 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction2Motion: Conditioned Generation of 3D Human Motions
Jul 30, 2020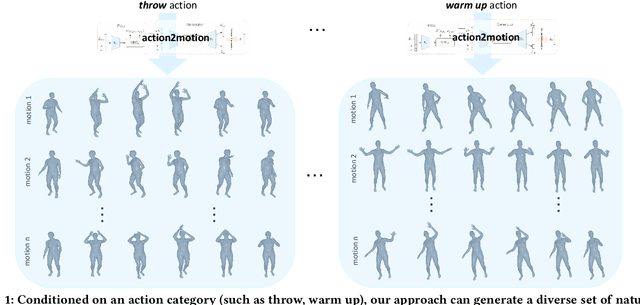
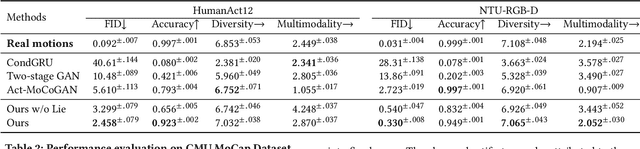
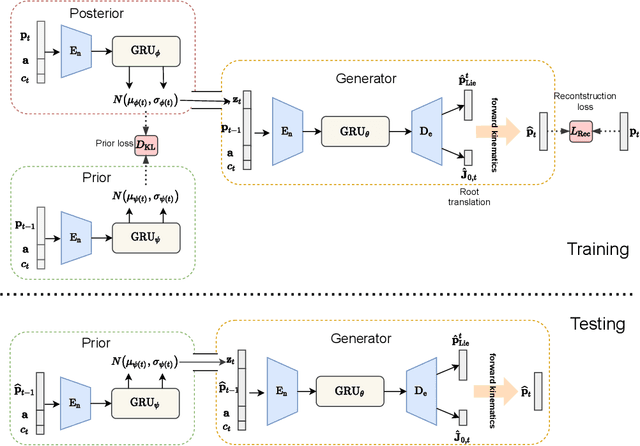
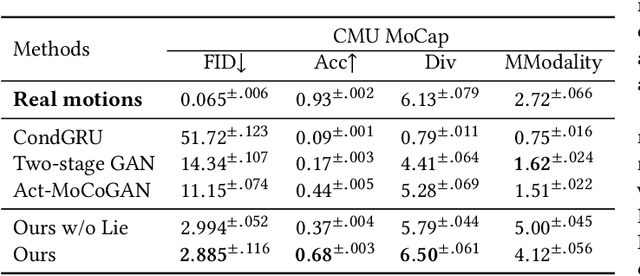
Action recognition is a relatively established task, where givenan input sequence of human motion, the goal is to predict its ac-tion category. This paper, on the other hand, considers a relativelynew problem, which could be thought of as an inverse of actionrecognition: given a prescribed action type, we aim to generateplausible human motion sequences in 3D. Importantly, the set ofgenerated motions are expected to maintain itsdiversityto be ableto explore the entire action-conditioned motion space; meanwhile,each sampled sequence faithfully resembles anaturalhuman bodyarticulation dynamics. Motivated by these objectives, we followthe physics law of human kinematics by adopting the Lie Algebratheory to represent thenaturalhuman motions; we also propose atemporal Variational Auto-Encoder (VAE) that encourages adiversesampling of the motion space. A new 3D human motion dataset, HumanAct12, is also constructed. Empirical experiments overthree distinct human motion datasets (including ours) demonstratethe effectiveness of our approach.
