 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Can Be Predicted from Six Seconds of Driver Glances?
Nov 26, 2016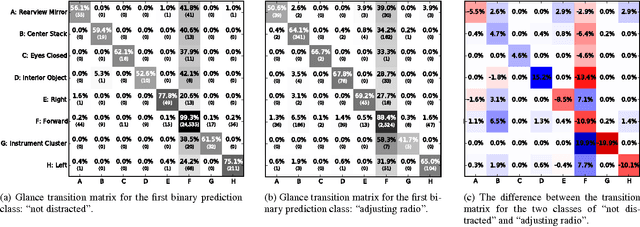
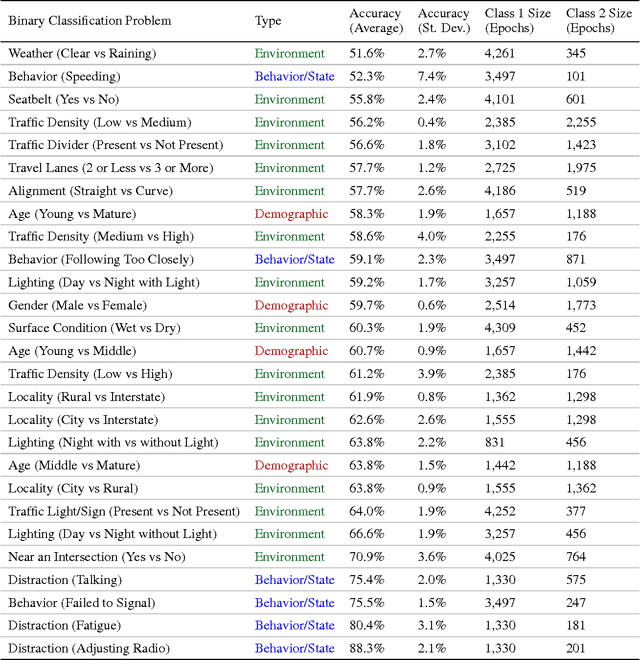

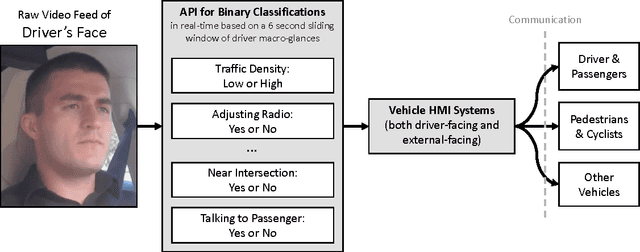
We consider a large dataset of real-world, on-road driving from a 100-car naturalistic study to explore the predictive power of driver glances and, specifically, to answer the following question: what can be predicted about the state of the driver and the state of the driving environment from a 6-second sequence of macro-glances? The context-based nature of such glances allows for application of supervised learning to the problem of vision-based gaze estimation, making it robust, accurate, and reliable in messy, real-world conditions. So, it's valuable to ask whether such macro-glances can be used to infer behavioral, environmental, and demographic variables? We analyze 27 binary classification problems based on these variables. The takeaway is that glance can be used as part of a multi-sensor real-time system to predict radio-tuning, fatigue state, failure to signal, talking, and several environment variables.
