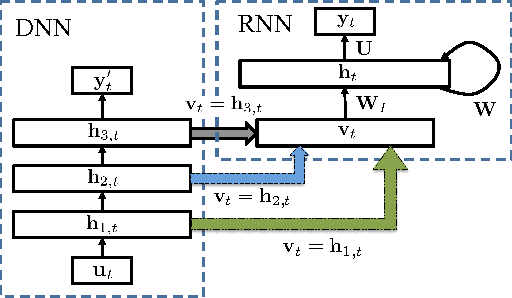
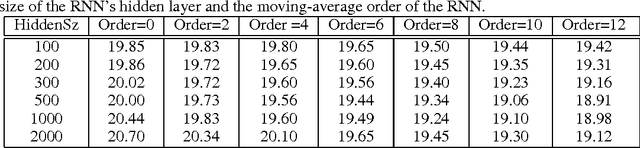
We present an architecture of a recurrent neural network (RNN) with a fully-connected deep neural network (DNN) as its feature extractor. The RNN is equipped with both causal temporal prediction and non-causal look-ahead, via auto-regression (AR) and moving-average (MA), respectively. The focus of this paper is a primal-dual training method that formulates the learning of the RNN as a formal optimization problem with an inequality constraint that provides a sufficient condition for the stability of the network dynamics. Experimental results demonstrate the effectiveness of this new method, which achieves 18.86% phone recognition error on the TIMIT benchmark for the core test set. The result approaches the best result of 17.7%, which was obtained by using RNN with long short-term memory (LSTM). The results also show that the proposed primal-dual training method produces lower recognition errors than the popular RNN methods developed earlier based on the carefully tuned threshold parameter that heuristically prevents the gradient from exploding.
Learning Semantic Representations for the Phrase Translation Model
Nov 28, 2013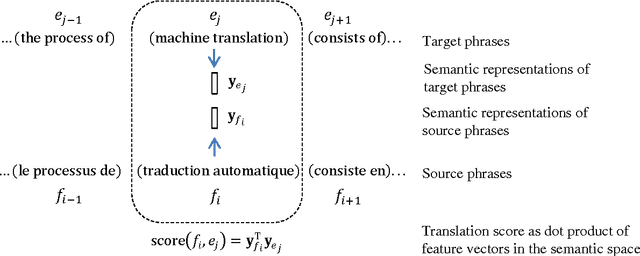
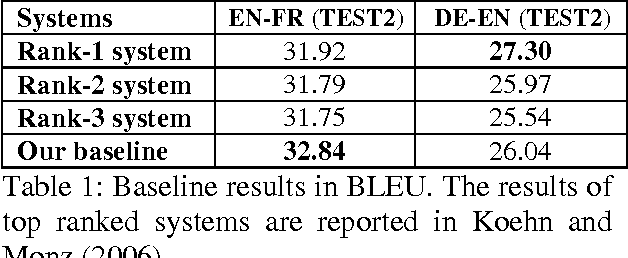
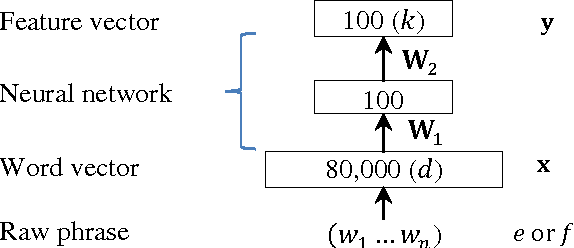
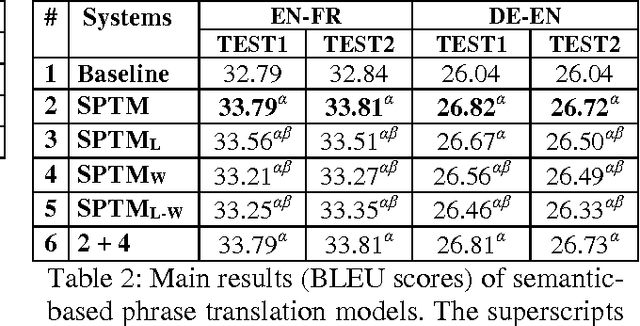
This paper presents a novel semantic-based phrase translation model. A pair of source and target phrases are projected into continuous-valued vector representations in a low-dimensional latent semantic space, where their translation score is computed by the distance between the pair in this new space. The projection is performed by a multi-layer neural network whose weights are learned on parallel training data. The learning is aimed to directly optimize the quality of end-to-end machine translation results. Experimental evaluation has been performed on two Europarl translation tasks, English-French and German-English. The results show that the new semantic-based phrase translation model significantly improves the performance of a state-of-the-art phrase-based statistical machine translation sys-tem, leading to a gain of 0.7-1.0 BLEU points.
Learning Input and Recurrent Weight Matrices in Echo State Networks
Nov 13, 2013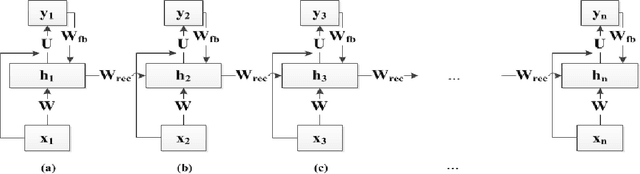
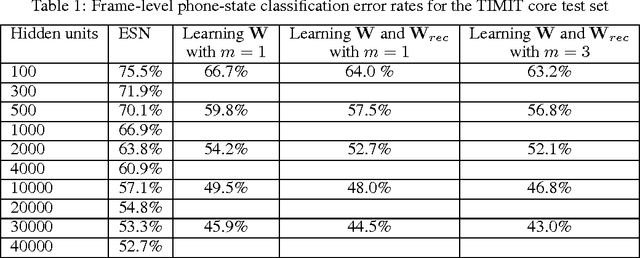
Echo State Networks (ESNs) are a special type of the temporally deep network model, the Recurrent Neural Network (RNN), where the recurrent matrix is carefully designed and both the recurrent and input matrices are fixed. An ESN uses the linearity of the activation function of the output units to simplify the learning of the output matrix. In this paper, we devise a special technique that take advantage of this linearity in the output units of an ESN, to learn the input and recurrent matrices. This has not been done in earlier ESNs due to their well known difficulty in learning those matrices. Compared to the technique of BackPropagation Through Time (BPTT) in learning general RNNs, our proposed method exploits linearity of activation function in the output units to formulate the relationships amongst the various matrices in an RNN. These relationships results in the gradient of the cost function having an analytical form and being more accurate. This would enable us to compute the gradients instead of obtaining them by recursion as in BPTT. Experimental results on phone state classification show that learning one or both the input and recurrent matrices in an ESN yields superior results compared to traditional ESNs that do not learn these matrices, especially when longer time steps are used.