3D Human Shape Reconstruction from a Polarization Image
Jul 17, 2020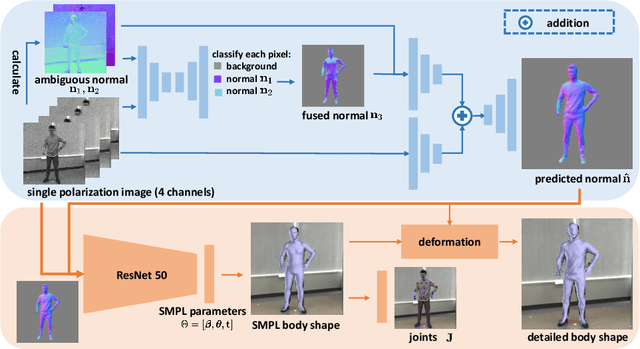
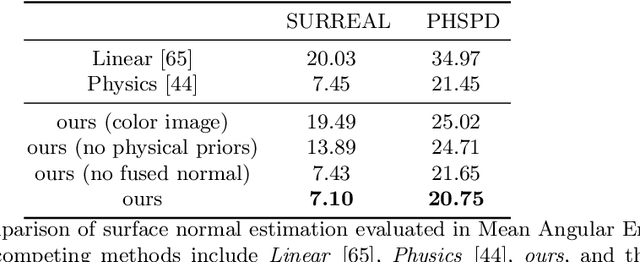


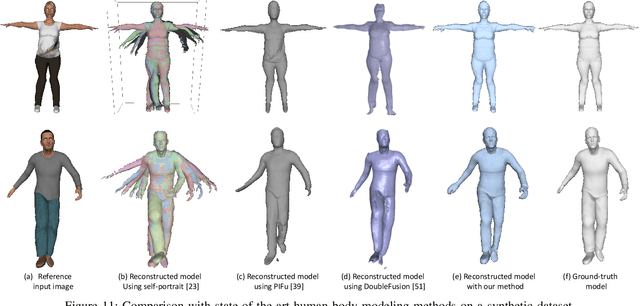
This paper tackles the problem of estimating 3D body shape of clothed humans from single polarized 2D images, i.e. polarization images. Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing surface normal of the objects of interest. Inspired by the recent advances in human shape estimation from single color images, in this paper, we attempt at estimating human body shapes by leveraging the geometric cues from single polarization images. A dedicated two-stage deep learning approach, SfP, is proposed: given a polarization image, stage one aims at inferring the fined-detailed body surface normal; stage two gears to reconstruct the 3D body shape of clothing details. Empirical evaluations on a synthetic dataset (SURREAL) as well as a real-world dataset (PHSPD) demonstrate the qualitative and quantitative performance of our approach in estimating human poses and shapes. This indicates polarization camera is a promising alternative to the more conventional color or depth imaging for human shape estimation. Further, normal maps inferred from polarization imaging play a significant role in accurately recovering the body shapes of clothed people.
SparseFusion: Dynamic Human Avatar Modeling from Sparse RGBD Images
Jun 05, 2020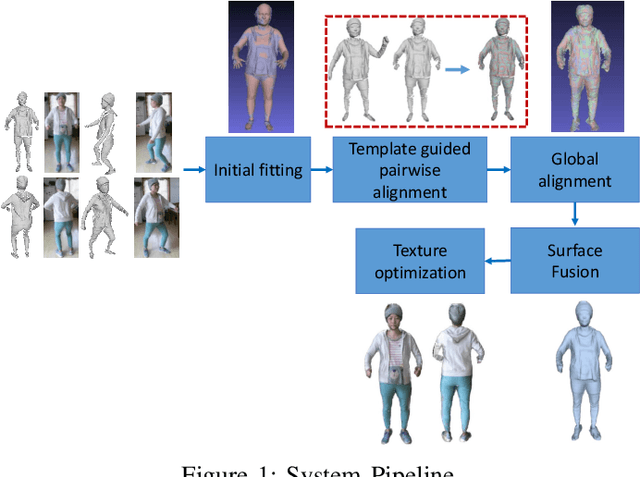

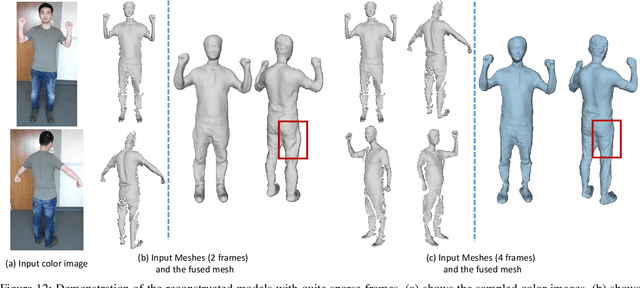