Owl and Lizard: Patterns of Head Pose and Eye Pose in Driver Gaze Classification
Nov 20, 2016
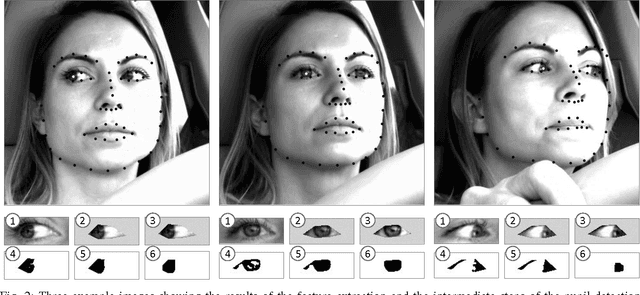

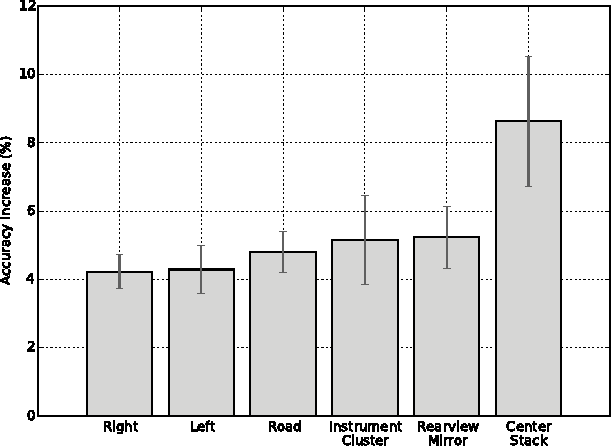
Accurate, robust, inexpensive gaze tracking in the car can help keep a driver safe by facilitating the more effective study of how to improve (1) vehicle interfaces and (2) the design of future Advanced Driver Assistance Systems. In this paper, we estimate head pose and eye pose from monocular video using methods developed extensively in prior work and ask two new interesting questions. First, how much better can we classify driver gaze using head and eye pose versus just using head pose? Second, are there individual-specific gaze strategies that strongly correlate with how much gaze classification improves with the addition of eye pose information? We answer these questions by evaluating data drawn from an on-road study of 40 drivers. The main insight of the paper is conveyed through the analogy of an "owl" and "lizard" which describes the degree to which the eyes and the head move when shifting gaze. When the head moves a lot ("owl"), not much classification improvement is attained by estimating eye pose on top of head pose. On the other hand, when the head stays still and only the eyes move ("lizard"), classification accuracy increases significantly from adding in eye pose. We characterize how that accuracy varies between people, gaze strategies, and gaze regions.
Learning Human Identity from Motion Patterns
Apr 21, 2016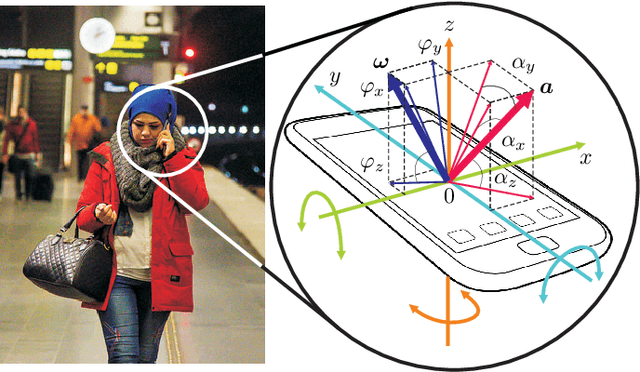
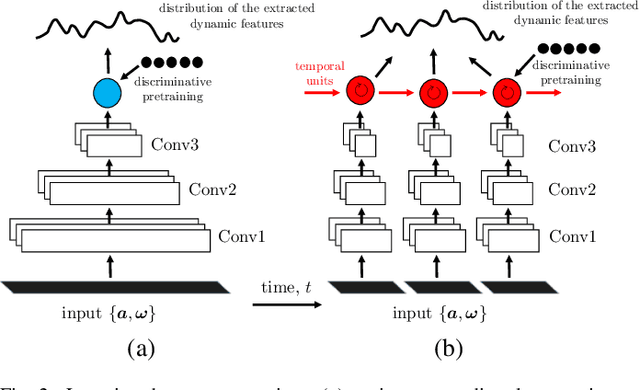
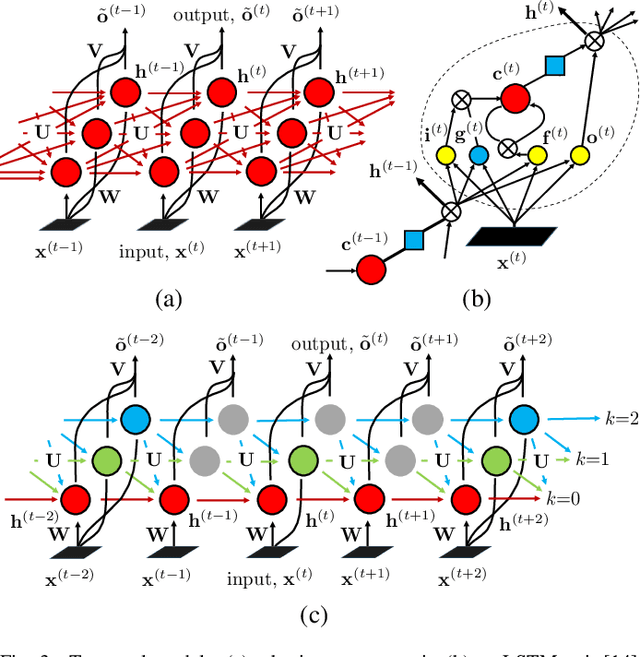
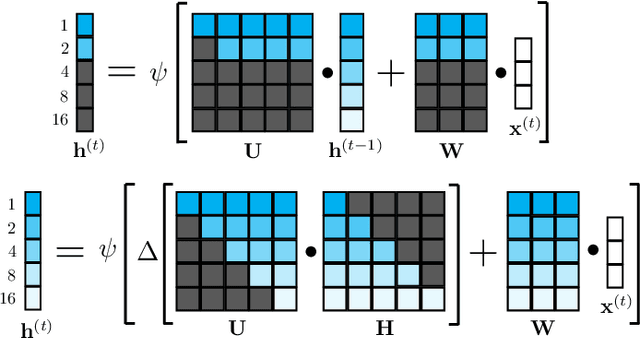