In this paper, we propose a novel approach to reconstruct 3D human body shapes based on a sparse set of RGBD frames using a single RGBD camera. We specifically focus on the realistic settings where human subjects move freely during the capture. The main challenge is how to robustly fuse these sparse frames into a canonical 3D model, under pose changes and surface occlusions. This is addressed by our new framework consisting of the following steps. First, based on a generative human template, for every two frames having sufficient overlap, an initial pairwise alignment is performed; It is followed by a global non-rigid registration procedure, in which partial results from RGBD frames are collected into a unified 3D shape, under the guidance of correspondences from the pairwise alignment; Finally, the texture map of the reconstructed human model is optimized to deliver a clear and spatially consistent texture. Empirical evaluations on synthetic and real datasets demonstrate both quantitatively and qualitatively the superior performance of our framework in reconstructing complete 3D human models with high fidelity. It is worth noting that our framework is flexible, with potential applications going beyond shape reconstruction. As an example, we showcase its use in reshaping and reposing to a new avatar.
COMET: Context-Aware IoU-Guided Network for Small Object Tracking
Jun 04, 2020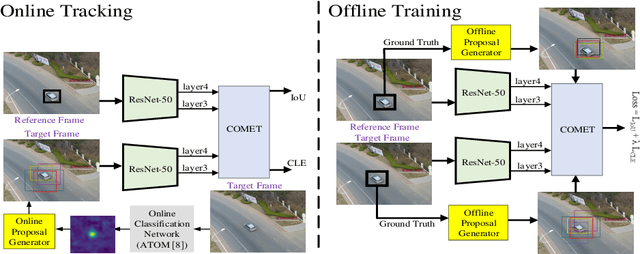
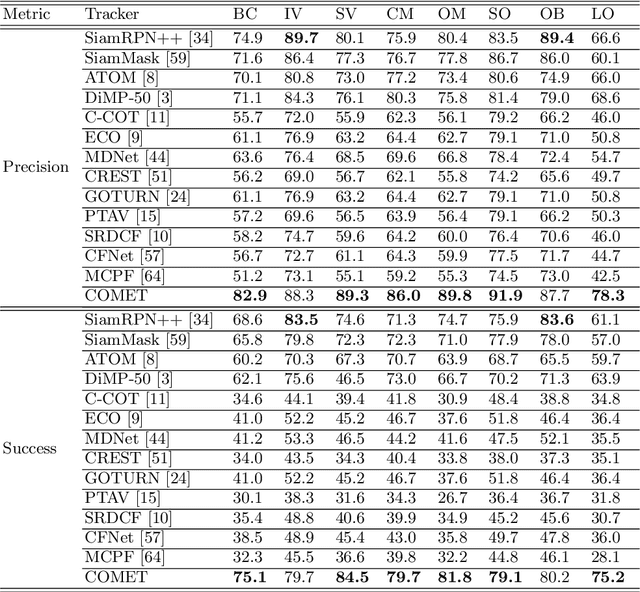
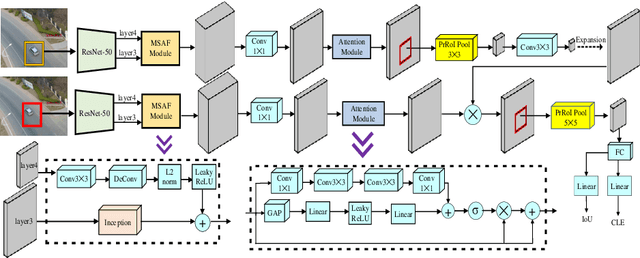
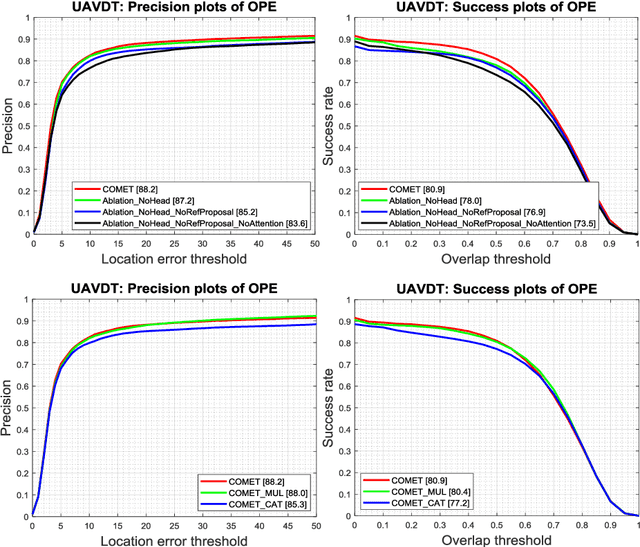
Tracking an unknown target captured from medium- or high-aerial view is challenging, especially in scenarios of small objects, large viewpoint change, drastic camera motion, and high density. This paper introduces a context-aware IoU-guided tracker that exploits an offline reference proposal generation strategy and a multitask two-stream network. The proposed strategy introduces an efficient sampling strategy to generalize the network on the target and its parts without imposing extra computational complexity during online tracking. It considerably helps the proposed tracker, COMET, to handle occlusion and view-point change, where only some parts of the target are visible. Extensive experimental evaluations on broad range of small object benchmarks (UAVDT, VisDrone-2019, and Small-90) demonstrate the effectiveness of our approach for small object tracking.
Polarization Human Shape and Pose Dataset
Apr 30, 2020


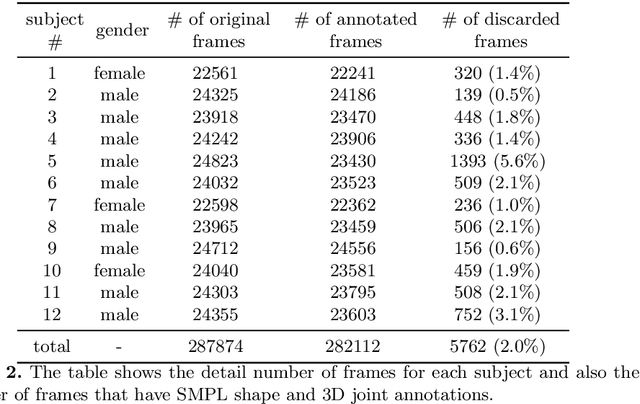
Polarization images are known to be able to capture polarized reflected lights that preserve rich geometric cues of an object, which has motivated its recent applications in reconstructing detailed surface normal of the objects of interest. Meanwhile, inspired by the recent breakthroughs in human shape estimation from a single color image, we attempt to investigate the new question of whether the geometric cues from polarization camera could be leveraged in estimating detailed human body shapes. This has led to the curation of Polarization Human Shape and Pose Dataset (PHSPD)5, our home-grown polarization image dataset of various human shapes and poses.