We present a large-scale study exploring the capability of temporal deep neural networks to interpret natural human kinematics and introduce the first method for active biometric authentication with mobile inertial sensors. At Google, we have created a first-of-its-kind dataset of human movements, passively collected by 1500 volunteers using their smartphones daily over several months. We (1) compare several neural architectures for efficient learning of temporal multi-modal data representations, (2) propose an optimized shift-invariant dense convolutional mechanism (DCWRNN), and (3) incorporate the discriminatively-trained dynamic features in a probabilistic generative framework taking into account temporal characteristics. Our results demonstrate that human kinematics convey important information about user identity and can serve as a valuable component of multi-modal authentication systems.
Automated Synchronization of Driving Data Using Vibration and Steering Events
Mar 01, 2016

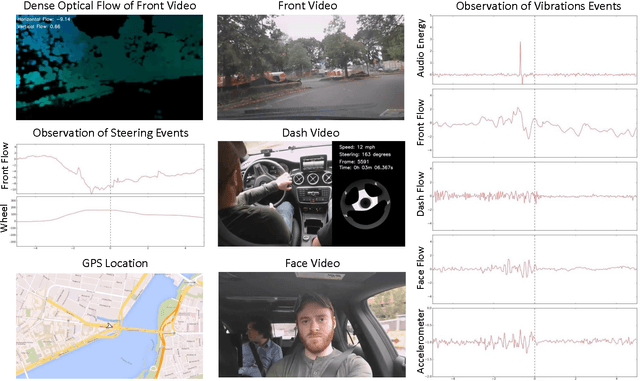
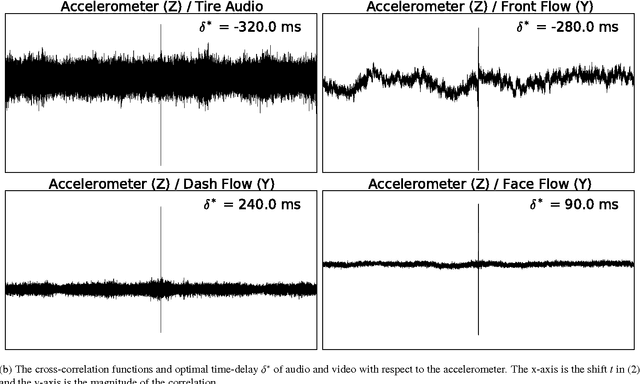
We propose a method for automated synchronization of vehicle sensors useful for the study of multi-modal driver behavior and for the design of advanced driver assistance systems. Multi-sensor decision fusion relies on synchronized data streams in (1) the offline supervised learning context and (2) the online prediction context. In practice, such data streams are often out of sync due to the absence of a real-time clock, use of multiple recording devices, or improper thread scheduling and data buffer management. Cross-correlation of accelerometer, telemetry, audio, and dense optical flow from three video sensors is used to achieve an average synchronization error of 13 milliseconds. The insight underlying the effectiveness of the proposed approach is that the described sensors capture overlapping aspects of vehicle vibrations and vehicle steering allowing the cross-correlation function to serve as a way to compute the delay shift in each sensor. Furthermore, we show the decrease in synchronization error as a function of the duration of the data stream.