Stabilizing Training of Generative Adversarial Nets via Langevin Stein Variational Gradient Descent
Apr 22, 2020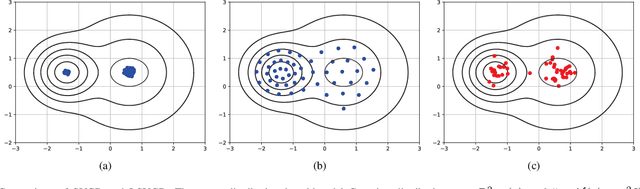
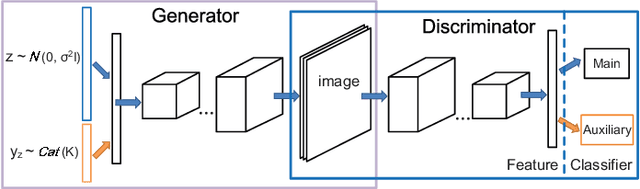
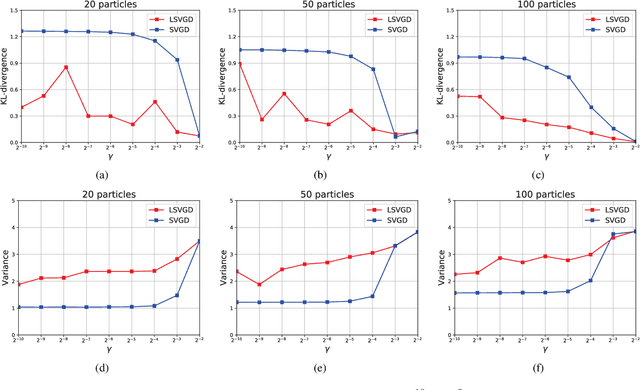
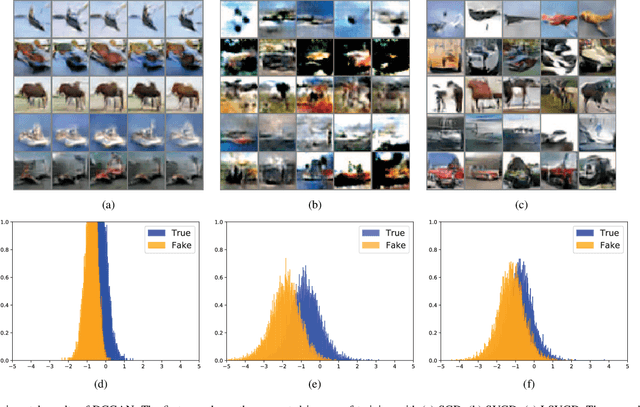
Generative adversarial networks (GANs), famous for the capability of learning complex underlying data distribution, are however known to be tricky in the training process, which would probably result in mode collapse or performance deterioration. Current approaches of dealing with GANs' issues almost utilize some practical training techniques for the purpose of regularization, which on the other hand undermines the convergence and theoretical soundness of GAN. In this paper, we propose to stabilize GAN training via a novel particle-based variational inference -- Langevin Stein variational gradient descent (LSVGD), which not only inherits the flexibility and efficiency of original SVGD but aims to address its instability issues by incorporating an extra disturbance into the update dynamics. We further demonstrate that by properly adjusting the noise variance, LSVGD simulates a Langevin process whose stationary distribution is exactly the target distribution. We also show that LSVGD dynamics has an implicit regularization which is able to enhance particles' spread-out and diversity. At last we present an efficient way of applying particle-based variational inference on a general GAN training procedure no matter what loss function is adopted. Experimental results on one synthetic dataset and three popular benchmark datasets -- Cifar-10, Tiny-ImageNet and CelebA validate that LSVGD can remarkably improve the performance and stability of various GAN models.
Outlier Detection Ensemble with Embedded Feature Selection
Jan 15, 2020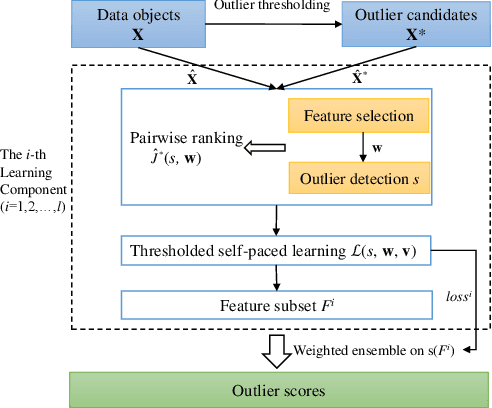
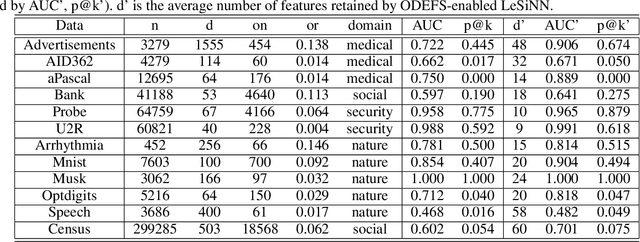
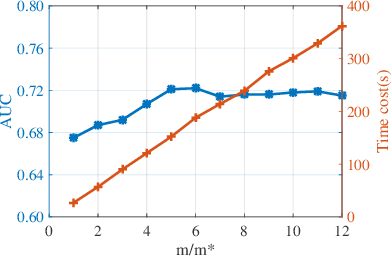
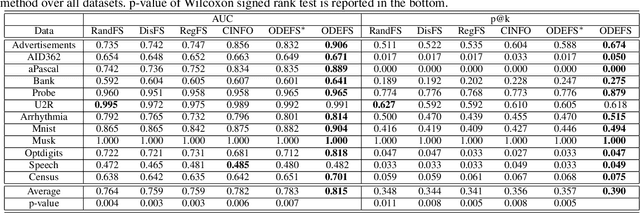
Feature selection places an important role in improving the performance of outlier detection, especially for noisy data. Existing methods usually perform feature selection and outlier scoring separately, which would select feature subsets that may not optimally serve for outlier detection, leading to unsatisfying performance. In this paper, we propose an outlier detection ensemble framework with embedded feature selection (ODEFS), to address this issue. Specifically, for each random sub-sampling based learning component, ODEFS unifies feature selection and outlier detection into a pairwise ranking formulation to learn feature subsets that are tailored for the outlier detection method. Moreover, we adopt the thresholded self-paced learning to simultaneously optimize feature selection and example selection, which is helpful to improve the reliability of the training set. After that, we design an alternate algorithm with proved convergence to solve the resultant optimization problem. In addition, we analyze the generalization error bound of the proposed framework, which provides theoretical guarantee on the method and insightful practical guidance. Comprehensive experimental results on 12 real-world datasets from diverse domains validate the superiority of the proposed ODEFS.
TBC-Net: A real-time detector for infrared small target detection using semantic constraint
Dec 27, 2019
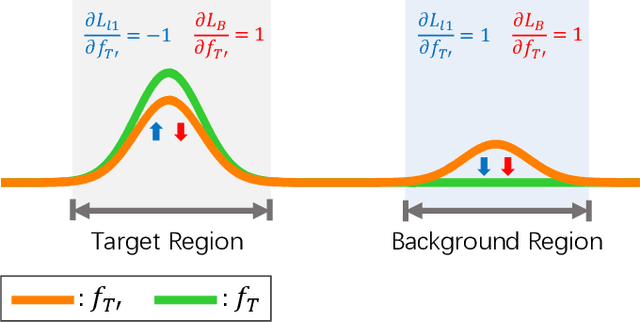
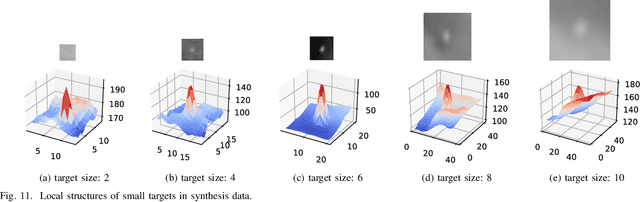
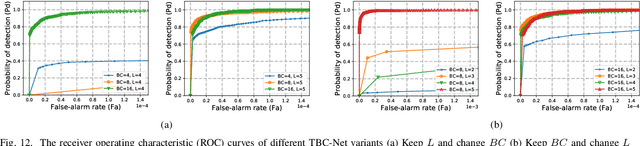
Infrared small target detection is a key technique in infrared search and tracking (IRST) systems. Although deep learning has been widely used in the vision tasks of visible light images recently, it is rarely used in infrared small target detection due to the difficulty in learning small target features. In this paper, we propose a novel lightweight convolutional neural network TBC-Net for infrared small target detection. The TBCNet consists of a target extraction module (TEM) and a semantic constraint module (SCM), which are used to extract small targets from infrared images and to classify the extracted target images during the training, respectively. Meanwhile, we propose a joint loss function and a training method. The SCM imposes a semantic constraint on TEM by combining the high-level classification task and solve the problem of the difficulty