Driver Gaze Region Estimation Without Using Eye Movement
Mar 01, 2016
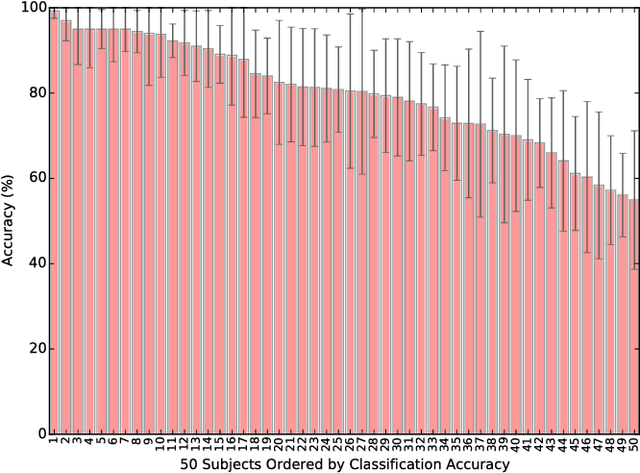
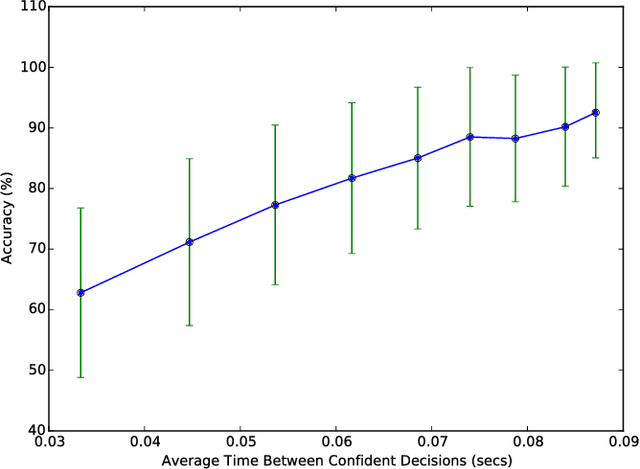
Automated estimation of the allocation of a driver's visual attention may be a critical component of future Advanced Driver Assistance Systems. In theory, vision-based tracking of the eye can provide a good estimate of gaze location. In practice, eye tracking from video is challenging because of sunglasses, eyeglass reflections, lighting conditions, occlusions, motion blur, and other factors. Estimation of head pose, on the other hand, is robust to many of these effects, but cannot provide as fine-grained of a resolution in localizing the gaze. However, for the purpose of keeping the driver safe, it is sufficient to partition gaze into regions. In this effort, we propose a system that extracts facial features and classifies their spatial configuration into six regions in real-time. Our proposed method achieves an average accuracy of 91.4% at an average decision rate of 11 Hz on a dataset of 50 drivers from an on-road study.
Detecting Road Surface Wetness from Audio: A Deep Learning Approach
Dec 04, 2015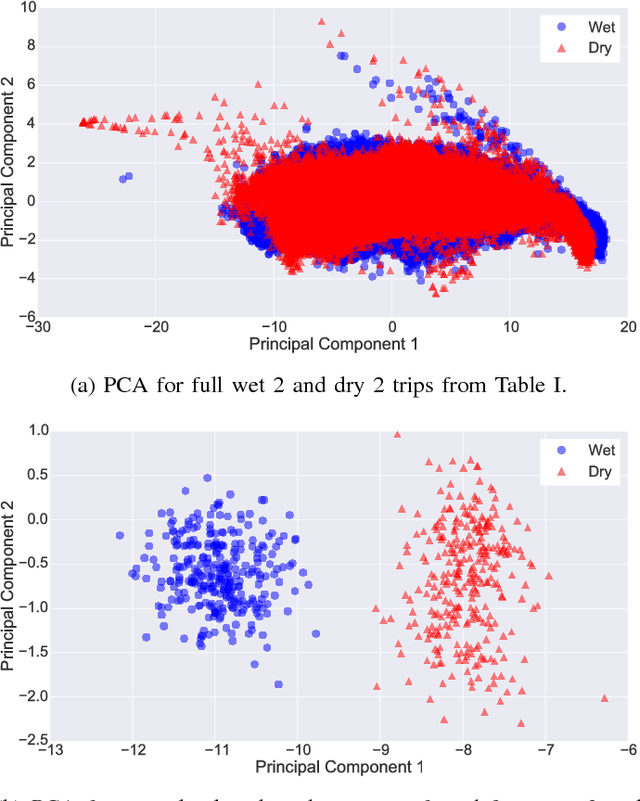


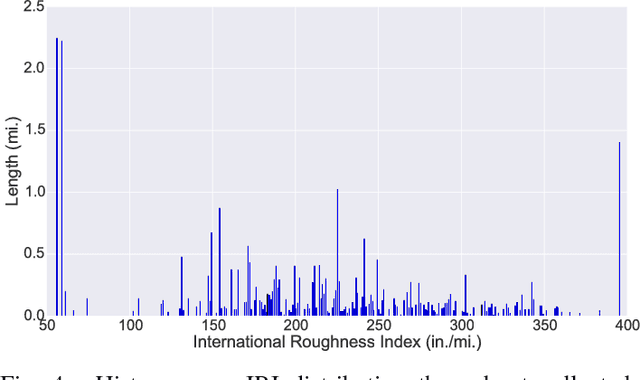
We introduce a recurrent neural network architecture for automated road surface wetness detection from audio of tire-surface interaction. The robustness of our approach is evaluated on 785,826 bins of audio that span an extensive range of vehicle speeds, noises from the environment, road surface types, and pavement conditions including international roughness index (IRI) values from 25 in/mi to 1400 in/mi. The training and evaluation of the model are performed on different roads to minimize the impact of environmental and other external factors on the accuracy of the classification. We achieve an unweighted average recall (UAR) of 93.2% across all vehicle speeds including 0 mph. The classifier still works at 0 mph because the discriminating signal is present in the sound of other vehicles driving by.
Active Authentication on Mobile Devices via Stylometry, Application Usage, Web Browsing, and GPS Location
Mar 29, 2015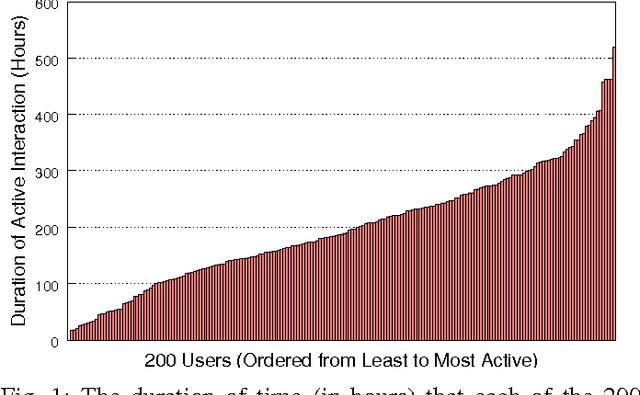
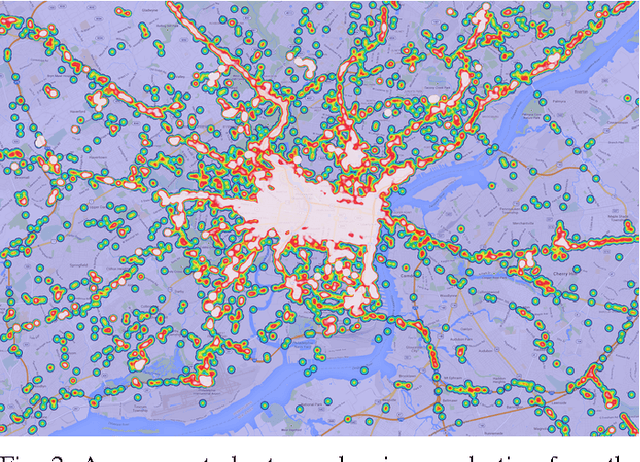
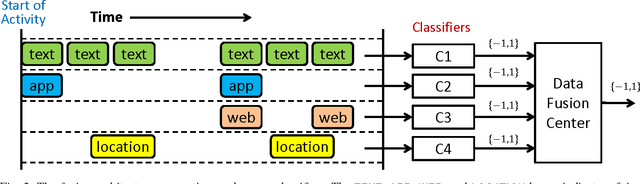

Active authentication is the problem of continuously verifying the identity of a person based on behavioral aspects of their interaction with a computing device. In this study, we collect and analyze behavioral biometrics data from 200subjects, each using their personal Android mobile device for a period of at least 30 days. This dataset is novel in the context of active authentication due to its size, duration, number of modalities, and absence of restrictions on tracked activity. The geographical colocation of the subjects in the study is representative of a large closed-world environment such as an organization where the unauthorized user of a device is likely to be an insider threat: coming from within the organization. We consider four biometric modalities: (1) text entered via soft keyboard, (2) applications used, (3) websites visited, and (4) physical location of the device as determined from GPS (when outdoors) or WiFi (when indoors). We implement and test a classifier for each modality and organize the classifiers as a parallel binary decision fusion architecture. We are able to characterize the performance of the system with respect to intruder detection time and to quantify the contribution of each modality to the overall performance.