to learn features caused by class imbalance problem. During the training, the targets are extracted from the input image and then be classified by SCM. During the inference, only the TEM is used to detect the small targets. We also propose a data synthesis method to generate training data. The experimental results show that compared with the traditional methods, TBC-Net can better reduce the false alarm caused by complicated background, the proposed network structure and joint loss have a significant improvement on small target feature learning. Besides, TBC-Net can achieve real-time detection on the NVIDIA Jetson AGX Xavier development board, which is suitable for applications such as field research with drones equipped with infrared sensors.
Deep Learning for Visual Tracking: A Comprehensive Survey
Dec 02, 2019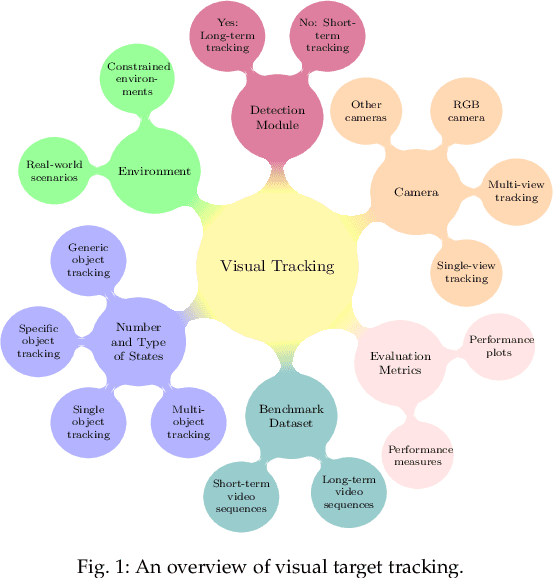
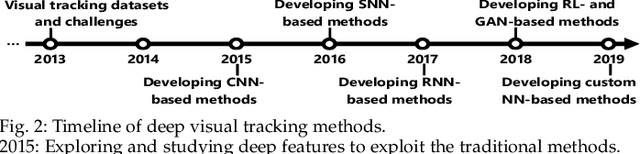
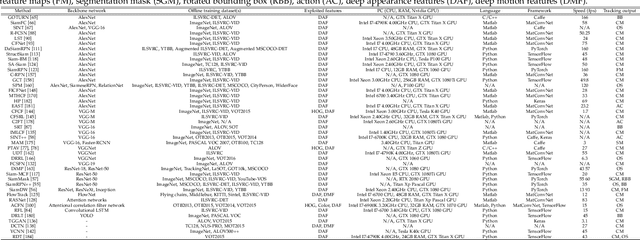
Visual target tracking is one of the most sought-after yet challenging research topics in computer vision. Given the ill-posed nature of the problem and its popularity in a broad range of real-world scenarios, a number of large-scale benchmark datasets have been established, on which considerable methods have been developed and demonstrated with significant progress in recent years -- predominantly by recent deep learning (DL)-based methods. This survey aims to systematically investigate the current DL-based visual tracking methods, benchmark datasets, and evaluation metrics. It also extensively evaluates and analyzes the leading visual tracking methods. First, the fundamental characteristics, primary motivations, and contributions of DL-based methods are summarized from six key aspects of: network architecture, network exploitation, network training for visual tracking, network objective, network output, and the exploitation of correlation filter advantages. Second, popular visual tracking benchmarks and their respective properties are compared, and their evaluation metrics are summarized. Third, the state-of-the-art DL-based methods are comprehensively examined on a set of well-established benchmarks of OTB2013, OTB2015, VOT2018, and LaSOT. Finally, by conducting critical analyses of these state-of-the-art methods both quantitatively and qualitatively, their pros and cons under various common scenarios are investigated. It may serve as a gentle use guide for practitioners to weigh on when and under what conditions to choose which method(s). It also facilitates a discussion on ongoing issues and sheds light on promising research directions.
WaveletKernelNet: An Interpretable Deep Neural Network for Industrial Intelligent Diagnosis
Nov 23, 2019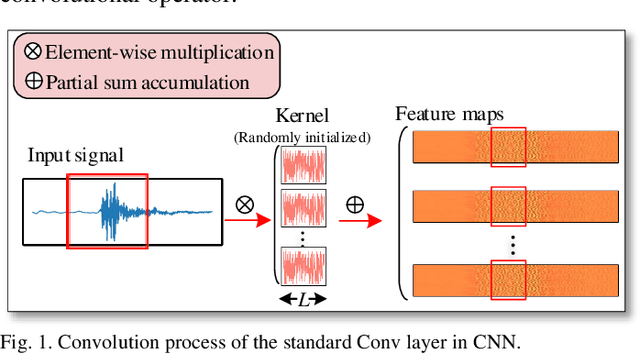

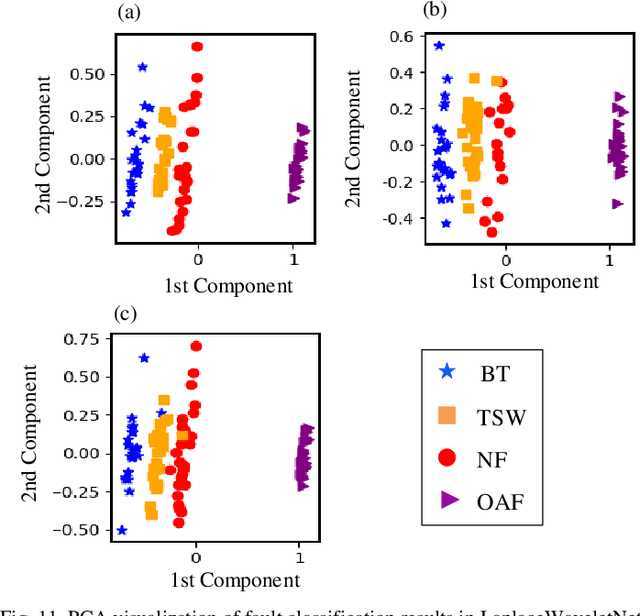
Convolutional neural network (CNN), with ability of feature learning and nonlinear mapping, has demonstrated its effectiveness in prognostics and health management (PHM). However, explanation on the physical meaning of a CNN architecture has rarely been studied. In this paper, a novel wavelet driven deep neural network termed as WaveletKernelNet (WKN) is presented, where a continuous wavelet convolutional (CWConv) layer is designed to replace the first convolutional layer of the standard CNN. This enables the first CWConv layer to discover more meaningful filters. Furthermore, only the scale parameter and translation parameter are directly learned from raw data at this CWConv layer. This provides a very effective way to obtain a customized filter bank, specifically tuned for extracting defect-related impact component embedded in the vibration signal. In addition, three experimental verification using data from laboratory environment are carried out to verify effectiveness of the proposed method for mechanical fault diagnosis. The results show the importance of the designed CWConv layer and the output of CWConv layer is interpretable. Besides, it is found that WKN has fewer parameters, higher fault classification accuracy and faster convergence speed than standard CNN.